Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Recently I had to give a few talks about machine learning, deep learning and computer vision. I started working on a slide deck and looked at what others online had been doing to convey concepts such as supervised learning, CNN’s etc.
I found really nice images and diagrams. They made sense to me as a data scientist but most of it felt too abstract to convey directly to a non-technical audience.
Besides that, people learn better by doing than by listening. So I always try to have some kind of audience interaction to make my presentations more engaging.
What if I could perform the whole process of machine leaning (data collection, training, testing) live on stage?
That would make the idea’s much more tangible and concrete. This is how I got the inspiration to develop Deep Hive.
The complete source code is available from:https://github.com/wouterdewinter/deep-hive
Deep Hive
The main concept is quite simple:
- People in the audience label images and simultaneously;
- The model is trained with these annotations and;
- The test results are displayed on the main screen.
The task is to learn a machine learning model to classify images in a number of classes. The default Dogs and Cats dataset has two classes. More classes are possible with custom datasets but more classes will require more data to achieve reasonable performance.
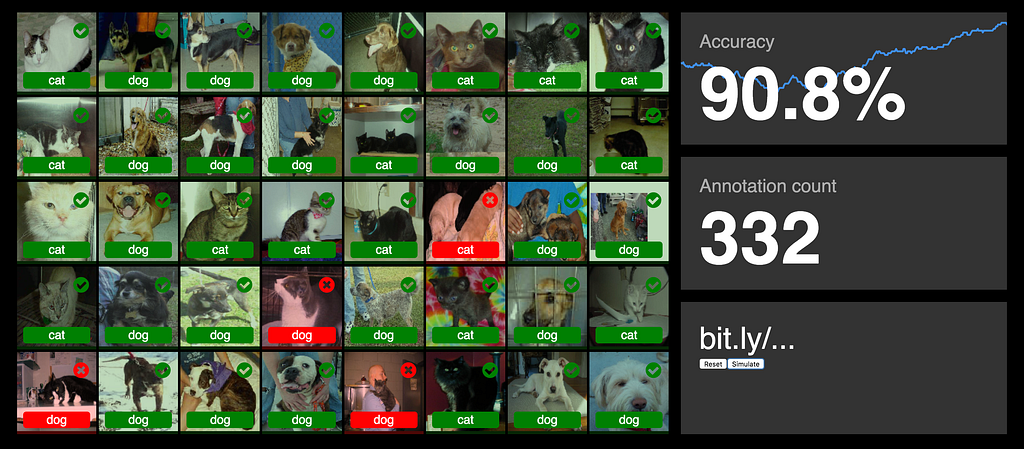 The Dashboard screenTraining and test sets
The Dashboard screenTraining and test sets
To prevent leaking information, the dataset is split into a training and test set. The images in the training set are shown to the users in the audience to label. The images in the test set are used for evaluation of the accuracy. These are the images displayed on the dashboard.
For every image label a user submits, the model will evaluate one test image. The average score of the last 64 test images is taken as the reported accuracy.
Architecture
Let’s dive in the nitty gritty details of the application.
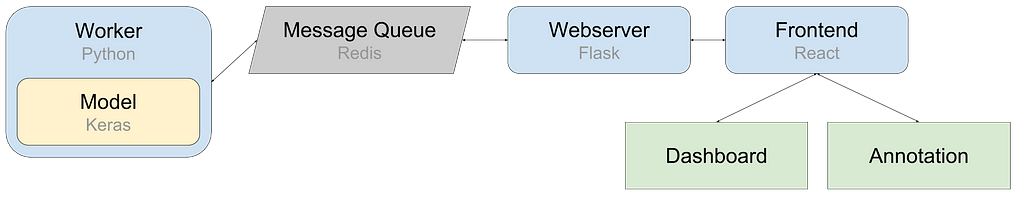 Moving parts of the applicationWorker
Moving parts of the applicationWorker
The worker is literally the work horse of the application. This python script is running in the background and contains the Keras model. It receives messages from the message queue such as new annotations. It interacts with the model and pushes accuracy stats back to the message queue.
The script runs in a single thread. You cannot have multiple workers running in a load balanced fashion because you need the model to learn from every new annotation and not just a fraction of it. There are ways to train models in a distributed way but this a more complicated and not needed for the small amount of data used here.
