Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In this article I will be giving a mathematical intuition of gradient descent and the reason behind moving in the direction opposite to the gradient.

I assume prior knowledge in partial derivatives,vector algebra ,Taylor Series and a basic understanding of neural networks.
So let’s dive in.
In neural networks we always need to learn the weights and biases from the data we have such that we reach the absolute minimum of the loss function and so we need to have a principled way of reaching the absolute minimum of the loss function.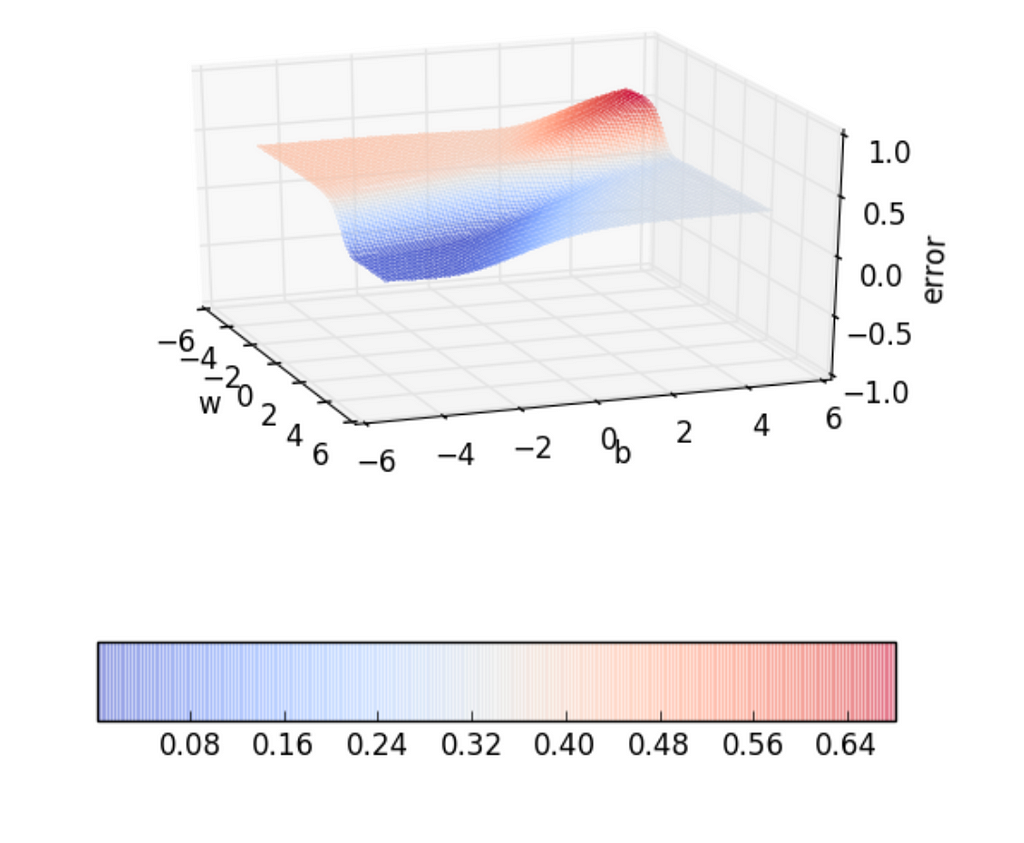 Error Surface
Error Surface
Our main objective is to navigate through the error surface inorder to reach a point where the error is less or close to zero.
Let us assume θ = [w,b] where w & b are the weights and the biases respectively. θ is an arbitrary point on the error surface.To start with w & b are randomly initialized and this is our starting point.
θ is a vector of parameters w and b such that θ ∈ R².
Let us assume Δθ = [Δw , Δb] where Δw & Δb are the changes that we make to the weights and biases such that we move in the direction of reduced loss and land up at places where the error is less. Δθ is a vector in the direction of reduced loss.
Δθ is a vector of parameters Δw and Δb such that Δθ ∈ R².
Now we need to move from θ to θ+Δθ such that we move towards the direction of minimum loss.
 Loss Function
Loss Function
If we add up Δθ to θ we obtain a new vector.
Let the new vector be θnew.
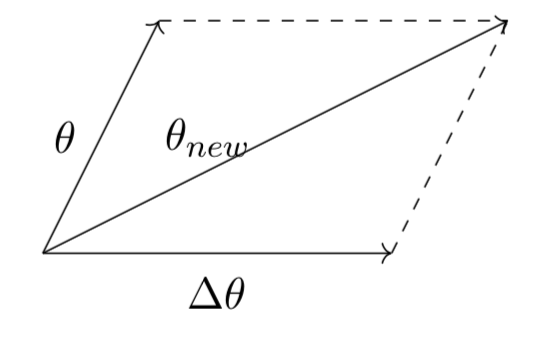
Hence as you can see from the figure above the vector θ is moving in the direction of the vector Δθ.
But it would be better if we don’t make huge strides towards Δθ although we are interested in moving in that direction.If we take huge strides we have a chance of missing the absolute minimum of the loss function.
So instead we take smaller steps towards Δθ. This is governed by a scalar “ η”.
The scalar “ η ” is called the learning rate. η is generally less than 1.So we will move in the direction of Δθ scaled down by a factor of η.
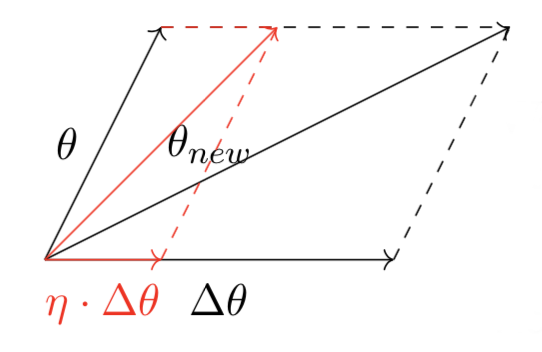
Hence θnew = θ + η.Δθ where Δθ is the direction of reduced loss.
So we start from a random value of θ. And then we move in the direction of Δθ which ensures that our loss decreases. And we need to do this in a cyclic manner to reach the global minimum.
But what is Δθ ? And what is the right value for Δθ?
Hang on we will get to it.
So the answer for the question above comes from Taylor Series.
For simpicity lets assume Δθ =u . And here we go.
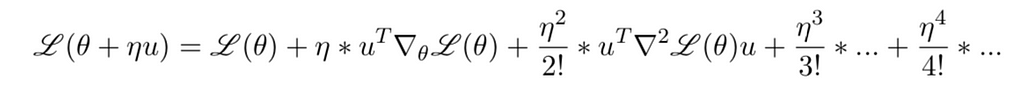 Taylor Series
