Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
The Alibaba tech team explored a new approach to voice recognition on mobile, addressing main challenges in this field

Voice biometrics, or voiceprints, are already used by banks such as Barclays and HSBC to verify customer identity. As the technology improves, it will likely find further applications within banking and security. Speaker recognition may also find applications within surveillance criminal investigations.
Despite these potential of the technology, there are still many challenges to overcome in the field. Currently most speaker recognition takes place on the server side. The Alibaba tech team proposes a solution using TensorFlow Lite on the client side, to address many of the common issues with the current model through machine learning and other optimization measures.
Issues with a Server-side Model:
With most speaker recognition currently taking place on the server side, the following issues are all too common:
· Poor network connectivity
· Extended latency
· Poor user experience
· Over-extended server resources
Alibaba’s Client-side Alternative:
To address these issues, the Alibaba tech team decided to implement speaker recognition on the client side, and to use machine learning to optimize speaker recognition.
This solution came with its own fair share of challenges. Implementing speaker recognition on the client side is time-consuming, and multiple optimizations are needed in order to offset this. The Alibaba tech team devised ways to:
· Optimize results with machine learning
· Accelerate computation
· Reduce time-consuming operations
· Reduce preprocessing time
· Filter out non-essential audio samples
· Remove unnecessary computing operations
The methods proposed by the Alibaba tech team make up a set of solutions which can help to address the challenges encountered by speaker recognition technology.
Defining Speaker Recognition
Scenarios
Voice recognition can be usefully applied in many scenarios, including:
1) Media quality analysis: recognize human voices, silence in call, and background noises.
2) Speaker recognition: verify a voice for phone voice unlock, remote voice identification, etc.
3) Mood recognition: identify the speakers mood and emotional state. When combined with a person’s voiceprint, the content of what is being said, mood recognition can add to security and prevent voiceprint counterfeiting and imitation.
4) Gender recognition: distinguish whether a speaker is male or female. This is another tool which can be useful to help confirm speaker identity.
Process
Training and prediction are the two main stages of speaker recognition. The training stage sets up a compute model with the old data, and the prediction gives the reference result on current data with the model..
Training can be further divided into three steps:
1) Extract audio features with Mel-frequency cepstrum algorithm.
2) Mark human voices as positive and non-human samples as negative. Train the neural network model with these samples.
3) Use the final training results to create the prediction model for mobile.
In short, the training flow is feature extracting, model training and mobile model porting. For prediction, the flow is extract the voice feature, run the mobile model with the feature, and get the final predict result.
Artificial Intelligence Framework
The launch of TensorFlow Lite was announced at the Google I/O annual developer conference in November 2017. TensorFlow Lite is a lightweight solution for mobile and embedded devices, and supports running on multiple platforms, from rackmount servers to small IoT devices.
With the widespread use of machine learning models, there has been a demand to deploy TensorFlow Lite on mobile and embedded devices. Fortunately, TensorFlow Lite allows machine learning models to run on devices with low latency inference.
Tensorflow Lite is an AI learning system from Google. Its name derives from its operating principles. Tensor means N-dimensional array, flow implies calculation based on data flow graphs. TensorFlow refers to the calculation process of tensor flowing from one end of the data flow graph to the other. TensorFlow is a system that transmits complex data structures to AI neural networks for analysis and processing.
