Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

Hardware acceleration for data processing has a long history. It’s not new. When I was a child, my dad outfitted our 12 MHz 286 system with the optional 80287 Floating Point Unit (FPU) coprocessor, which ran at a whopping 4.7MHz.

The thing was a beast. It did wonders for Lotus 1–2–3.
Not long after, this specific FPU was integrated into the CPU, reducing the need for the external coprocessor for math operations. However, coprocessor actually stuck around for longer.
You know that GPU you’re using to read this article? DSPs in your mobile phone? Sound card? They’re all coprocessors, and there’s a reason they’re still around.
Your CPU can’t do everything
No, really. It can’t. The actual silicon for the Intel x86 (the heir to the 8086 and my beloved 80286) architecture is already crazy complex. Adding additional operations to the x86 architecture has diminishing returns, to the point where it may not be worth it according to Rick Merrit of the EETimes.
In fact, GlobalFoundries, one of the largest silicon chip manufacturers has announced it’s abandoning plans for 7nm chips. It’s just not worth it anymore.
 Intel Haswell-EP Xeon E5–2699 V3 Die on wccftech
Intel Haswell-EP Xeon E5–2699 V3 Die on wccftech
Why is that a problem? Well, each processor core in the x86 architecture does so many different things, that it has actually made programmers complacent. Don’t worry about writing bad software — the processor will make sure it runs fast!
Of course, Intel already knew this back in the early 2000s. They tried to kill off the x86 architecture with Itanium, a processor series designed for 64-bit computing. However, AMD had a different plan, and released 64-bit capable x86 processors, obstructing Intel’s plans. And that’s how we ended up with this mess.
Going multicore
The only way to get more oomph out of CPUs was to scale them out. That’s why today’s CPUs are almost always multi-core. They have anywhere from 2 to 28 cores for higher end server chips like the Intel Xeon series.
The clever pipelining and vectorization, caching, and some other complex systems found in the x86 architecture allow for pretty good use of the miniature electronics. Some tasks can run in groups, and the processor may even correctly predict what the next actions are, before they happen. However, as I previously mentioned — these processors are already crazy complex.
Other architectures do exist. ARM, which you can find in a huge variety of devices — from battery chargers to your phone, and even your car — has a reduced instruction set, also known as RISC.
IBM has similarly gone the RISC route. RISC processors have a much simpler core, which can’t do as much as more elaborate CPU cores. Software has to be specifically written to be multi-core to benefit from these kinds of processors.
For now, x86 has a stay of execution. It could be another 10, 15 years, but x86 will be going away.
If you’re interested in finding out more about what Intel was doing to enable parallel processing, read “The Story of ISPC”, about the Intel SPMD Program Compiler: https://pharr.org/matt/blog/2018/04/18/ispc-origins.html
Here come the GPUs and GPGPUs
Graphical Processing Units (GPUs) are also not really new. The term has been in use since 1986 at least, but tended to focus strictly on graphics. NVIDIA’s first card marketed as a “GPU” was the GeForce 256, from 2009. However, General Purpose GPUs (GPGPUs) actually started appearing around 2007, when NVIDIA and ATI (now AMD) started equipping their 3D graphics cards with more and more capabilities, like Unified Pixel Shaders. These capabilities could be repurposed to perform operations like matrix multiplications, Fast Fourier Transform, wavelet transform, and more.
 NVIDIA Tesla C870 with 128 CUDA cores (NVIDIA)
NVIDIA Tesla C870 with 128 CUDA cores (NVIDIA)
Accessing these features meant that new programming constructs had to be invented. So, in 2008, Apple started developing OpenCL. By late 2009 it was already adopted by AMD, IBM, Qualcom, Intel, and even NVIDIA. AMD decided to support OpenCL extensively, instead of their “Close to Metal” framework.
 AMD’s Radeon Pro V340, with 512GB/s of memory bandwidth. Source: AMD
AMD’s Radeon Pro V340, with 512GB/s of memory bandwidth. Source: AMD
While NVIDIA supported and still supports OpenCL, they didn’t abandon their own framework, known as CUDA. Today, CUDA is the de-facto standard for high-speed, high-throughput GPU computing. It’s essentially a software layer that gives direct access to the GPU’s virtual instruction set and parallel computational elements, for the execution of compute kernels.
