Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Reducing memory allocations from 7.5GB to 32KB
Contents
- Context of the problem
- Establishing a baseline
- Easy win 1
- Easy win 2
- Splits are never cool
- Lists are not always nice
- Pooling byte arrays
- Goodbye StringBuilder
- Skipping commas
- The war between classes and structs
- Goodbye StreamReader
- TLDR — Give me a table
Context of the problem
Codeweavers is a financial services software company, part of what we do is to enable our customers to bulk import their data into our platform. For our services we require up-to-date information from all our clients, which includes lenders and manufacturers across the UK. Each of those imports can contain several hundred megabytes uncompressed data, which will often be imported on a daily basis.
This data is then used to power our real-time calculations. Currently this import process has to take place outside of business hours because of the impact it has on memory usage.
In this article we will explore potential optimisations to the import process specifically within the context of reducing memory during the import process. If you want to have a go yourself, you can use this code to generate a sample input file and you can find all of the code talked about here.
Establishing a baseline
The current implementation uses StreamReader and passes each line to the lineParser.
The most naive implementation of a line parser that we originally had looked something like this:-
The ValueHolder class is used later on in the import process to insert information into the database:-
Running this example as a command line application and enabling monitoring:-
Our main goal today is to reduce allocated memory. In short, the less memory we allocate, the less work the garbage collector has to do. There are three generations that garbage collector operates against, we will also be monitoring those. Garbage collection is a complex topic and outside of the scope of this article; but a good rule of thumb is that short-lived objects should never be promoted past generation 0.
We can see V01 has the following statistics:-
Took: 8,750 msAllocated: 7,412,303 kbPeak Working Set: 16,720 kbGen 0 collections: 1809Gen 1 collections: 0Gen 2 collections: 0
Almost 7.5 GB of memory allocations to parse a three hundred megabyte file is less than ideal. Now that we have established the baseline, let us find some easy wins…
Easy win 1
Eagle-eyed readers will have spotted that we string.Split(',') twice; once in the line parser and again in the constructor of ValueHolder. This is wasteful, we can overload the constructor of ValueHolder to accept a string[] array and split the line once in the parser. After that simple change the statistics for V02 are now:-
Took: 6,922 msAllocated: 4,288,289 kbPeak Working Set: 16,716 kbGen 0 collections: 1046Gen 1 collections: 0Gen 2 collections: 0
Great! We are down from 7.5GB to 4.2GB. But that is still a lot of memory allocations for processing a three hundred megabyte file.
Easy win 2
Quick analysis of the input file reveals that there are 10,047,435 lines, we are only interested in lines that are prefixed with MNO of which there are 10,036,466 lines. That means we are unnecessarily processing an additional 10,969 lines. A quick change to V03 to only parse lines prefixed with MNO:-
This means we defer splitting the entire line until we know it is a line we are interested in. Unfortunately this did not save us much memory. Mainly because we are interested in 99.89% of the lines in the file. The statistics for V03:-
Took: 8,375 msAllocated: 4,284,873 kbPeak Working Set: 16,744 kbGen 0 collections: 1046Gen 1 collections: 0Gen 2 collections: 0
It is time to break out the trusty profiler, in this case dotTrace:-
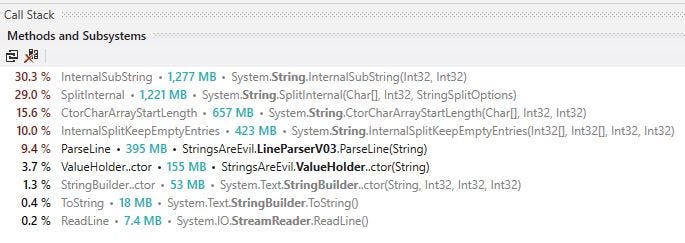
Strings in the .NET ecosystem are immutable. Meaning that anything we do to a string always returns a brand new copy. Therefore calling string.Split(',') on every line (remember there are 10,036,466 lines we are interested in) returns that line split into several smaller strings. Each line at minimum has five sections we want to process. That means in the lifetime of the import process we create at least 50,182,330 strings..! Next we will explore what we can do to eliminate the use of string.Split(',').
Splits are never cool
A typical line we are interested in looks something like this:-
MNO,3,813496,36,30000,78.19,,
Calling string.Split(',') on the above line will return a string[] containing:-
'MNO''3''813496''36''30000''78.19'''''
Now at this point we can make some guarantees about the file we are importing:-
- The length of each line is not fixed
- The number of sections that are delimited by a comma are fixed
- We only use the first three characters of each line to determine our interest in the line
- This means there are five sections we are interested in but the section length is unknown
- Sections do not change locations (e.g MNO is always the first section)
Guarantees established, we can now build a short lived index of the positions of all the commas for a given line:-
Once we know the position of each comma, we can directly access the section we care about and manually parse that section.