The following figure shows the TensorFlow Lite data structure :
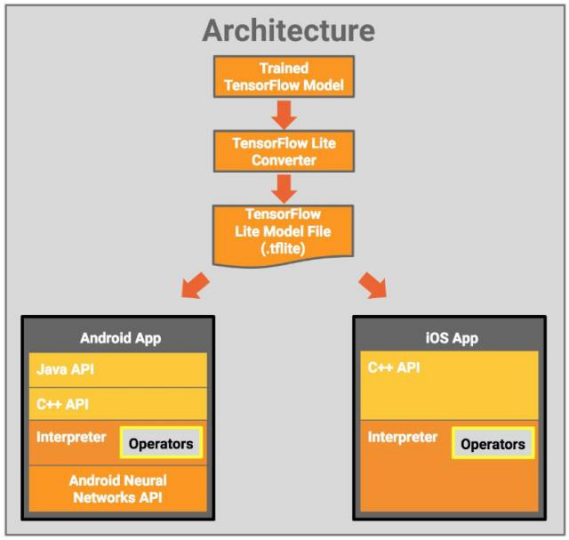 TensorFlow Lite architecture diagram
TensorFlow Lite architecture diagram
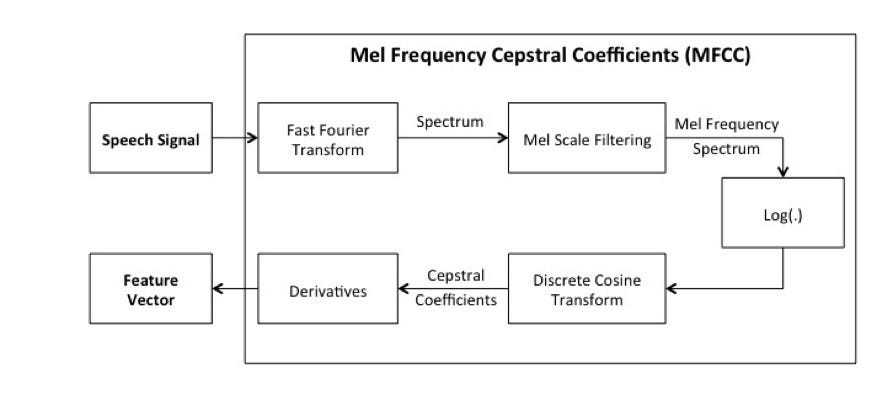
Mel-Frequency Cepstrum Algorithm
Algorithm introduction
For this solution, the Alibaba tech team uses the Mel-frequency cepstrum algorithm. The algorithm is used for speaker recognition. Using the algorithm contains the following steps:
1) Input sound files and resolve them to original sound data (time domain signal).
2) Convert time domain signals to frequency domain signals through short-time Fourier transform, windowing and framing.
3) Turn frequency into a linear relationship that humans can perceive through Mel spectrum transform.
4) Separate the DC component from the sine component by adopting DCT Transform through Mel cepstrum analysis.
5) Extract sound spectrum feature vectors and convert them to images.
The purpose of windowing and framing is to ensure the short-term stationary character of the speech in the time domain. Mel spectrum transform is used to translate human auditory perception of frequency into a linear relationship. Mel cepstrum analysis is used to understand Fourier transform, through which, any signal can be decomposed into the sum of a DC component and a number of sine signals.
 The Mel-frequency cepstrum algorithm implementation processShort-time Fourier transform
The Mel-frequency cepstrum algorithm implementation processShort-time Fourier transform Time domain sound signals
Time domain sound signals Frequency domain sound signals
Frequency domain sound signals
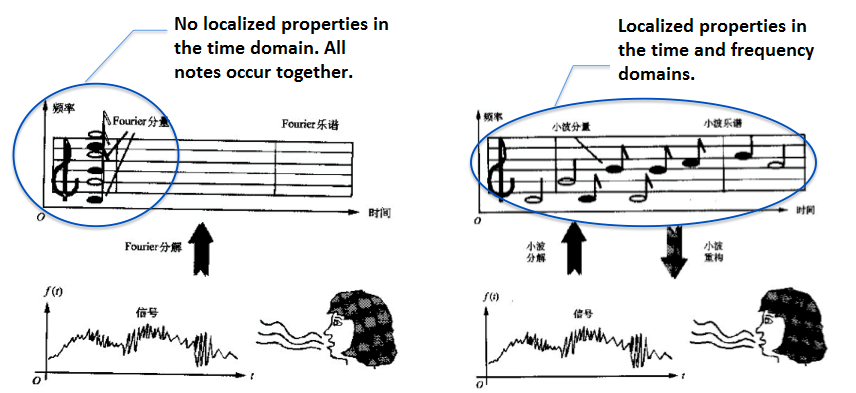
The sound signal is a one-dimensional time domain signal. It is difficult to find the rule of how the frequency changes. If we convert the sound signal to frequency domain via Fourier transform, it will show the signal frequency distribution. But at the same time, its time domain information will be missing, making it impossible to see the change of frequency distribution over time. Many joint time-frequency analysis methods have emerged to solve this problem. Short-time Fourier transform, wavelet, and Wigner distribution are all frequently-used methods.
