Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
I work as an astrophysics research assistant. This job entails managing and manipulating large datasets. In order to accomplish this, I have to take subsets that mirror the larger dataset. In order to get my computer to be able to run my code without reaching a run time error, I have to take a subset of 10% of the original particles. This gives me a similar image to the original, while still being able to be run on my laptop. To do this, I use numpy.random. An example of how to do this is shown below.
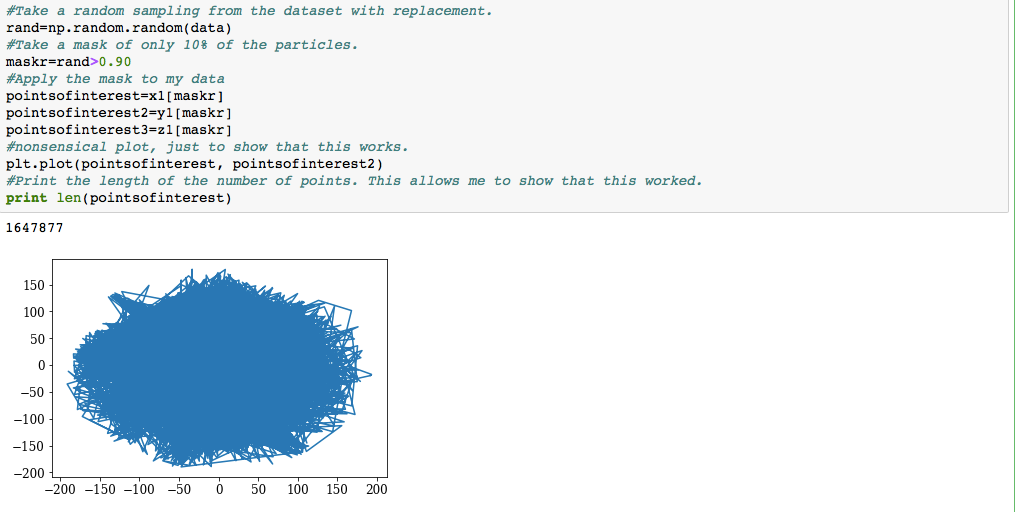 Image of my code.
Image of my code.
After I take the random particles, I create a mask of only 10% of the particles. This allows me to get my code to run in a quicker manner and allows me to maintain an accurate depiction of the dataset. These snapshots of the dataset provide valuable information and allows me to more quickly draw conclusions.
I hope you take the time to try this method out for yourself! Happy coding!
Thank you for reading!
How I Used Python To Make Big Data Seem Small was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.