Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 “March calendar” by Charles Deluvio 🇵🇭🇨🇦 on Unsplash
“March calendar” by Charles Deluvio 🇵🇭🇨🇦 on Unsplash
One of the fun parts in using serverless is the fact that you can try out new ideas and provision them in a flick of a finger. I’ve mentioned more than once that s3 is a powerful tool that can be used as more than an elastic persistent layer.
In this post, I’m going to demonstrate how to use s3 as a scheduling mechanism to execute various tasks.
Overview
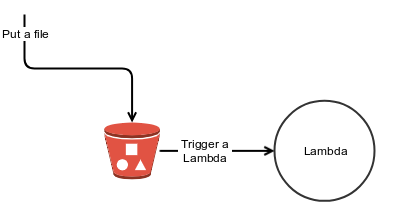 Simple S3 flow
Simple S3 flow
S3, alongside a Lambda function, creates a simple event base flow. For example, attach a Lambda to an s3 PUT event and create a new file, and the Lambda function is then called. To create a schedule event, all you have to do is to write the file you want to act upon on the designated time; however, AWS enables you to create only recurring events using cron or rate expression. What happens when you want to schedule a one-time event? You are stuck.
The s3-scheduler library enables you to do just that. Specifically, it uses s3 as a scheduling mechanism that enables you to schedule one-time events.
How it works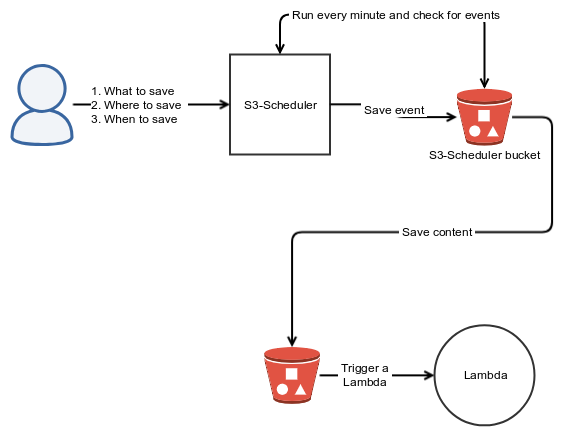
Each event is a separate file. Behind the scenes, the library uses the recurring mechanism to wake up every 1 minute, scan for the relevant files using s3’s filter capabilities, and if the scheduled time has passed, move the file to the relevant bucket + key.
In order to function properly, the library has to know the answer to three questions:
- What content to save,
- Where to save it (bucket + key) → will trigger the appropriate Lambda function, and
- When to move it to the appropriate bucket.
Encoding details
The content to save is left unchanged, and points 2 and 3 (see above) are encoded in the key’s name and use | as a separator between the parts. For example, to copy the relevant content on the 5th of August to a bucket called s3-bucket and a folder named s3_important_files, the scheduler will produce the following file: 2018–08–05|s3-bucket|s3_files-important. By keeping the meta data outside the actual content, we achieve the following benefits:
- It speeds up the process with no need to read the entire content to decide when and where to copy.
- It allows the content to be binary, not only text-based.
- By using s3 filter capabilities, it reduces the cost to fetch the correct files.
- There is easier debugging; just view the file name to understand when and where to copy.
Basic Usage
Installation
pip install s3-scheduler
Setting up a recurring flow
The library uses the AWS built-in capability to run every 1 minute. The configuration depends on your framework. For example, for Zappa use the following:
Scheduling
During initialization, the scheduler requires the bucket and a folder in which the actual scheduling details are kept. Remember that each event is a separate file; therefore, there is a need to save them somewhere. When to schedule is a simple datetime object.
Stopping
If you want to cancel the schedule event before it occurs, do the following:
Fin
Scheduling in the AWS serverless world is a bit tricky. Right now, AWS provides only cron-like capabilities, but this post has demonstrated one technique that can be used to create a more robust scheduling capability.

S3 trickery, using it as a scheduler was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.