 FFT transform and STFT transform
FFT transform and STFT transform
The signal spectrum can be obtained via Fourier transform and can be widely utilized. For example, signal compression and noise reduction can both be based on the spectrum. However, Fourier transform is built upon an assumption that the signal is stationary, that is, that the statistical properties of the signal do not change over time. However, the sound signal is not stationary. Over a long period of time, there are many signals that will appear and then disappear immediately. If all the signals are Fourier transformed, the change of sound over time cannot be reflected accurately.
The short-time Fourier transform (STFT) used in this article is the classic joint time-frequency analysis method. Short-time Fourier transform (STFT) is a mathematical transformation associated with the Fourier transform (FT) to determine the frequency and phase of a sine wave in a local region of the time-varying signal.
The concept of short-time Fourier transform (STFT) is to first choose a window function with time-frequency localization, then assume that the analysis window function h (t) was stationary over a short time, which ensures f (t) h (t) is a stationary signal within different finite time widths. Finally, calculate the power spectrum at various moments. STFT uses fixed window functions, the most commonly used of which include the Hanning window, the Hamming window, and the Blackman-Haris window. The Hamming window, a generalized cosine window, is used in the solutions in this article. The Hamming window can efficiently reflect the attenuation relationship between energy and time at a certain moment.
The STFT formula in this article takes the original Fourier transform formula,
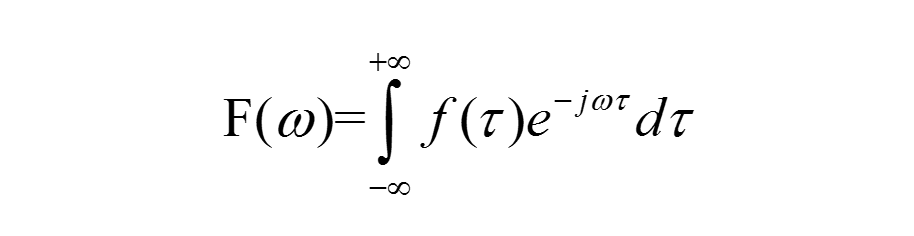
and adds a window function to it, creating the following updated STFT formula:
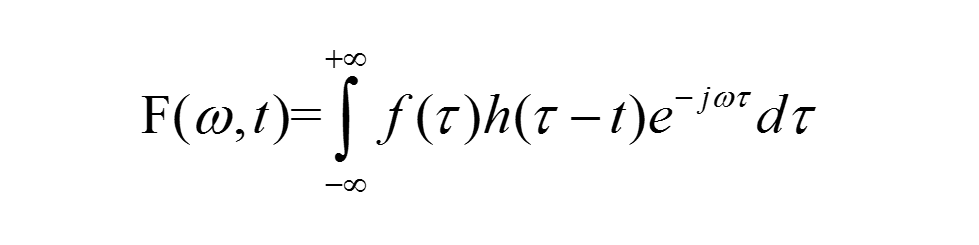
The following is a Hamming window function:
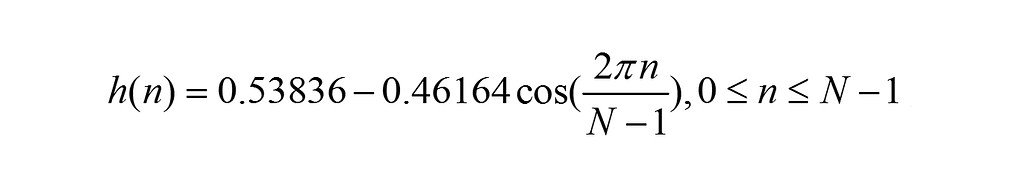
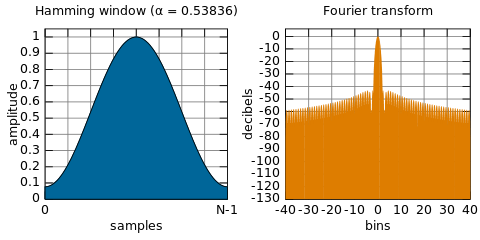 STFT transform based on the Hamming window
STFT transform based on the Hamming window
Mel Spectrum
Spectograms are usually in the form of a large map. In order to turn the sound features into a suitable size, they often need to be transformed into Mel spectrum via Mel scale filter bank.