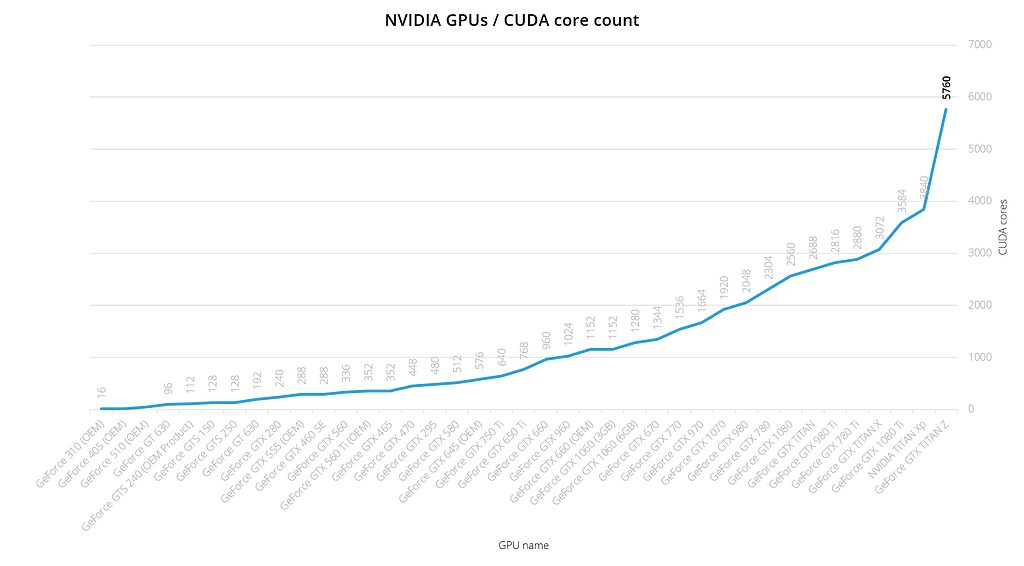 Newer NVIDIA GPUs have up to 5,760 CUDA cores
Newer NVIDIA GPUs have up to 5,760 CUDA cores
With 256 cores in 2009, and with up to 5,760 cores in a single modern GPU, I think it’s easy to see why GPUs are useful for operations that require a high degree of parallelism. But it’s not just parallelism — GPUs have extremely large memory bandwidth, which makes it suitable for high-throughput applications.
Why don’t we just replace CPUs with GPUs?
Not all applications are suitable for GPUs. GPUs are mostly useful if:
- The actions are repetitive
- The actions are mostly independant (do not rely on eachother)
- The actions are computationally intensive
GPUs have found some interesting uses outside of graphics (and cryptomining). Today, GPUs are found in a variety of data processing scenarios. They can be used as part of a data processing pipeline, for running machine learning models on, as part of a hardware accelerated relational database, or just render a result nicely.
Let’s take a look at three of the main areas where GPUs can help in the data processing pipeline:
GPUs for Stream Processing
New stream processing solutions, like FASTDATA.io’s Plasma Engine can take advantage of GPUs for stream processing data coming in and out of databases (GPU or not). This tool can be used to perform analysis and/or transformation of streaming data on the GPU.
The main competitor to FASTDATA’s engine is GPU-enabled Spark, which is available as an open-source add-on from IBM.
GPU Databases for Analytics
Practically all GPU databases are ground-up, purpose built for analytics.
 GPU Databases. Source: The 2018 Big Data Landscape
GPU Databases. Source: The 2018 Big Data Landscape
The reason for building a GPU database from scratch seems to be the difficulty in retrofitting an old, row-based database with a very different technologies.
There are several players in the GPU database field, each with their own benefits:
- MapD
- SQream DB
- BlazingDB
- Kinetica
- HeteroDB
- Brytlyt
- Blazegraph
GPUs for machine learning
Machine learning tends to be highly suitable for GPU architecture. It’s not just about the high level of parallelism, and the multitude of matrix operations. A big part of the reason is actually the aforementioned memory bandwidth.