Model
For image classification tasks Convolutional Neural Networks (CNN) are the gold standard. Typically a CNN requires a lot of training data to perform well. We don’t have that luxury here because we have only very limited time to let the audience label the images. Luckily, we can drastically reduce the amount of data needed with ‘Transfer Leaning’.
Using this technique we can re-use already trained layers from another network, put our own layers on top and only train these last layers.
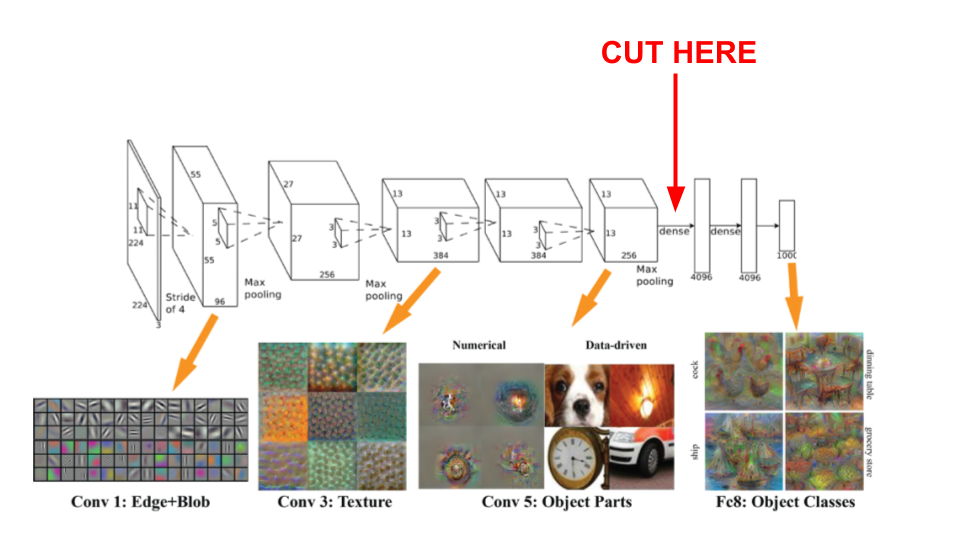 Transfer Leaning
Transfer Leaning
The Deep Hive model adds three layers added to a standard VGG-16 model:
Layer (type) Output Shape Param #=================================================================vgg16 (Model) (None, 4, 4, 512) 14714688_________________________________________________________________global_average_pooling2d_1 ( (None, 512) 0_________________________________________________________________dense_1 (Dense) (None, 256) 131328_________________________________________________________________dropout_1 (Dropout) (None, 256) 0_________________________________________________________________dense_2 (Dense) (None, 2) 514=================================================================Total params: 14,846,530Trainable params: 131,842Non-trainable params: 14,714,688_________________________________________________________________
There are 14,846,530 parameters in total, but we only need to train 131,842 of them. Sweet!
Because the model needs to learn from the new image labels one by one we are essentially doing ‘online learning’. This is the reason I opted for an old fashioned SGD (Stochastic Gradient Descent) optimizer instead of Adam or another optimizer that has a dynamic learning rate.
Message Queue
For simplicity I chose Redis as a message queue. Redis is a popular in-memory key/value store but has a very convenient pubsub mechanism. It acts as a relay between the worker and the webserver.
Webserver
The requirements for the webserver are pretty modest. Serve some static files, expose a small api for the frontend and pass messages on to Redis. Flask is lightweight and perfect for this task. Because the model is decoupled via the worker and Redis you can have Flask running multithreaded without issues.
Frontend
The dashboard is pretty dynamic and needs to update multiple parts on arrival of new data a few times per second. A simple React application will do the job. The application polls for new data every 300ms. This doesn’t scale very well but typically there is only one dashboard running at the time. Using websockets would would be a more scalable alternative.
Annotation
The annotation screen is built for mobile devices and shows an image to an audience member and a button for every class. Clicking one of the classes submits the label and immediately requests a new image to annotate.
