Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

This Tutorial shows how to generate a billing for AWS Glue ETL Job usage (simplified and assumed problem details), with the goal of learning to:
- Unittest in PySpark
- Writing Basic Function Definition and Conversion to UDF
Repository: https://gitlab.com/suekto.andreas/gluebilling
Business Problem
This tutorial shall build a simplified problem of generating billing reports for usage of AWS Glue ETL Job. (Disclaimer: all details here are merely hypothetical and mixed with assumption by author)
Let’s say as an input data is the logs records of job id being run, the start time in RFC3339, the end time in RFC3339, and the DPU it used.
The price of usage is 0.44USD per DPU-Hour, billed per second, with a 10-minute minimum for each ETL job, while crawler cost 0.20USD per DPU-Hour, billed per second with a 200s minimum for each run (once again these numbers are made up for the purpose of learning.)
Now we are going to calculate the daily billing summary for our AWS Glue ETL usage.
Prerequisite
- Install JDK 1.8, and setup the JAVA_HOME into the corresponding location (I personally using Mac, and following this link and download-link — and JAVA_HOME would be /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/)
- Python 2.7.x
- Python Coverage, unittest, and PySpark packages (Preferably installed under virtualenv)
Actually for this project I am using a bash-script builder to establish the basis of the project, it still in beta state, and this tutorial is being used to see how comfortable I am with that auto script builder. Similar result can be achieved by manually following this articles:
- https://hackernoon.com/setting-up-python-dev-in-vs-code-e84f01c1f64b
- https://medium.com/@suekto.andreas/automate-documentation-in-python-925c38eae69f
Activities
To do the above we would go along with the following pseudocode:
- Load into PySpark DataFrame
- Calculate the duration in seconds out of the from and to unix timestamp
- Calculate the fee per records
001 — Calculate Duration (+ unit test)
First let’s build the calculate duration function. The following is the module directory structure that we are going to use :
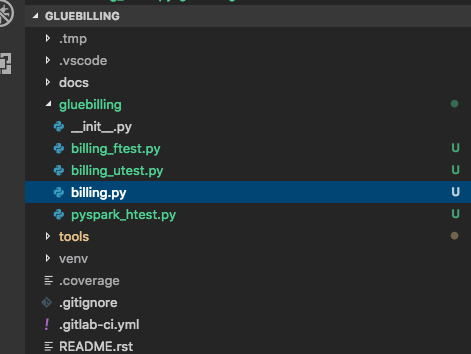 module gluebilling — billing.py
module gluebilling — billing.py
All files *.py are started with empty files, the __init__.py is to indicate that we define gluebilling as a python module.
let’s start with writing the function skeleton in billing.py.
"""Process records of ETL Job usage into the billing of fee"""from datetime import datetime as dt
def calculate_duration(from_timestamp, to_timestamp): """Returns duration in second between two time return 0
Based on the skeleton, we already have a clearer though of how it should be called and what kind of value shall it returns, now let us create the unit test for this function, to define in more details the behaviour of it. This is written in billing_utest.py
"""Unit Testing for Glue Billing Project"""import unittest
import gluebilling.billing as billing
class CalculateDurationTest(unittest.TestCase): """Test Cases for Glue Billing Unit Testing"""
def test_positive_duration(self): """Test successfully calculate duration between 2 unix timestamp string""" duration = billing.calculate_duration( "1535824800", "1535835600") self.assertEqual(duration, 10800)
def test_negative_duration(self): """Test successfully generate negative number""" duration = billing.calculate_duration( "1535835600", "1535824800") self.assertEqual(duration, -10800)
In writing a unit testing, we import the unittest module, and the module of which we want to test (gluebilling.billing) module.
