Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Chatbot Development Challenges — Part 1
Last October, virtual assistants were placed at the Peak of Inflated Expectations in 2017 Gartner Hype Cycle for Emerging Technologies. It was a substantial jump from the middle of the Innovation Trigger part of the cycle in 2016. Around the same time in October, conversational platforms were named as one of 10 strategic technology trends for 2018 by Gartner. From my subjective point of view, chatbots indeed generated a lot of hype this year, surpassed only by cryptoassets, machine learning in its general sense and IoT.
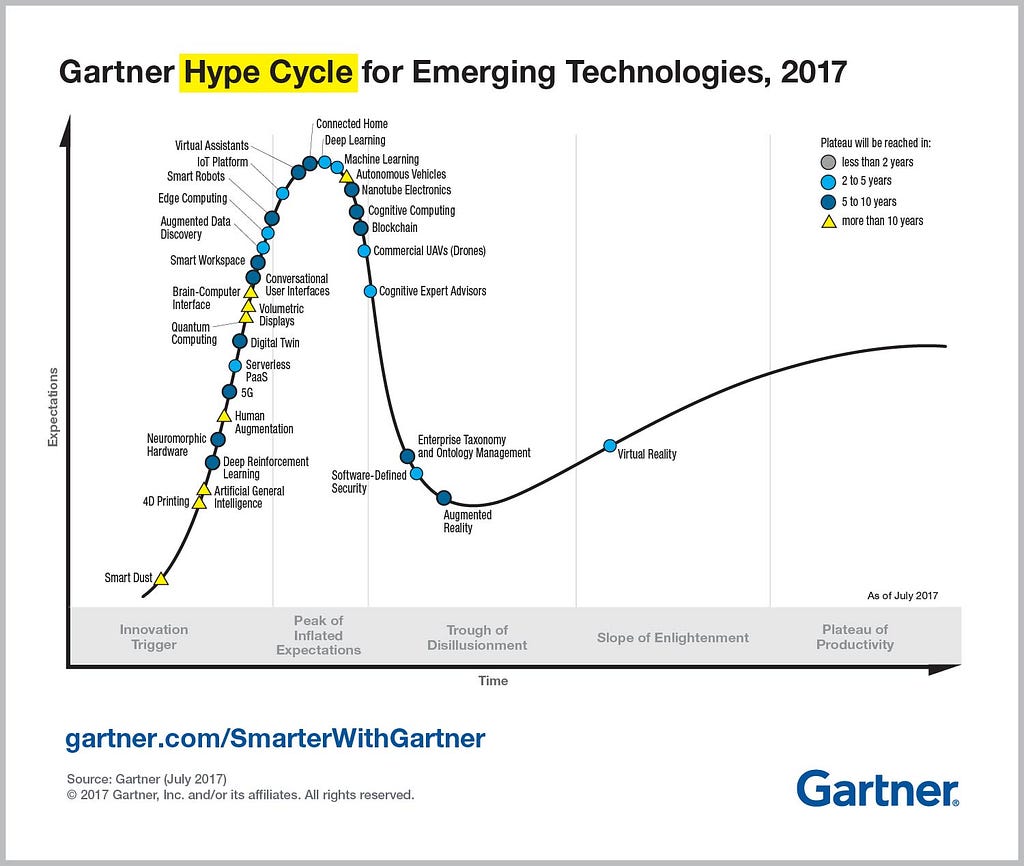
For a technology, being at the Peak of Inflated Expectations and heading towards the Trough of Disillusionment certainly entails something. Too many unsupported claims and promises multiplying each day, inadequate developer tools, roadblocks in fundamental research supporting the technology, the list can go on; as any technology reaches a certain level of public attention, more people will actually use it and see the real state of affairs.
 Every popular tech trend went through this.
Every popular tech trend went through this.
Going towards a Trough of Disillusionment on a hype cycle doesn’t mean no one will be working on chatbots once we get there. There will be less interest from the public, the media and the investors; but there will also be many developers and researchers quietly building chatbots. Those developers and researchers will make sure that once promising tech delivers useful results, albeit many challenges along the way.
