Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Photo by thomas kvistholt on Unsplash
Photo by thomas kvistholt on Unsplash
Hello! We will be looking at the effects of redis on the performance of our API server. Redis (Remote dictionary server) can be used as a database, a cache and several other things. For this project, we will be using Redis for caching.
Why do we need to cache ?
- It helps us reduce the overhead due to the amount of API requests and responses the server has to handle.
- The users request or the servers response will be served quicker, due to reduced latency.
Redis basically will help us cache data, and afterwards serve the data when that particular request is made.
For example, If we are working with a server that allows users sign up and then shop on the site, we know that the “shopping data”(adding items to the cart, adding money to the wallet, removing items from the cart, paying for orders using different gateways etc.) is much more dynamic compared to the profile of the user, which was formed using the information upon signup. The “signup data”(user’s name, user’s address, user’s mail etc.) is less likely to change and this kind of data can be stored in the cache and then periodically the cache can be updated or refreshed. This will help increase time efficiency. If a server attempts accessing the network(Internet) by querying a db or an API, is much more CPU intensive than accessing the L1 cache or the RAM. This means it will be much more efficient to access the cache, than to keep querying a db.
Create the Server
The stack for implementing this server will be:
- Node JS + Express
- PostgreSQL (Database)
- Redis (Cache)
Firstly, we download the PostgreSQL installer, which comes with psql(SQL shell) and pgAdmin(Make sure to take note of the ‘user’,‘password’ and ‘port’ during installation). To be clear, I am using the windows OS for this project.
 A snippet of the pgAdmin home page.
A snippet of the pgAdmin home page.
We can create a database for ourselves, we just have to open the pgAdmin application which runs in the browser and then click on ‘Servers/postgreSQL/Databases’, then right-click on ‘Databases’ and then ‘create’ to make a new one. For this project, the name is ‘users’.
We can then create a table by clicking on ‘users/Schemas/Tables’ and then right-click and then ‘create’ to make a new one. The name of this table is ‘data’.
We can now create our folder using the express generator.
express myapi
The ‘myapi’ folder should have all these files in it, and lets do well to ensure our routes are working fine.
index.js
This file just creates the routes for our basic CRUD application and includes the crudController, which has functions to handle all the routes.
crud-controllers.js
Firstly, we need to install some packages.
npm install --save redis response-time pg-promise
This file just creates the redis client, and then sets the ‘initialization options’ for connecting to the postgreSQL db.
To connect to the db, we need to get the URL for the db, which is usually in this form:
postgresql://[user[:password]@][netloc][:port][/dbname]
By default:
- user : postgres
- netloc : localhost
- port : 5432
- dbname : The name of our db is users
- Then you can input the password you set upon installation.
We installed ‘pg-promise’ which helps us work with our postgreSQL using promises and the ‘initializationOptions’ help us check for errors.
Then we connect to our db using the ‘connectionString’. If everything was done correctly, we should see “success!!!” in our terminal when we start the server.
Finally, we will be using the redis client on the ‘/get/:id’ route which is controlled by ‘crudController.getSingle’. We can see this route on our index.js file.
Firstly, in the getSingle function we get the id of the user. Since redis works based on keys and values, we set keys and get values.
So we check if we can get any value from the user’s ID, if there is a result, we send a response saying the data was gotten from the redis-cache. If there was no result, we query the db and then when the result is gotten we now store it in our cache.
This will surely happen during every new request, then after the first request the data will be saved. We used setex so that we can set the key which is the userID, and also the expiry time which is 60 seconds. So setex is a combination of SET and EXPIRY and then lastly we added the data as the value. So 60 seconds is the TTL(Time to live) for this key-value pair.
Now, we can check the time it took for the API server to query the db, and then how long it took to get the data from the cache.
We need to add the response-time package to the app.js file
//At the topvar responseTime = require('response-time');...//Above the routesapp.use(responseTime());The response-time package adds a ‘X-Response-Time’ key to our header and shows us the time taken.
Now, we can go and add data to our table ‘data’, so that we can have data to play with.