Mel scale
The Mel scale was named by Stevens, Volkmann, and Newman in 1937. It is known that the unit of frequency is Hertz (Hz) and the frequency range of human hearing is 20–20000 Hz.
But human auditory perception does not relate to scale units such as Hz in a linear manner. For example, if we have adapted to a 1000Hz tone, then when tone frequency is increased to 2000Hz, our ears could only perceive that the frequency may be increased by a little, and we would never realize that the frequency had doubled. The mapping for converting an ordinary frequency scale to Mel-frequency scale is as follows:
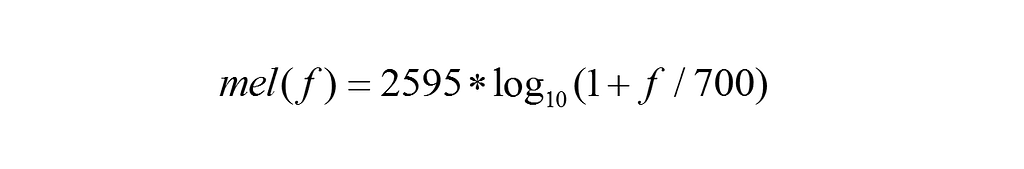
The above formula changes the frequency so that it has a linear relationship with human auditory perception. That is to say, if one Mel scale frequency is the double of another Mel scale frequency, human ears could perceive that one frequency is roughly the double of the other.
Since there is a log relationship between Hz and Mel frequency, if the frequency is low, Mel-frequency will change rapidly with Hz; if the frequency is high, Mel-frequency will change slowly. This shows that human ears are sensitive to low frequency sounds and less responsive to high frequency sounds. This rule forms an important basis for the Mel scale filter bank.
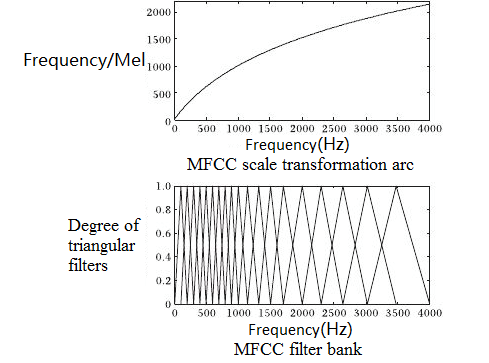 Frequency transforms to Mel frequency
Frequency transforms to Mel frequency
The figure below shows 12 triangular filters forming a filter group. This filter group features dense filters and high threshold in the low frequency zone, as well as sparse filters and low threshold in the high frequency zone. This aligns well with the fact that human ears are less responsive to sounds of higher frequency. Mel-filter banks with same bank area, a form of filters shown in the figure above, are widely used in fields such as speech and speaker recognition.