Next we define the class to host the test cases (CalculateDurationTest) extending the base class (unittest.TestCase)
Afterward within the CalculateDurationTest, we define the list of test cases in a object method format prefix with `test_`. We put in the input arguments, execute the function we want to test, and finally check the result using the assertEqual function coming from unittest.TestCase.
if we run the unittest now it should be failing
$ coverage run --source=gluebilling -m unittest discover -p "*utest*.py" -f -s gluebilling/
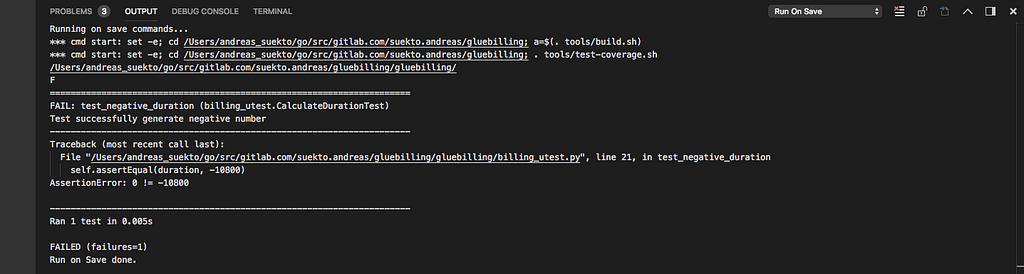 coverage with unittest result
coverage with unittest result
Now after having the red state, let us start implementing the function
"""Process records of ETL Job usage into the billing of fee"""from datetime import datetime as dt
def calculate_duration(from_timestamp, to_timestamp): """Returns duration in second between two time provided in unix timestamp""" from_dt = dt.fromtimestamp(float(from_timestamp)) to_dt = dt.fromtimestamp(float(to_timestamp))
time_delta = to_dt - from_dt return time_delta.total_seconds()
Now we shall have all test cases in green state
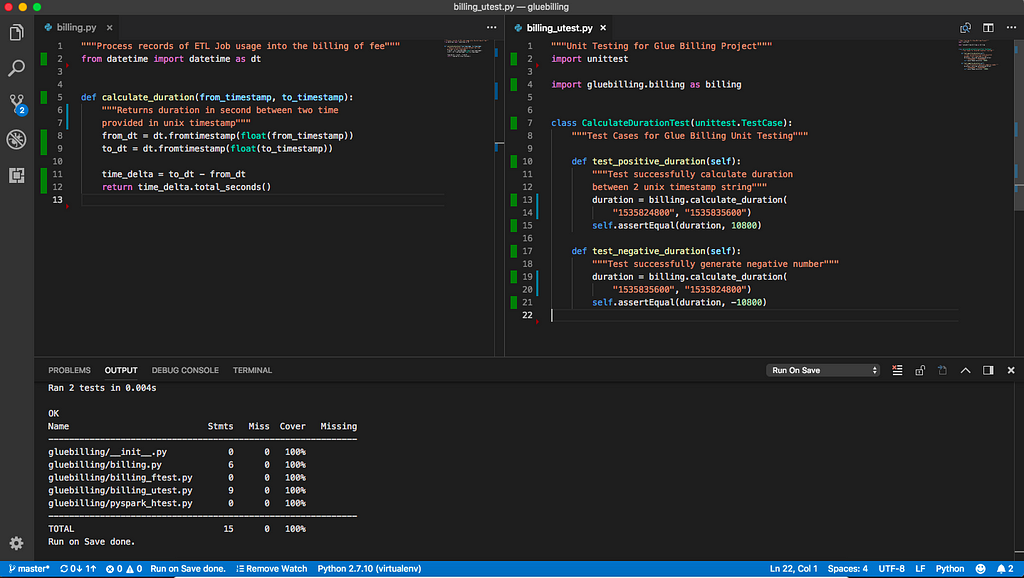 calculate_duration implementation completed !
calculate_duration implementation completed !