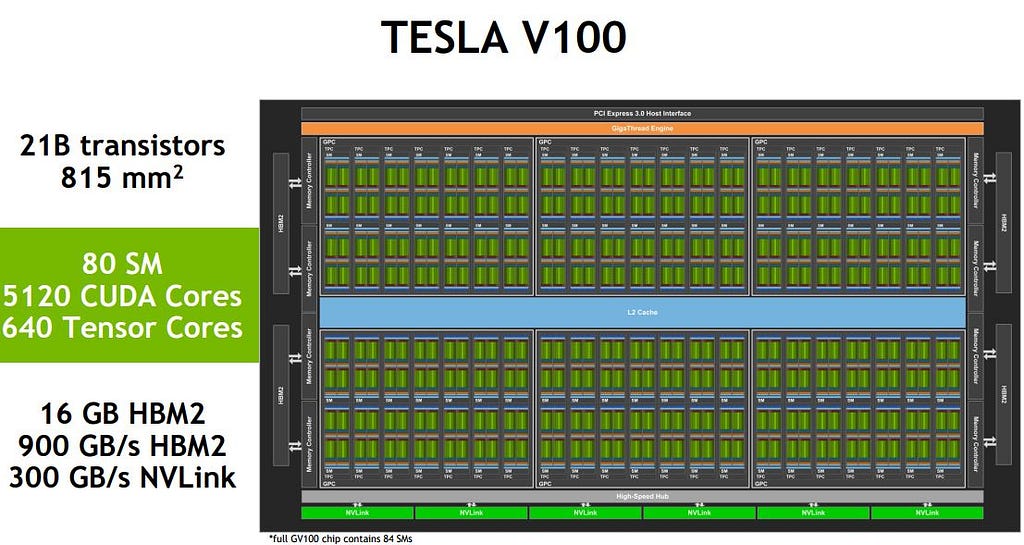 NVIDIA Tesla V100 core-arrangement. Source: ServeTheHome
NVIDIA Tesla V100 core-arrangement. Source: ServeTheHome
CPUs are what we call latency-oriented processors. Latency-oriented means that they favor lower latency of operations with clock cycles in the nanoseconds (~3 billion operations per second on one piece of data). In contrast, GPUs are throughput oriented. They will perform a single operation over lots of data at once, at a lower clock speed (~1 billion operations per second on multiple chunks of data).
GPUs sacrifice latency with a slower clock speed, in order to get a higher throughput on every clock cycle.
There is no shortage in different GPU-enabled machine learning frameworks:
- TensorFlow
- cuBLAS
- Caffe
- Theano
- Torch7
- cuDNN
- MATLAB
- cxxnet
- Deeplearning4j
- Keras
- Mathematica
and many more.
Not just GPUs — ASICs, FPGAs and other exotic hardware
While CPUs and GPUs are general purpose, we have some other alternatives in hardware, but there are trade-offs.

We’ve already discussed CPUs and GPUs, so let’s talk about FPGAs and ASICs specifically.
FPGAs
Field Programmable Gate Arrays (FPGA) are a high-speed, programmable chip. They’re extremely popular for prototyping and specialist devices. They contain an array of programmable logic blocks, and a hierarchy of reconfigurable interconnects.
Because FPGAs are programmable, they can be altered after they’ve been manufactured, but not by anyone. They provide good performance, but can cost quite a bit — which is why they remain mostly in low-yield devices. You can find FPGAs in medical equipment, cars, specialist equipment, etc.
FPGAs provide higher memory bandwidth, lower power consumption than CPUs (and GPUs), but they may struggle with floating point computations, and are hard to work with. In fact, they’re quite difficult to program for, even though recent tooling like OpenCL for FPGA exists.
In data analytics, FPGAs are suited for simple repetitive tasks. They’re found in modern platforms like Microsoft’s Project Brainwave, the Swarm64 Database Accelerator for Postgres, and devices like Ryft. One of the most well-known usage of FPGAs in analytics is IBM’s Netezza, although the FPGA aspect of Netezza was abandoned a few years ago.
Eventually, Netezza ended up as part of IBM PureData and the FPGA components were used primarily for specific operations that would benefit from FPGAs like decompression and transformations. Other operations still used the CPU.
