Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
As I see our customers fall in love with Big Query ML, an old problem rises its head — I find that they can not resist the temptation to assign meaning to feature weights.
“The largest weight in my model to predict customer lifetime value,” they might remark, “is whether or not the customer received a thank you call from an executive.” Or they might look at negative weights and draw a dire conclusion: “Stores located in urban areas lead to negative satisfaction scores.”
Please don’t do that. Don’t make your execs call every customer! Don’t close all your urban locations!
 Don’t make decisions based on the weights of your machine learning model
Don’t make decisions based on the weights of your machine learning model
Do not make decisions based on the weights of your machine learning model. Why not?
Categorical weights are free parameters
Let’s take a simple example. Let’s say that you want to create a model to predict the weight of a coin. There will be three inputs to your machine learning model — the diameter of the coin, the thickness of the coin, and the material that the coin is made of.

Perhaps after training the model on your large dataset of coins, you end up with this model:
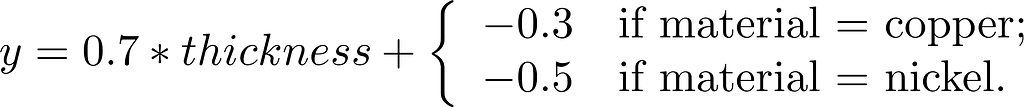 Model to predict the weight of a model
Model to predict the weight of a model
The negative terms for the material do not mean anything. For example, we can move part of the weight into the “bias” term and create an equivalent model:
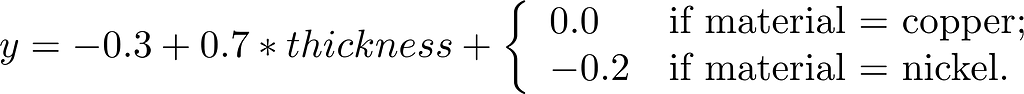 This model is equivalent to the one above
This model is equivalent to the one above
Categorical variables, in other words, provide a lot of leeway in how the model can assign its weights. It’s literally random.
Dependent variables also provide free parameters
Suppose it turns out that, in your real-world dataset, larger coins are also thicker. Then, your model might just as well as be:
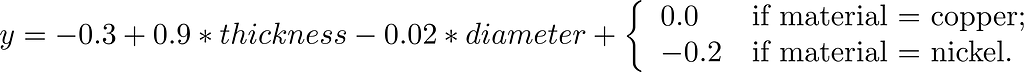
So, now the weight of the diameter feature is negative because it is essentially canceling out the extra positive weight given to the thickness.
Obviously, larger coins will weigh more, but because they are also thicker in the real-world from where our dataset was collected, the individual feature weights won’t reflect this.
Just don’t do it
The bottomline is that you can not draw conclusions from the magnitude of the weights or the sign of the weights. As humans, we want explainability, but in real-world datasets, this can be quite hard.
Methods like permuting inputs, LIME and Integrated Gradients help somewhat, but unless you also have a clear idea of inter-feature dependencies, it is dangerous to make expensive decisions based on even these more sophisticated methods. Feature importance is the importance within the specific model, and often does not translate to importance in real-life.
Really, just don’t
Models to predict lifetime value or customer satisfaction are fine — you can definitely use those models to determine which customers to coddle and which transactions to investigate. That’s because the model was trained on a large dataset to predict exactly that.
However, the weights associated with individual features are not interpretable. The input feature magnitudes (“executive sales calls have a huge weight”) or feature sign (“urban stores lead to poor satisfaction”) should not be used to derive conclusions. You shouldn’t use a model that predicts lifetime value to mandate that every customer needs to receive a personalized note from an executive.

Why feature weights in a machine learning model are meaningless was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.