Taylor Series
What Taylor Series tells us is that if we are at a certain value of θ and we make a small change to the value of θ then what will be the new value of the loss function.
L(θ) is called the loss function.
Here ∇L(θ) = [∂L(θ)/∂w , ∂L(θ)/∂b] is the gradient vector which is a collection of partial derivatives with respect to the components of θ.
The value of η is usually taken to be less than 1. And that η² <<<1. So we might as well ignore the higher order terms.
And we end up with the equation as below.
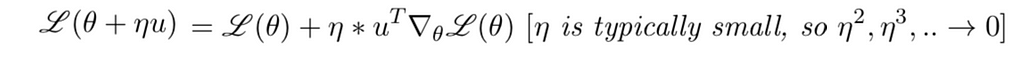
So we have some value of θ and we want to move away from that direction such that the new loss L(θ+ηu) is less than the old loss L(θ).
So a desired value for “ u ” is obtained when the following condition holds.
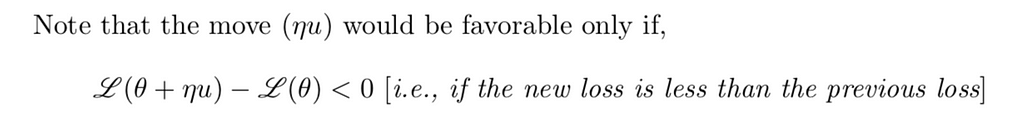
This implies,
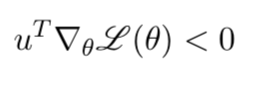
This condition should hold for the vector u that we are trying to choose so that we can be sure that we have chosen a good value for “ u ”. A good value of “ u ” can be obtained if the loss of the new step is less than the loss of the previous step.
So the range is ± ||u|| || ∇L(θ)|| .This is just the dot product of u and ∇L(θ).
Let us assume β as the angle between the vector u and the gradient vector ∇L(θ).Then we know that,
And assuming k = ||u|| || ∇L(θ)|| the inequalities simplify to,
We want the difference between the new loss and old loss to be as negative as possible. The more negative it is, the more the loss will decrease. So the dot product of the vector u and ∇L(θ) should be as negative as possible and so should be equal to -k. The value of cos(β) should be equal to -1 in this case.
This is in accordance with the condition u.∇L(θ) < 0.
The value of cos(β) will be equal to -1 when the angle between the vector u and the gradient is 180°.
The direction “u” that we intend to move in should be at 180° with respect to the gradient.
And this is the reason why need to move in the direction opposite to the Gradient.
So what the gradient descent rule tells us is that if we are at a particular value of θ and if we want to move to a new value of θ such that the new loss is less than the current loss then we should move in the direction opposite to the gradient.

Now these are the parameter update equations. And they follow what we have discussed so far.
I guess this article would have given you a mathematical intuition of gradient descent and the reason behind moving in the direction opposite to the gradient. Any feedback will be appreciated.
Citation:

The reason behind moving in the direction opposite to the Gradient was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.