I wanted to take a stab at laying out some of the challenges with chatbots. I will not be talking about the fundamental difficulties facing fields of traditional natural language processing (NLP) and deep learning, the two research disciplines standing behind today’s chatbots’ ability to understand human speech. Instead, I will share some challenges that I encountered when working on chatbots as a developer. It’s important for new chatbot developers to be aware of these things, as I felt they were very general challenges not specific to my projects.
My experience with chatbots
I wanted to share some bits of my background that are relevant to the topic of chatbots. This is done solely to make you aware of some of the biases that I might have.
Over the last 8 months I worked on several chatbot projects and had an opportunity to chat with quite a few teams about their experiences with building chatbots.
My experiences with different chatbot frameworks:
- Dialogflow: 2 projects
- Rasa Stack: 3 projects
- Microsoft LUIS: saw a demo at a sales presentation :)
This write-up is based on the part of the presentation on chatbots that I gave while working as a software developer intern at Telus, a Canadian telco. You can view the deck used in that presentation in my LinkedIn profile (it’s named Chatbots: Lessons Learned).
Since I had the most experience developing with Rasa Stack, some of the examples will mention Rasa-specific concepts. I will also touch on Dialogflow a little. Otherwise, I try to talk about chatbot development in general but my generalizations may be wrong given my limited exposure to other frameworks.
Conceptual Challenges
This section features a couple of conceptual challenges (also known as common misconceptions). It’s important that all stakeholders in a chatbot project overcome these challenges in order to have more realistic expectations about the chatbot and the project’s timeline.
Self-improvement capabilities
A misconception that a piece of technology with self-improvement capabilities will readily deliver substantial time savings for an organization is common among those who are just starting out with any project that uses machine learning (ML), not just chatbots. I guess the thinking in this case is that you only need to bootstrap a chatbot so that it can handle basic interactions; after that it will be able to learn more complicated interactions by itself over time.
 This is not how supervised learning works. Source
This is not how supervised learning works. Source
Over-optimistic thinking about new technologies, especially the AI, is really common and unsurprising given the mainstream media coverage of the topic.
Exaggerated claims in the press about the intelligence of computers is not unique to our time, and in fact goes back to the very origins of computing itself.(quoted from the article linked above)
In just a matter of few days of actual hands-on development experience, most people start understanding the limitations of the technology and realize a few things about self-improvement in the context of chatbots:
- Any degree of self-improvement requires a good natural language understanding (NLU) pipeline.
- Even fully-automated NLU feedback pipeline requires constant supervision (all chatbot frameworks use supervised learning models)
- You need to develop really good admin UI for an efficient and painless supervision process (more on this in part 2)
After all, a supervised ML model doesn’t really have self-improvement capability as its intrinsic property. It’s up to the developers to build tools and pipelines around the model that will make it seem like the model can learn new things with very little effort from its human supervisors.
Viability of leveraging existing data
This misconception is another common one among those who haven’t had practical experience with ML beforehand. In my experience the thought process goes like this: “My organization has lots of data. It’s widely known that data is fuel for ML, therefore having lots of data will make it easy to create a successful ML-enabled application.”
The problem with this line of reasoning is, of course, that simply having some data that is semi-related to your project is far from enough. I’ve read somewhere that more than half of a data scientist’s work day is spent preprocessing the data (I don’t have sources to back this up but the figure seems about right in my experience). While preparing existing data for use in a chatbot project is not exactly the same as data preparation for a data science analysis, it’s still very time consuming.
 Do you have enough chat data lying around?
Do you have enough chat data lying around?
To illustrate difficulties with leveraging existing data more concretely, let’s assume that the chatbot project we are working on is some enterprise help desk chatbot (that was the application of my very first chatbot project). There are two major ways you can go about chatbot NLU training data preparation.
Existing data in different format
Assume that your current help desk operates via email. You have lots of training data in the email form. You figured out how to do bulk exports from Outlook (or any other email client), how to convert exported files to plain text, how to strip headers and other fluff, like “Hi …”, “Thanks, …” or super long signatures containing company’s entire policy on email communications.