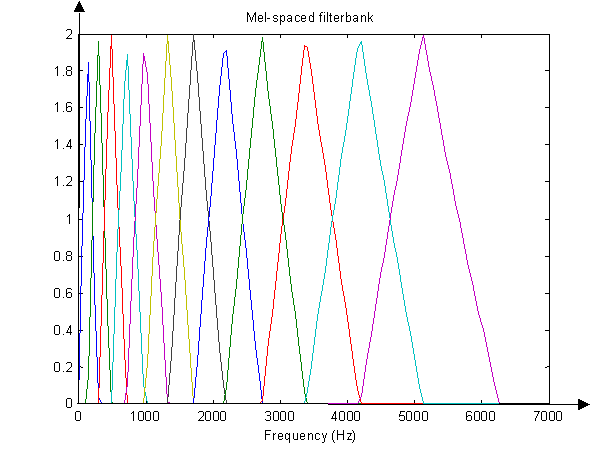 Mel filter bankMel-Frequency Cepstrum
Mel filter bankMel-Frequency Cepstrum
The result of applying DCT transformation to the Mel log spectrum to separate components of DC signal and sine signals is the Mel-frequency cepstrum (MFC).
 Optimizing algorithm processing speed
Optimizing algorithm processing speed
Since the algorithm is designed to be used on the client side, fast processing is required. The following steps can be taken to optimize algorithm processing speed.
1) Instruction set acceleration: The algorithm features many matrix addition and matrix multiplication operations. The ARM instruction set is introduced to accelerate operations. It can increase the speed by 4–8 times.
2) Algorithm acceleration:
a) Select vocal frequency range (20HZ~20KHZ), and filter out input outside the non-vocal frequency range to reduce redundant computation.b) Lower the audio sampling rate to reduce unnecessary data computation. This is possible because human ears are insensitive to sampling rates that are too high.c) Cut windows and sections reasonably to avoid excessive computation.d) Detect silent sections so that unnecessary sections can be deleted.
3) Sampling frequency acceleration: If radio sampling frequency is too high, choose downsampling and set the highest sampling frequency to 32 kHz.
4) Multi-thread acceleration: Divides audios into multiple fragments concurrently processed by multi-threads. The number of threads depends on the machine capacity. The default setting is four threads.
 Algorithm parameters selected by the engineering team
Algorithm parameters selected by the engineering team
Speaker Recognition Models
Model selection
Convolutional Neural Networks (CNN) are a type of feedforward neural network. CNN networks contain artificial neurons that can respond to some of the neurons in their field. This type of neural network is highly suitable for processing large images.
In the 1960s, while studying neurons in the cerebral cortices of cats that aid in local sensing and direction selection, Hubel and Wiesel found unique cellular structures that could be used to simplify feedback neural networks. This led them to propose the CNN concept. CNNs have become a hot spot in many research fields, particularly in modal classification.
CNNs owe part of their popularity to their ability to skip complex pre-processing of images and allow direct import of original images. The first CNN-like network was the neocognitron proposed by K.Fukushima in 1980. Since then, multiple researchers have worked to improve the CNN model. Among the most significant of these efforts has been the work on improved cognition proposed by Alexander and Taylor. This research on improved cognition combines the strengths of various approaches and avoids time-consuming error back propagation.
In general, CNN structure is made up of two fundamental layers. One of these layers is the feature extraction layer. In this layer, each neuron’s input is connected to the local accepted domain of the previous layer and extracts the features of this local domain. Once extracted, the positional relation of this local domain feature to other features is fixed.
The other is the feature mapping layers which gather to form every computing layer of the network. Each feature mapping layer is a surface in which all neurons have the same weight. Using functions with small influence function kernels, such as sigmoid and relu as the activation function of CNN, the feature mapping structure ensures constant displacement of feature mapping. The number of free network parameters is reduced, since neurons on the same mapping surface share the same weight. In CNN, every convolutional layer is closely followed by a computing layer that is used to obtain local averages and secondary extraction. This specific secondary feature extraction reduces feature resolution.
CNN is used mainly to recognize 2D images that are modified but not deformed, such as images which have been zoomed in on. Since CNN’s feature detection layer learns implicitly through training data, using CNN can avoid the need for explicit feature extraction.