 The annotation screenDashboard
The annotation screenDashboard
The dashboard has 4 parts:
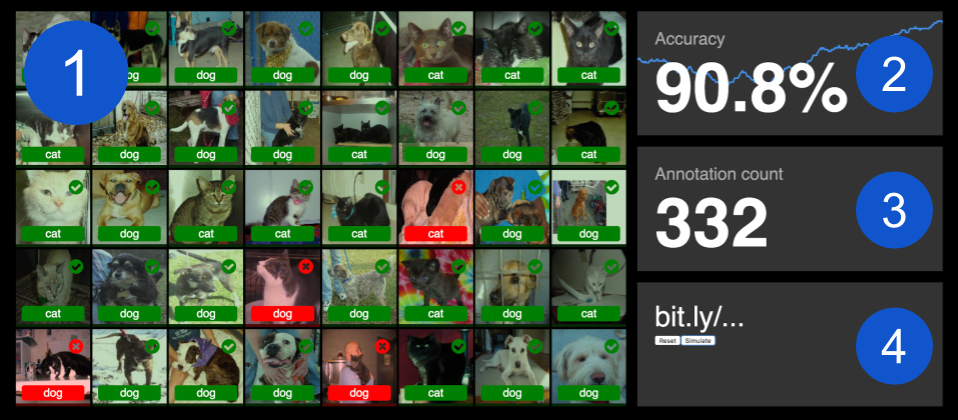
- The image grid shows the complete test set of 40 images. It displays the image, the predicted label and a color indicating a correct or incorrect prediction.
- The accuracy shows the accuracy of the test set and a graph in the background showing the trend. The graph is rendered by the excellent d3.js library.
- The Annotation count, well … shows the number of images annotated.
- The short URL is there for the audience to enter on their mobile. In my presentations I show a QR code in the slide before the Deep Hive demo to save a few users from typing.
There are two buttons underneath the short URL:
- Reset will reset the reset the model and re-evaluate the test set;
- Simulate simulates an audience by pushing the image labels of the complete training set in the message queue.
Datasets
I tried the application with two different datasets.
The main one is the Kaggle Dogs vs. Cats dataset. With this I got about 90% accuracy in about 250 user annotations. With 25 people in your audience this will typically take less than one minute!
For a client I’m working on a flower recogniser. Using images from two classes in their private dataset I got over 90% in about 160 annotations. It seems to be an easier task for the model.
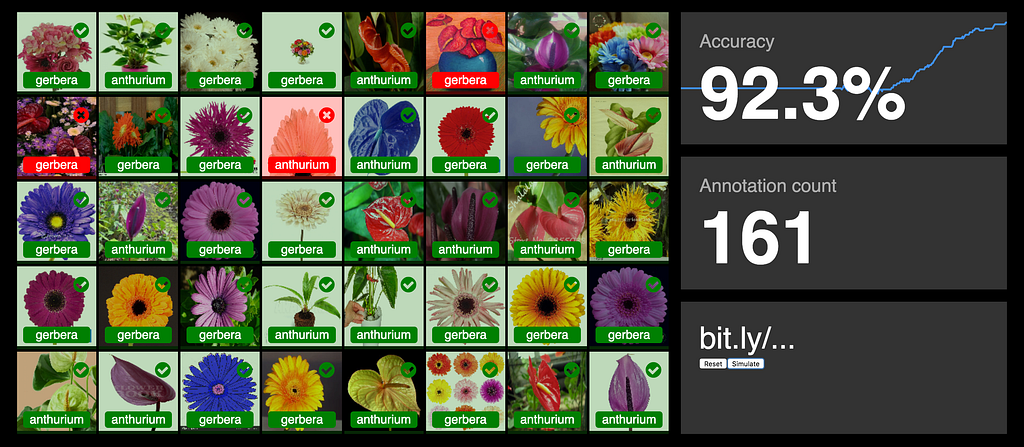 The flower dataset
The flower dataset
Conclusion
I hope you liked the application and the peek under the hood. If people are interested I might add a few more features soon. For example a learning rate slider or some other hyperparameter controls. Please let me know in the comments what you would like for a next version.
Feel free to use Deep Hive for your own presentations. I’m curious to know how it goes!

Deep Hive: Deep learning live on stage was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.