Putting it all together:-
Running V04 reveals this statistics:-
Took: 9,813 msAllocated: 6,727,664 kbPeak Working Set: 16,872 kbGen 0 collections: 1642Gen 1 collections: 0Gen 2 collections: 0
Whoops, that is worse than expected. It is an easy mistake to make but dotTrace can help us here…
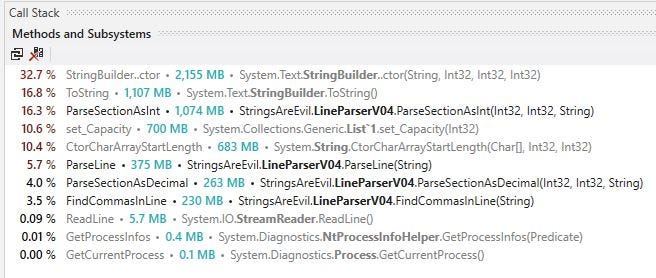
Constructing a StringBuilder for every section in every line is incredibly expensive. Luckily it is a quick fix, we constructor a single StringBuilder on the construction of V05 and clear it before each usage. V05 now has the following statistics:-
Took: 9,125 msAllocated: 3,199,195 kbPeak Working Set: 16,636 kbGen 0 collections: 781Gen 1 collections: 0Gen 2 collections: 0
Phew we are back on the downwards trends. We started at 7.5GB and now we are down to 3.2GB.
Lists are not always nice
At this point dotTrace becomes an essential part of the optimisation process. Looking at V05 dotTrace output:-
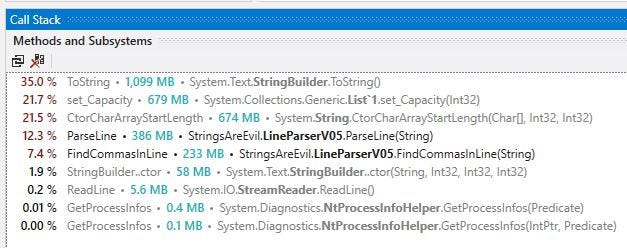
Building the short lived index of commas positions is expensive. As underneath any List<T> is just a standard T[] array. The framework takes care of re-sizing the underlying array when elements are added. This is useful and very handy in typical scenarios. However, we know that there are six sections we need to process (but we are only interested in five of those sections), ergo there are at least seven commas we want indexes for. We can optimise for that:-
V06 statistics:-
Took: 8,047 msAllocated: 2,650,318 kbPeak Working Set: 16,560 kbGen 0 collections: 647Gen 1 collections: 0Gen 2 collections: 0
2.6GB is pretty good, but what happens if we force the compiler to use byte for this method instead of the compiler defaulting to use int:-
Re-running V06:-
Took: 8,078 msAllocated: 2,454,297 kbPeak Working Set: 16,548 kbGen 0 collections: 599Gen 1 collections: 0Gen 2 collections: 0
2.6GB was pretty good, 2.4GB is even better. This is because an int has a much larger range than a byte.
Pooling byte arrays
V06 now has a byte[] array that holds the index of each comma for each line. It is a short lived array, but it is created many times. We can eliminate the cost of creating a new byte[] for each line by using a recent addition to the .NET ecosystem; Systems.Buffers. Adam Sitnik has a great breakdown on using it and why you should. The important thing to remember when using ArrayPool<T>.Shared is you must always return the rented buffer after you are done using it otherwise you will introduce a memory leak into your application.
This is what V07 looks like:-
And V07 has the following statistics:-
Took: 8,891 msAllocated: 2,258,272 kbPeak Working Set: 16,752 kbGen 0 collections: 551Gen 1 collections: 0Gen 2 collections: 0
Down to 2.2GB, having started at 7.5GB. It is pretty good, but we are not done yet.
