Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Understanding how different words are related based on the context they are used is an easy task for us humans. If we take an example of articles then we read a lot of articles related to different topics. In almost all the articles where an author is trying to teach you a new concept then the author will try to use the examples which are already known to you, to teach you any new concept. In a similar way computer also needs a way where they can learn about a topic and where they can understand how different words are related.
Let me begin with the concept of language, these amazing different languages we have. We use that to communicate with each other and share different ideas.But how do we explain a language in a better way? Some time back I was reading this book “Sapiens”, where the author goes back and questions a lot of things and in that, his explanation of language was good:
We can connect a limited number of sounds and signs to produce an infinite number of sentences, each with a distinct meaning.We can thereby ingest, store and communicate a prodigious amount of information about the surrounding world.
This is all possible because of languages. As he writes we can produce an infinite number of sentences, that means words will have different meanings based on the context used. So rather than having a fixed definition for each word, we’ll be defining them based on their context. That’s the reason in programming we don’t use WordNet to find out the relationship between different words. WordNet is a library where you can get a collection of synonym sets for each word. Also, it contains hypernyms (‘is a’) relationships. It misses the nuance for example word ‘good’ has a lot of synonym sets but the context is missing. One more problem with WordNet is that it requires human labour to create and update.
We need a way where we can compare the word similarity. To compare it we need to represent the words in the form of vectors. We can represent them in the form of discrete symbols. Representing them as one-hot vectors like:
hotel = [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0]
So, the vector dimension will be equal to the total number of words in a vocabulary. Still, we can’t find the similarities between different words in this way as each word is represented differently and there is no way to compare. One way to fix that would be to use WordNet’s list of synonyms to get the similarity or what if we can add similarities in the vector itself?
The idea here is to create a dense vector for each word, chosen in such a way where it is similar to vectors of words that appear in similar context. Word2Vec is what we are going to use to create such a dense vector.
Word2Vec
Let’s say we are reading a book and our task is to learn how different words are related to each other. What we will do here is we’ll take a paragraph and we will go through each word. One word at a time, let’s call it a centre word. Then we have nearby words, let’s say there are five words in one sentence and centre word is the middle one then two words on the left side and two on the right are nearby words. These are also known as context words. Here we take two because we have a window of size two, it can be changed.
Here we will calculate the probability of a context word given a centre word or vice versa. Based on this probability we will adjust the word vectors and try to maximise the probability. This way we will get word vectors through which we will know if any two words are similar.
Word2Vec was introduced in 2013 by Mikolov et al. at Google on efficient vector representations of words. This is the abstract of the paper:
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high-quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.Model
Let’s go into the details. We are going to create a neural network with a single hidden layer. In input, we will pass one hot vector representing a word and in the output, we will get a probability of that word being near the centre word. This is one of that neural network where the actual goal is not the output that we get, in this case, we are interested in learning from the weights of the hidden layer. Output layer is required to decrease the loss.
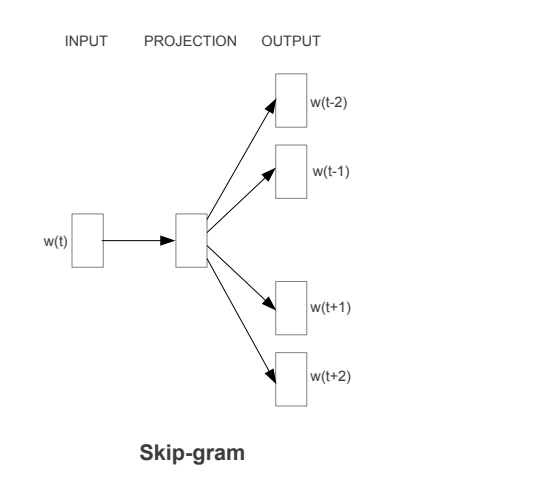 Figure 1: Skip-gram predicts surrounding words given the current word.
Figure 1: Skip-gram predicts surrounding words given the current word.
From figure 1 we can get a basic idea of different layers in the Skip-gram model. So, there were two architectures proposed: one is Skip-gram model and the other one is the Continuous Bag-of-Words model. In case of CBOW, we predict the centre word based on context words and in case of Skip-gram, it’s opposite. Also, it’s called bag-of-words model as the order of words in the history does not influence the projection. In this post, we will talk about Skip-gram model.
In mathematical terms its goal is to maximise the average log probability. Let’s say if the number of training words is T then this is the representation of average log probability:
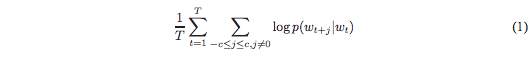


 Hidden Layer
Hidden Layer
In the above neural network architecture, you can see we have three layers and in that, we already know about the input and output layer. Let’s discuss the hidden layer in above architecture.
Hidden layer in this neural network works as a look-up table. So, let’s say if we have a one-hot vector with 1000 rows as an input and the hidden layer contains 30 features which mean a matrix of 1000 rows and 30 columns. When we multiply them then the output will be the matrix row corresponding to the 1.
Also, the features in hidden layer can be treated as hyper-parameters which you can tune it in your application. There is no restriction, so you can try different values.
The output from the hidden layer is what we call word vectors.We update them based on the output layer’s result.
Open source projects
If you want to use some prebuilt tools to create word representation then Facebook’s fastText is one of them.And this is Google’s implementation of Word2Vec where they used Google news data to train the model.
Liked the story? Hit that clap button and follow me on Medium. Thanks for reading! This article was originally published on Applozic Blog.
Understanding Word Embeddings was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.