Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Big data can unlock a wealth of insight and efficiencies around the most crucial areas of your organisation. However, you need to be very careful with the machine learning data you use, since the quality of the dataset will directly influence the success of your predictive modelling. Here’s what you need to know.
Data science and machine learning are on hand to make sense and use of your vast reams of information. However, the success of your next intelligent solution depends largely on the quality of the machine learning data. If the quality of your information isn’t up to the mark, you are likely not to obtain any reliable results from all the intelligent tools that pass through your organisation.
It’s all about data quality
Many are lead to believe that data quality should be a secondary consideration in the pursuit of machine learning, yet the figures don’t lie. IBM estimates that poor quality data costs US organisations $3.1 trillion every single year; the sum is deriving from large-scale errors and the workarounds undertaken by people in control of it.
This huge figure is made to look even more significant on the backdrop of IDC’s $136 billion valuation of the big data market. The Harvard Business Review provides a graph which sums up the domino effect of bad data quality, which goes some way to explaining how this has been allowed to happen.
The Hidden Data Factory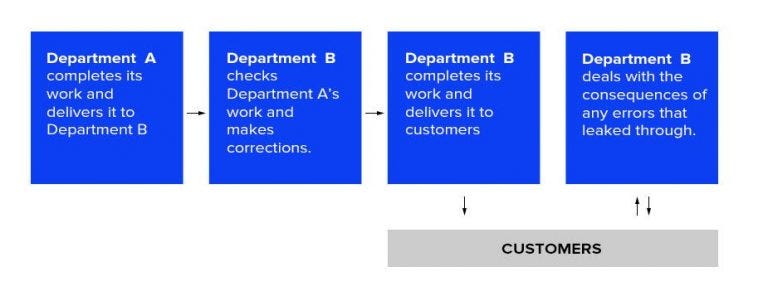
Visualising the extra steps required to correct costly and time-consuming data errors. Source: Thomas C. Redman.
Lots of reasons go into why data is found to be of poor quality. One of the more obvious is the need for companies to play the volume game, but the quality of your data should be of more importance than its quantity. ELEKS completed over 20 machine learning projects last year and around half of the cases demanded a data-cleansing effort before the modelling could start.
Use bad data and your machine-learning model will yield bad results, so any successful implementation of a machine-learning algorithm should require some form of data cleansing.
How can you tell good data from bad data?
Data quality is imperative, but how are you to know if your information really isn’t up to the required standard? Here are some of the ‘red flags’ for you to watch:
- It has missing variables and cannot be normalised to a unique basis.
- The data has been collected from lots of very different sources. Information from third parties may come under this banner.
- The data is not relevant to the subject of the algorithm. It might be useful, but not in this instance.
- The data contains contradicting values. This could see the same values for opposing classes or a very broad variation inside one class.
Upon your meeting of any one of these points, there’s a chance that your data will need to be cleaned prior to your implementation of a machine-learning algorithm.
Cleansing, rather than replacing, is likely the action you’re looking for here. Like with point three, it might be that your data is fit for use, just not for the purpose outlined. From our experience, you may need to allocate around 70–80% of your overall modelling time on things like data cleansing or the replacement of missing and contradicting data samples. Discovering poor data triggers actions like the merging of information into one database, the adding of new data or the refining of existing sources.
Conclusion
It’s possible to turn a poor database into one that’s ready for the transformation of a business. Actions like focusing on quality over volume and the uniformity of your information can go a long way to ensuring a seamless implementation of machine-learning algorithms.
The big point is to conduct this before commissioning any serious work on big data projects. In our own experience, the allocation of resource towards these actions often means that only 20–30% of our time is dedicated to actually modelling an algorithm.
Are you getting the most out of your data? Contact us to get expert assistance with your data-driven digital transformation.
Originally published at eleks.com on May 24, 2018.

How Machine Learning Data Defines the Success of Your AI Solution was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.