Noticed that the screenshot above is a development environment setup with automated run of testing and coverage calculation, based on https://hackernoon.com/setting-up-python-dev-in-vs-code-e84f01c1f64b
002 — Calculate Fee (+ unit test)
Following up the same technique above we are adding the calculate fee function as below :
in billing.py
"""Process records of ETL Job usage into the billing of fee"""from datetime import datetime as dtfrom decimal import Decimal
...
def calculate_fee(duration_in_second, dpu_num, minimum_duration, fee_dpu_hour): """Returns a decimal of the fee incurred in USD, quantized into 8 digit behind comma"""
charged_duration = duration_in_second if charged_duration < minimum_duration: charged_duration = minimum_duration
fee = charged_duration * dpu_num * Decimal(fee_dpu_hour) / 3600 return fee.quantize(Decimal('0.00000000'))in billing_utest.py we shall add another class to host test cases for calculate_fee.
"""Unit Testing for Glue Billing Project"""import unittestfrom decimal import Decimal
import gluebilling.billing as billing
...
class CalculateFeeTest(unittest.TestCase): """Unit Test for calculate_fee function"""
def test_more_than_10_min(self): """When usage is more than 10 min""" fee = billing.calculate_fee(800, 3, 600, "0.44") self.assertEqual(fee, Decimal("0.29333333"))Noticed that the dpu_hour value is set as string “0.44” instead of float, as this is the more accurate result of calculation if we further convert it into Decimal type.
The reason why I separate the test cases for the 2 functions into different classes because the pylint C0103 snake case requires the length of function capped into 30 characters, so to maintain readability we divide it into different classes for each function to test.
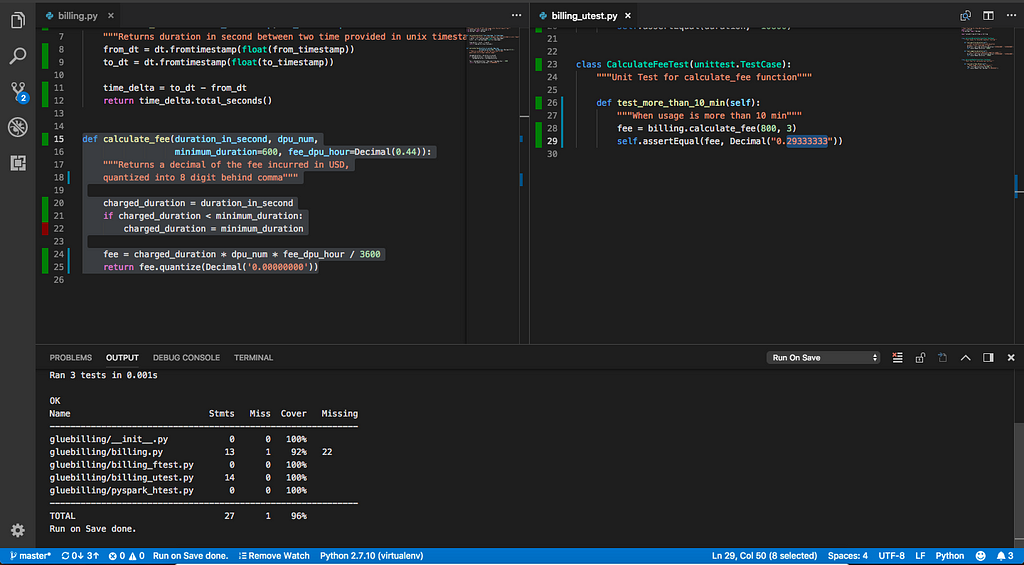 The coverage test result after implementing calculate_fee, notice that the coverage can be done better, it is left for the reader to exercise (see the red colour bar)003 — PySpark Billing Calculation (+ functional test)
The coverage test result after implementing calculate_fee, notice that the coverage can be done better, it is left for the reader to exercise (see the red colour bar)003 — PySpark Billing Calculation (+ functional test)
This article is using similar basic concept from tutorial from David Illes, the differences would be in the details where we focus our setup to be completely standalone (this shall be reflected in how we initialised the Spark Session, and how we prepare the test data)
Here is the version that we are going to use, we store it as pyspark_htest.py
"""PySparkTest is base class to do functional testing on PySpark"""import unittestimport loggingimport osfrom pyspark.sql import SparkSessionfrom pandas.testing import assert_frame_equal
class PySparkTest(unittest.TestCase): """BaseClass which setup local PySpark"""