CNN can also learn concurrently, as it places the same weight for neurons across the same feature mapping surface. This gives CNN another big advantage over networks in which neurons are inter-connected. Local weight sharing gives CNN a unique advantage in speech recognition and image processing. In terms of layout, CNN is closer to actual biological neural networks. Weight sharing ensures a less complex network and CNN does not have to handle the complexity of data reconstruction during feature extraction and classification, since images of multi-dimensional input vectors can be directly imported into the network.
 Inception-v3 model
Inception-v3 model
The accurate Inception-v3 model is used in this article as the speaker recognition model. Decomposition is one of the most important improvements of the v3 model. 7x7 CNNs are decomposed into 2 one-dimensional convolutions (1x7, 7x1), and 3x3 CNNs are also decomposed into two convolutions (1x3,3x1). This accelerates computation, further deepens the network, and makes it more non-linear. The v3 model network input is upgraded from 224x224 to 299x299, and the design of the modules 35x35/17x17/8x8 are improved.
Using a TensorFlow session enables modules to realize training and prediction at the code layer. The TensorFlow official website provides details of how to use a TensorFlow session.
 Using a TensorFlow sessionModel example
Using a TensorFlow sessionModel example
In monitored machine learning, samples are typically divided into three sets:
· The train set: This set is used to estimate models. It learns the sample data sets and builds a classifier by matching some parameters. It creates a classification manner used to train models.· The validation set: This set is used to determine the network structure or control parameters that control model complexity. It adjusts the classifier parameters of models obtained through learning, such as choosing to hide the number of units in neural networks. The validation set is also used to determine the network structure or parameters that control the complexity of models, in an attempt to avoid overfitting of models.· The test set: This set is used to check how the finally selected optimal model performs. It is mainly used to test the recognition capacity (such as the recognition rate) of trained models.
The Mel Frequency Cepstrum algorithm described in the second chapter can be used to obtain speaker recognition as sample files. Sounds within the human vocal spectrum as positive samples, animal sounds and other non-human noises are used as negative samples. These samples are then used to train the Inception-v3 model.
With TensorFlow as the training frame, this article takes 5000 human vocal samples and 5000 non-human vocal samples as the test sets, and 1000 samples as the validation set.
Model training
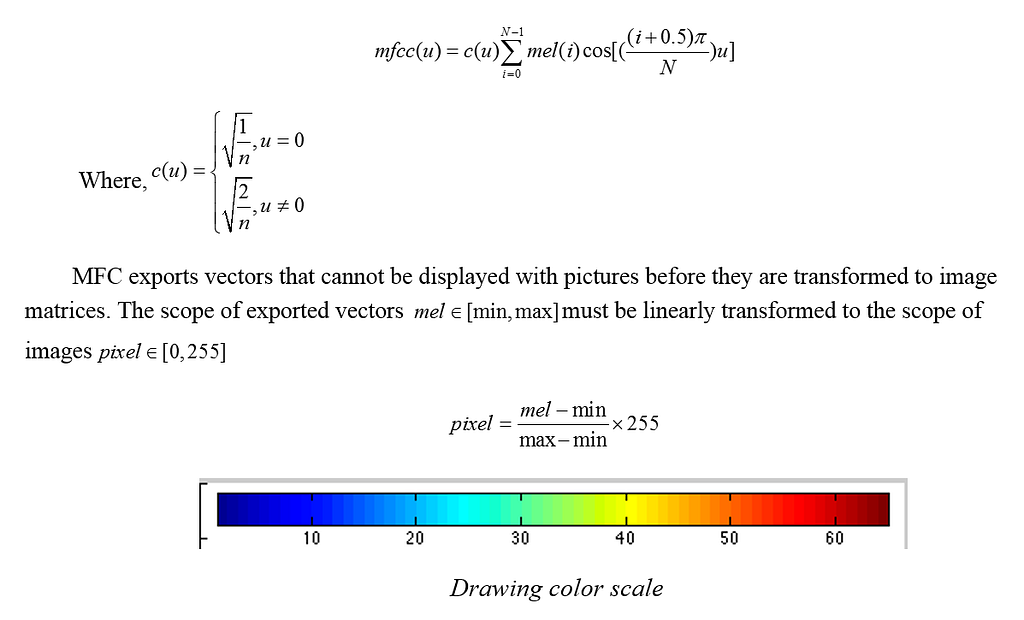
Once samples are ready, they can be used to train the Inception-v3 model. The convergence of the trained model can generate the pb model usable on the client. In model selection, choose compiling armeabi-v7a or a later version, and NEON optimization is enabled by default. In other words, opening the macro of USE_NEON can accelerate instruction sets. More than half of the operations in a CNN take place at convolutions, so instruction set optimization can speed up operations by at least four times.