What you have left is still relatively long messages, sometimes multiple paragraphs long, that are definitely not chatbot training data material; the way people communicate in a chat environment is very different from email communications.
There are two ways to go from here:
- One, you take note of common problem types from those emails and use them as a foundation when coming up with the chatbot-appropriate training data yourself; you would have to think of the ways people could’ve asked their emailed questions in a chat environment. In this case the existing data only helped you to define the initial domain of your chatbot’s NLU capabilities. The bulk of data preparation work is still on you or your team.
- The other way is to ditch the chatbot project idea altogether and go with an automated email response system. This approach is not in the scope of this article.
Existing data in same format
Assume that your current help desk operates via a chat system (e.g. Slack, Google Hangouts or similar). You export all the dialogue data and take only user utterances without help desk agent responses. You examine all the utterances and go through the process of data labelling, assigning the correct category (intent) to each utterance. You’ve successfully leveraged your existing data!
It seems that this was as easy as it could get for a ML project: you just get your raw data and make it suitable for supervised learning algorithms by labelling it. Well, assigning intents to utterances is actually much more complicated than data labelling for something like computer vision datasets (e.g. ImageNet). I will touch more on reasons for this in part 2 of the series. In general, attaching labels to human speech is a much more subjective process than labelling images with concrete objects.
Development challenges
Challenges presented in this section are, in my opinion, special to chatbot development. Though, I feel like these challenges may also be true for other machine learning application development processes, I can speak with certainty only about chatbot development.
ML model nondeterminism
To clarify this subsection’s title, I will talk about how ML models can be nondeterministic when comparing same models (same architecture and same hyperparameters) between different training sessions, and how this affects chatbot development.
First, it’s important to note that every model’s weights will be different between training sessions even when a model architecture and hyperparameters are unchanged. This happens due to random weight initialization and data shuffling. But this shouldn’t introduce any noticeable effects to your model’s performance, given your training dataset is not very small.
What can make variance in weight values have negative effects on a chatbot development process is errors in labelling or structuring of training data.
Errors in NLU data
 Usually NLU training data errors are much harder to spot.
Usually NLU training data errors are much harder to spot.
Let’s use help desk chatbot example again. Imagine having a rather large intent mapping for your NLU model of about 300 intents. You are reviewing the latest chat logs and labelling new user utterances. You label “I recently lost my phone and can’t log to website X since I used the phone for 2FA” as a brand new intent help.smartphone.2fa, since your team recently came up with a process describing how exactly a problem with 2-FA should be handled by the bot. You finish labelling the rest of the data, retrain the model and quickly do some manual testing; you start with “I have problem with 2-FA on my phone”, the bot replies with something that is triggered by a more general intent help.smartphone. Hmm… You decide that maybe there are too few examples for help.smartphone.2fa, so you create some more. You retrain the model, test it locally and now “I have problem with 2-FA on my phone” maps to help.smartphone.2fa, just as expected. Well done!
You push the updates to the prod server and during the build process, the model is re-trained once again. In a couple of hours you get a message from your colleague saying that the model on the prod server maps 2-FA-related utterance to help.smartphone, not the newly added help.smartphone.2fa. You try the same utterance on your local copy of the model trained on exactly the same training data and it maps to help.smartphone.2fa as expected.
So what might cause an issue like this? One possible cause for the example above is that a few months back when you had far fewer intents which were all very general, you labelled some utterances related to 2-FA on smartphones as help.smartphone. Back then it made sense since, at the time, your bot had a single response to all smartphone related troubleshooting, e.g. “Call this number and out team will help you with your smartphone problem.” Adding a new intent help.smartphone.2fa created a condition when utterances that are very similar lexically and syntactically map to two different intents. This caused the bot to behave differently between training sessions given the same input.