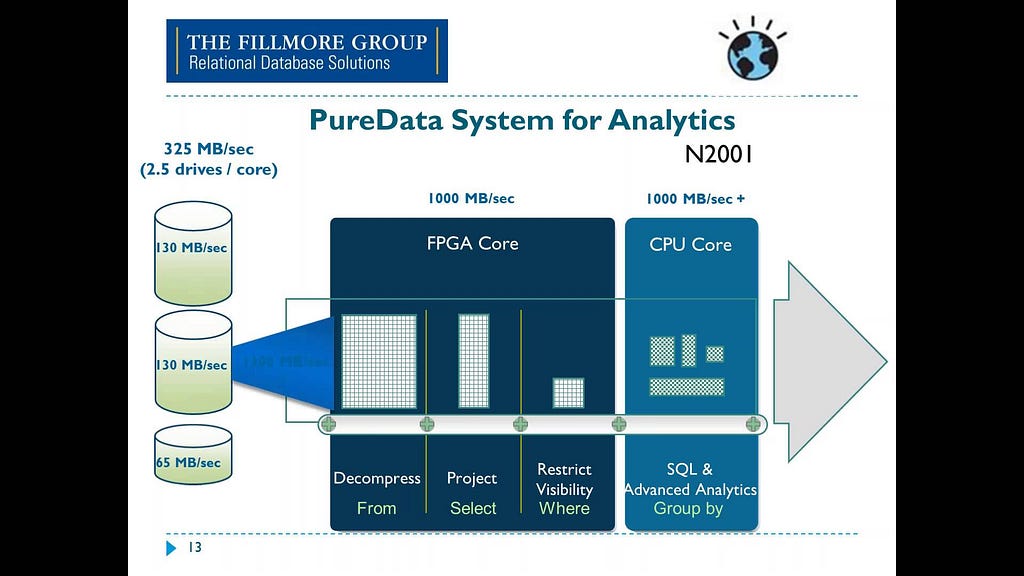 Source: IBM Data Retrieval Technologies RDBMS, BLU, IBM Netezza and HadoopASICs
Source: IBM Data Retrieval Technologies RDBMS, BLU, IBM Netezza and HadoopASICs
Custom designed Application-Specific Integrated Circuits (ASIC) are the fastest option for high-speed operations, in the silicon level. Because these chips are highly customized, they can deliver the best performance with minimal overhead.
ASICs are commonly found as digital signal processors (DSPs) — in audio processing, video encoding, and networking among others. These applications are primarily in mass-produced devices like cameras, mobile phones, wireless routers, etc.
Because of the high cost and time investment in creating custom ASICs, they are also the most costly option. They are actually the cheaper option if you plan on manufacturing millions of them, but at smaller volumes they are hard to justify. For that reason, they’re not commonly found in analytics or data processing proper.
Comparing the tradeoffs
Here’s a summary of the different processors and their tradeoffs:
 Each of the processor types has its own tradeoffs
Each of the processor types has its own tradeoffs
The future of hardware accelerated data processing
The future is in hardware diversity, but not all of the coprocessors are suitable for every task.
- The CPU’s job: Keep standard, sequential programs and code running
- The Coprocessor’s job: Run high-throughput parallel code
- CPU + Coprocessor: Increase the throughput of parallel programs
It’s clear that the x86 CPU architecture will not last forever. It simply is not sustainable for the long-run. It’s not advancing at the same rate that modern data workloads are.
Because they’re not bound to the same backwards compatibility, GPUs are advancing much faster. Modern data workloads are varied, varying, growing, and fast-moving. GPU and other hardware accelerated data processing applications are growing in popularity, with some notable successes in the machine learning space and data warehousing space.
FPGA and GPU-enabled hardware, like IBM Power9 with NVLINK and OpenCAPI, as well as Azure and AWS GPU and FPGA instances are just a sign of things to come.
Conclusion
I believe hardware accelerated data processing is still in it’s infancy, but is likely to become more widespread, as the accelerating technologies continue to make strides over today’s CPU architecture.
Thanks for reading this to the end! I know it isn’t easy — there’s a lot of information (and acronyms) to digest.
This article is the first in a series of hardware accelerated data articles. In my next article, I will deep dive into how different hardware accelerated databases utilize their respective hardware accelerators.
If you enjoyed this article, leave a comment below, or share with your friends and colleagues.

A gentle introduction to hardware accelerated data processing was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.