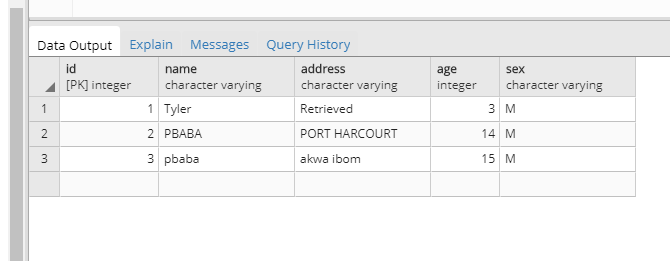 A snippet of the DB.
A snippet of the DB.
So let us start up our server using npm start and then go to our browser, and type in the URL “localhost:get/2” since we have items with ids 1,2 and 3.
Then we can open up the chrome developer tools, go to the network and click on the id.
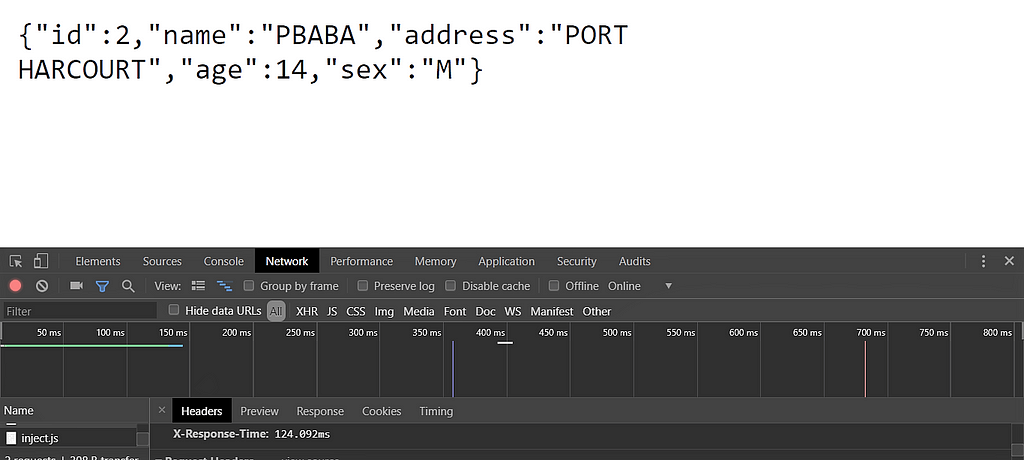 Response from DB
Response from DB
So since this is the first request, it wasn’t in the cache and then the db was queried directly. At the bottom of the screen, we can see the X-Response-Time to be 124.092ms.
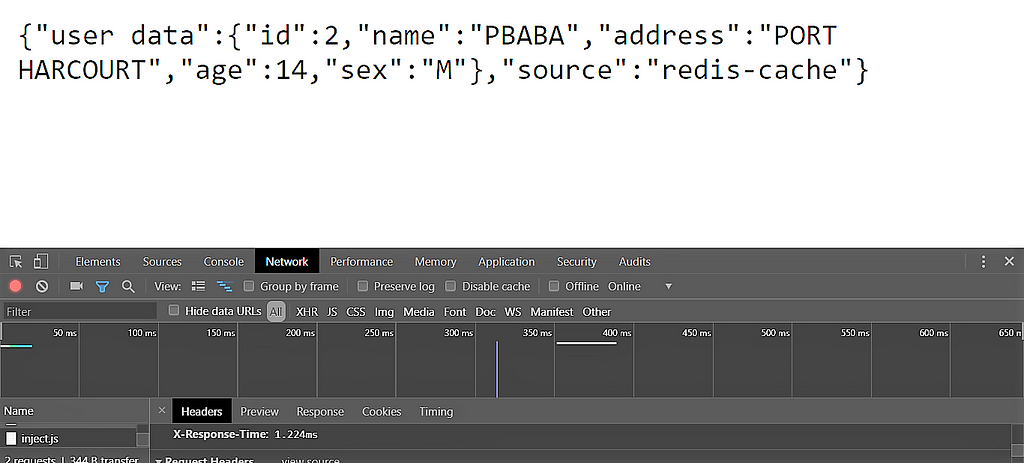 Response from cache
Response from cache
From the response, we can see the source is the redis-cache and the X-Response-Time is 1.224ms.
So, we can see caching is much more effective, especially when we have many more users and when the db is no longer hosted locally.
Thank you very much for reading!

Effects of Redis on an API Server was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.