 Convolution processing function
Convolution processing function
The toco tool provided by TensorFlow can then be used to generate a lite model which can be directly called by the TensorFlow Lite frame on the client.
 Toco calling interfaceModel prediction
Toco calling interfaceModel prediction
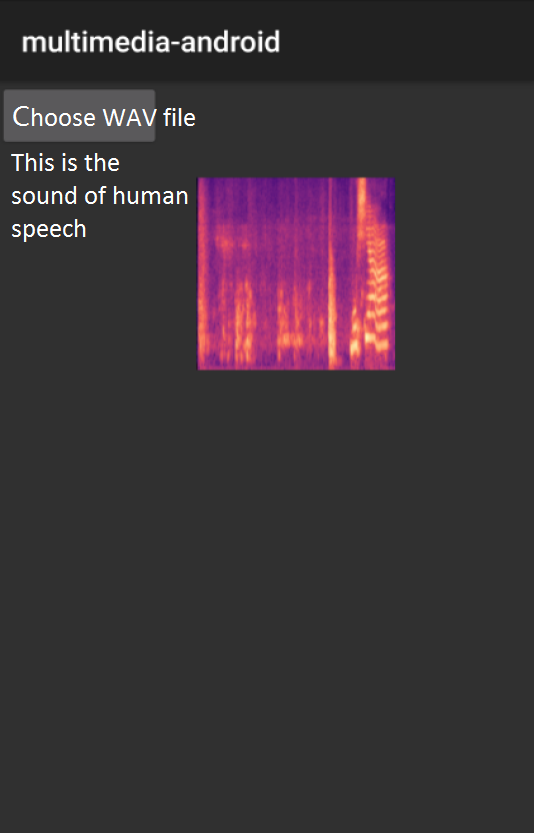
MFC can be used to extract vocal sound file features and generate prediction images. Using the lite prediction model generated in training produces the following results:
 Model prediction result
Model prediction result
Conclusion
The methods proposed above can help to address some of the most difficult challenges in the speaker recognition field today. Using TensorFlow Lite on the client side is a useful innovation that helps leverage machine learning and learning and neural networks to drive the technology forward to further progress.
(Original article by Chen Yongxin陈永新)
References:
[1] https://www.tensorflow.org/mobile/tflite
[2] 基于MFCC与IMFCC的说话人识别研究[D]. 刘丽岩. 哈尔滨工程大学 . 2008
[3] 一种基于MFCC和LPCC的文本相关说话人识别方法[J]. 于明,袁玉倩,董浩,王哲. 计算机应用. 2006(04)
[4] Text dependent Speaker Identification in Noisy Enviroment[C]. Kumar Pawan,Jakhanwal Nitika,
Chandra Mahesh. International Conference on Devices and Communications . 2011
[5] https://github.com/weedwind/MFCC
[6] https://baike.baidu.com/item/ARM指令集/907786?fr=aladdin
[7] https://www.tensorflow.org/api_docs/python/tf/Session
Alibaba Tech
First hand, detailed, and in-depth information about Alibaba’s latest technology → Facebook: “Alibaba Tech”. Twitter: “AlibabaTech”.

“Hello,” from the Mobile Side: TensorFlow Lite in Speaker Recognition was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.