@classmethod def suppress_py4j_logging(cls): """Supress the logging level into WARN and above""" logger = logging.getLogger('py4j') logger.setLevel(logging.WARN) @classmethod def create_testing_pyspark_session(cls): """Returns SparkSession connecting to local context the extrajava session is to generate the metastore_db and derby.log into .tmp/ directory""" tmp_dir = os.path.abspath(".tmp/") return (SparkSession.builder .master('local[1]') .appName('local-testing-pyspark-context') .config("spark.driver.extraJavaOptions", "-Dderby.system.home="+tmp_dir) .config("spark.sql.warehouse.dir", tmp_dir) .getOrCreate())@classmethod def setUpClass(cls): """Setup the Spark""" cls.suppress_py4j_logging() cls.spark = cls.create_testing_pyspark_session()
@classmethod def tearDownClass(cls): """Clean up the Class""" cls.spark.stop()
@classmethod def assert_dataframe_equal(cls, actual, expected, keycolumns): """Helper function to compare small dataframe""" exp_pd = expected.toPandas().sort_values( by=keycolumns ).reset_index(drop=True) act_pd = actual.toPandas().sort_values( by=keycolumns ).reset_index(drop=True) return assert_frame_equal(act_pd, exp_pd)
Noticed that this base class providing many useful class methods with the goal of :
- suppressing any logging into WARN only (PySpark using py4j for logging)
- building Spark Session in localhost with 1 core, and setting up the temporary metastore_db to be tidied up stored in .tmp/ directory, alongside with the derby.log (Just so that our workspace is tidy and clean) — create_testing_pyspark_session
- The setUpClass and tearDownClass is automatically called once.
- assert_dataframe_equal — receiving PySpark Dataframe, and then converting them all into Pandas, sorting it by the keys (because PySpark results does not maintain the order) then we use Pandas testing to compare the two dataframe.
Let’s create the skeleton of the function (billing.py) alongside with the expected Schema definition of our input records and targetted output, the billing records.
def get_usage_record_schema(): """Retruns StructType containing the Input Usage Data Expected Schema""" return StructType([ StructField("job_id", StringType(), False), StructField("type", StringType(), False), StructField("dpu", IntegerType(), False), StructField("from_unix_timestamp", StringType(), False), StructField("to_unix_timestamp", StringType(), False) ])def get_pricing_schema(): """Retruns StructType containing the Input Pricing Data Expected Schema""" return StructType([ StructField("type", StringType(), False), StructField("dpu_hour", StringType(), False), StructField("minimum_duration", IntegerType(), False) ])def get_billing_schema(): """Retruns StructType containing the Billing Schema""" return StructType([ StructField("job_id", StringType(), False), StructField("type", StringType(), False), StructField("dpu", IntegerType(), False), StructField("from_unix_timestamp", StringType(), False), StructField("to_unix_timestamp", StringType(), False), StructField("dpu_hour", StringType(), False), StructField("minimum_duration", IntegerType(), False), StructField("duration", IntegerType(), False), StructField("fee", DecimalType(20, 8), False), ])def generate_billing(usage_df, pricing_df): """Returns DataFrame of Fee from a DataFrame of Usage Records""" return None
Next we go into the billing_ftest.py to prepare for our functional testing.