A NLU model is reliable and predictable only when trained on many-to-one or one-to-one mappings, not one-to-many or many-to-many. So before introducing a new intent, always search for keywords that are relevant to this intent in your training data; if you find any training data that can create interference, reassign those examples to a new, more precise intent (a good NLU admin UI helps immensely with this process).
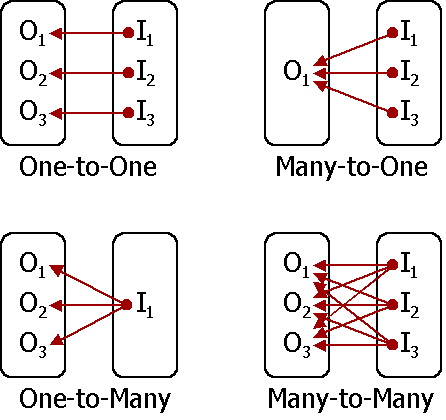 “O”s are intents and “I”s are training examples. Source
“O”s are intents and “I”s are training examples. Source
Errors in dialogue data (relevant to Rasa Core only)
Another mistake that can make a chatbot behave differently between training session is to create Rasa Core stories that have identical starting conditions but end differently. Quick example:
> general computer problem - utter_confirm_need_help_now* yes - action_create_ticket - utter_expect_specialist_soon
> general computer problem - utter_confirm_need_help_now* yes - utter_bring_device_to_helpdesk
This example seems especially naive given the two conflicting stories are right beside each other. But believe me, when you have a lot of stories spread around many files and receive conflicting feature requests, it’s quite easy to make this mistake. And then it’s very nontrivial to debug this if you are not used to this kind of bugs: there’s no default checks in Rasa Core for conflicting stories, the problem may be invisible locally and will manifest itself on some other machine (e.g. your dev server) and finally, as a programmer, you may start looking for bugs in the code’s logic, not training data.
To verify that the chatbot’s dialogue model works as expected before deploying it, it’s helpful to write some test stories. One good package that contains a tool for automated Rasa Core testing is Rasa Addons (test feature is currently experimental).
Training time
Sometimes developing chatbots with Rasa Core feels how I would imagine software development felt 30–40 years ago when developers mostly used compiled languages and their computers were much worse performance-wise compared to what we have today. You would write a small piece of code, try to compile it, fix all the compilation-time warnings and errors and finally start the compilation process. Now you would switch over to finishing an email that you started earlier. Or take a coffee break. Or go for a walk (good thing there was no YouTube back then)… Depending on the code base size the compilation could have taken a while.
 Obligatory XKCD when talking about code compilation
Obligatory XKCD when talking about code compilation
Similarly, when you implement a new feature in Rasa Core (e.g. a new dialogue branch), you have to re-train the LSTM that is used by Rasa Core for handling different conversation scenarios to test it. As the training dataset for your chatbot grows, so does its training time.
Of course you can play around with the number of epochs in order to optimize the amount of time it takes to train your model. For instance, stop training as soon as the rate of change of the loss is below certain threshold. Still, this only takes you so far.
I recently crossed the 7 minute train time mark with one of the chatbots that I am working on and this wait can be frustrating sometimes (especially if I get distracted on something unrelated while waiting) or it can be a good opportunity to take a short break (unless I’ve been re-training the model for 3 times in a row for some reason).
While it’s possible to isolate a single component that you are working on in case of regular software development in compiled language, and avoid recompiling an entire project each time, it is not possible with a ML model; it is an indivisible component of a project.

I think the GPU is the limiting component in my personal case, thus the way to mitigate this problem would to buy an extra GPU or to get used to the long training time and match it with breaks.
If you found what you’ve read so far interesting, please stay tuned for part 2 of the series. In part 2 I will go into in-depth discussion of common architectural challenges in chatbot projects. Challenges from that category are the most difficult in my opinion, so there will be plenty to talk about :)
You can find other articles by me either in my Medium profile or on my website (the website has slightly more content). I write about pretty much everything that is listed in my Medium bio: ML, chatbots, cryptoassets, InfoSec and Python.

Chatbot Development Challenges - Part 1 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.