Goodbye StringBuilder
Profiling V07 reveals the next problem:-
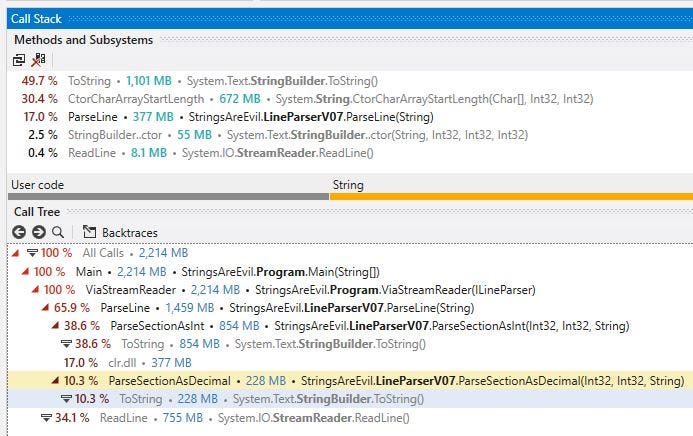
Calling StringBuilder.ToString() inside of the decimal and int parsers is incredibly expensive. It is time to deprecate StringBuilder and write our own¹ int and decimal parsers without relying on strings and calling int.parse() / decimal.parse(). According to the profiler this should shave off around 1GB. After writing our own int and decimal parsers V08 now clocks in at:-
Took: 6,047 msAllocated: 1,160,856 kbPeak Working Set: 16,816 kbGen 0 collections: 283Gen 1 collections: 0Gen 2 collections: 0
1.1GB is a huge improvement from where we were last (2.2GB) and even better than the baseline (7.5GB).
¹ Code can be found here
Skipping commas
Until V08 our strategy has been to find the index of every comma on each line and then use that information to create a sub-string which is then parsed by calling int.parse() / decimal.parse(). V08 deprecates the use of sub-strings but still uses the short lived index of comma positions.
An alternative strategy would be to skip to the section we are interested in by counting the number of preceding commas then parse anything after the required number of commas and return when we hit the next comma.
We have previously guaranteed that:-
- Each section is preceded by a comma.
- And that the location of each section within a line does not change.
This would also means we can deprecate the rented byte[] array because we are no longer building a short lived index:-
Unfortunately V09 does not save us any memory, it does however reduce the time taken:-
Took: 5,703 msAllocated: 1,160,856 kbPeak Working Set: 16,572 kbGen 0 collections: 283Gen 1 collections: 0Gen 2 collections: 0
Another benefit of V09 is that it reads much more closer to the original implementation.
The war between classes and structs
This blog post is not going to cover the difference or the pros/cons of classes vs structs. That topic has been covered many times. In this particular context, it is beneficial to use a struct. Changing ValueHolder to a struct in V10 has the following statistics:-
Took: 5,594 msAllocated: 768,803 kbPeak Working Set: 16,512 kbGen 0 collections: 187Gen 1 collections: 0Gen 2 collections: 0
Finally, we are below the 1GB barrier. Also, word of warning please do not use a struct blindly, always test your code and make sure the use case is correct.
Goodbye StreamReader
As of V10 the line parser itself is virtually allocation free. dotTrace reveals where the remaining allocations occur:-
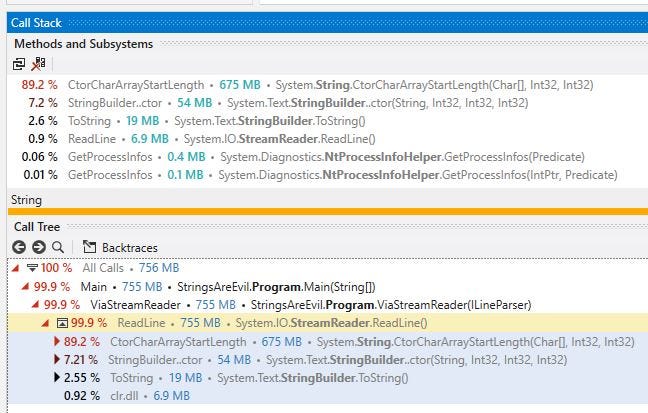
Well this is awkward, the framework is costing us memory allocations. We can interact with the file at a lower-level than a StreamReader:-
V11 statistics:-
Took: 5,594 msAllocated: 695,545 kbPeak Working Set: 16,452 kbGen 0 collections: 169Gen 1 collections: 0Gen 2 collections: 0
Well, 695MB is still better than 768MB. Okay, that was not the improvement I was expecting (and rather anti-climatic). Until, we remember we have previously seen and solved this problem before. In V07 we used ArrayPool<T>.Shared to prevent lots of small byte[]. We can do the same here:-
The final version of V11 has the following statistics:-
Took: 6,781 msAllocated: 32 kbPeak Working Set: 12,620 kbGen 0 collections: 0Gen 1 collections: 0Gen 2 collections: 0
Yes, only 32kb of memory allocations. That is the climax I was looking for.
TLDR — Give me a table

Strings Are Evil was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.