"""Functional Testing for Glue Billing Project"""from decimal import Decimalfrom pyspark.sql import Row, SQLContext
import gluebilling.billing as billingimport gluebilling.pyspark_htest as pysparktest
class GenerateBillingTest(pysparktest.PySparkTest): """Test Cases for Generate Billing"""
def generate_usage_data_001(self): """Generate usage data for testing it is a record of AWS Glue ETL usage""" rdd = self.spark.sparkContext.parallelize([ Row("JOB001", "etl", 3, "1535824800", "1535835600"), Row("JOB002", "crawler", 3, "1535824800", "1535824850"), Row("JOB003", "crawler", 3, "1535824800", "1535835600") ]) schema = billing.get_usage_record_schema()sqlctx = SQLContext(self.spark.sparkContext) return sqlctx.createDataFrame(rdd, schema)
def generate_pricing_data_001(self): """Generate pricing data for testing it is a record of AWS Glue ETL usage""" rdd = self.spark.sparkContext.parallelize([ Row("etl", "0.44", 600), Row("crawler", "0.20", 200) ]) schema = billing.get_pricing_schema()sqlctx = SQLContext(self.spark.sparkContext) return sqlctx.createDataFrame(rdd, schema)
def generate_expected_billing_001(self): """Generate expected billing""" rdd = self.spark.sparkContext.parallelize([ Row("JOB001", "etl", 3, "1535824800", "1535835600", "0.44", 600, 10800, Decimal("3.96")), Row("JOB002", "crawler", 3, "1535824800", "1535824850", "0.20", 200, 50, Decimal("0.03333333")), Row("JOB003", "crawler", 3, "1535824800", "1535835600", "0.20", 200, 10800, Decimal("1.80")) ]) schema = billing.get_billing_schema()sqlctx = SQLContext(self.spark.sparkContext) return sqlctx.createDataFrame(rdd, schema)
def test_with_set_001(self): """Using all 001 test data set""" usage_df = self.generate_usage_data_001() pricing_df = self.generate_pricing_data_001() expected = self.generate_expected_billing_001()
actual = billing.generate_billing(usage_df, pricing_df)
self.assert_dataframe_equal(actual, expected, ["job_id"])
We prepare our input data in two function:1. generate_usage_data_0012. generate_pricing_data_001The technique being used here is by creating rdd using Row and paralellize method of SparkContext, and then combining with the defined Schema from the main script.
We also prepare the expected output data inside billing_ftest.py, in function generate_expected_billing_001, with similar technique as we prepare the input data.
The last component of billing_ftest.py is test_with_set_001, which is where the test being executed by combining the generation functions of input, and expected dataframe, and then we execute the main script function generate_billing, finally we do asssertion, by leveraging the helper assert method we define in pyspark_htest.py.
Finally let’s complete the function implementation in billing.py.
def generate_billing(usage_df, pricing_df): """Returns DataFrame of Fee from a DataFrame of Usage Records"""
duration_udf = udf(calculate_duration, IntegerType())
join_data_df = usage_df.join( pricing_df, usage_df.type == pricing_df.type ).select( usage_df.job_id, usage_df.type, usage_df.dpu, usage_df.from_unix_timestamp, usage_df.to_unix_timestamp, pricing_df.dpu_hour, pricing_df.minimum_duration, duration_udf( usage_df.from_unix_timestamp, usage_df.to_unix_timestamp).alias("duration") )fee_udf = udf(calculate_fee, DecimalType(20, 8))
billing_df = join_data_df.select( "job_id", "type", "dpu", "from_unix_timestamp", "to_unix_timestamp", "dpu_hour", "minimum_duration", "duration", fee_udf( join_data_df.duration, join_data_df.dpu, join_data_df.minimum_duration, join_data_df.dpu_hour ).alias("fee") )return billing_df
We are wrapping our calculate_fee and calculate_duration function into udf, as this is the the type that can be passed into pyspark. The 1st argument is the function to be wrapped, while the 2nd argument is the expected return type.
Then we use this in the SELECT part of the PySpark SQL DataFrame to generate the 2 new columns duration and fee accordingly.
Conclusion
That’s it now we have implemented the functional test, I differentiate this with the calculate_fee and calculate_duration because of the speed on how this test being executed, it requires several seconds to start up the pyspark hence its worthed to be group differently.
This open up options for us to filter out what kind of test do we want to run on save (in case we are automating the development experience)

Tutorial : AWS Glue Billing report with PySpark with Unittest was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.