Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In How to rebase safely for profit and pleasure I looked at various techniques to help address some of the difficulties you may encounter when rebasing a set of changes. Crucially what I didn’t talk about was why you might want to rebase a set of changes in the first place or what a great end result might look like.
First of all, the why
Developers often talk about “being in the zone”. Certainly it’s the case that some complicated problems require you to get into the right mindset and build a good mental model of the problem in order to be able to solve them effectively. This mindset is very different from the mindset that is needed to write good commit messages which for reasons we will discuss later should be focused on the narrative and less on the technical.
At the same time waiting until we have finished a job in its entirety so that we can take our code-wrangling hat off and put on our commit message writing hat is also problematic. We can end up in the undesirable situation where we have a working tree littered with updated, created and deleted files and it’s hard to pick apart the steps we’ve taken to get to the end result. Sometimes it is not even possible because a file has gone through several iterations of changes to get to the end result. We end up with a single massive commit, perhaps encompassing several smaller tasks, because it is too difficult to pick everything apart now that we have done it. This sucks for anyone who has to review your code and it sucks for you in 2 years time when you come across the commit in a git blame and have to decipher the mess again to understand why you made the changes you did.
 Can you quickly review my code for me?… Photo by Simson Petrol on Unsplash
Can you quickly review my code for me?… Photo by Simson Petrol on Unsplash
The solution to both of these problems is to commit small, commit fast and commit often. This means that you always have a small number of changes in each commit. If you are TDDing a good place to start is each new test and its associated code change in each commit. Committing fast means that we don’t waste time and risk losing momentum by worrying about the finer details of the commit message. We get just enough information in that we can identify the commit later and perhaps a little memory jog if there are some important specifics we think we might forget. In practice this means usually using the git commit -m "..." syntax for adding commits. This forces you to be brief. I usually prefix commits that I add in this way with a particular character ( — is my usual choice) so that I can identify them later. Committing often is a natural consequence of committing small. It should become part of your normal red-green TDD cycle.
Then once the problem is solved and you know the steps that were required to reach the solution, you are in a much better position to reorganise these into a coherent set of commits. In this sense it is like refactoring or performance optimisation. If you try and do it at the start, it is more likely that you refactor the wrong thing or add complexity optimising code that turns out not to be a bottleneck. It is only once the job is done you can identify the best way to improve it. Similarly with preparing a set of commits — it is only once you know all the changes that are required that you can identify the best way to structure them into coherent commits.
There are other reasons you may want to rebase your commits prior to merging them. Lots of things can happen whilst you are working on a job, not least the job itself may change. Perhaps this kind of thing may look familiar…
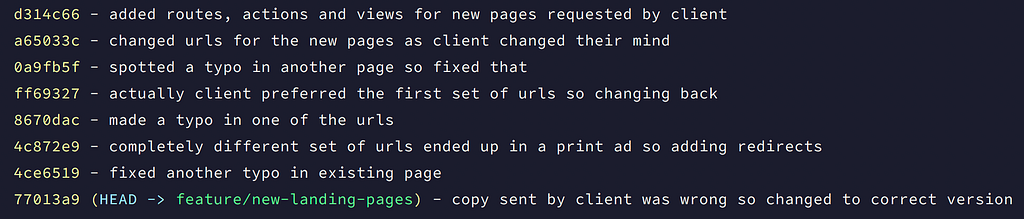
There’s a bunch of different jobs going on here and a lot of redundant information. It benefits no-one to keep all this in the commit log of the application. All that really needs to be kept is

It is important that your commit log contains the correct granularity of information. You want to maintain separate commits for separate tasks. At the same time, unnecessary commits will just get in the way when you are trying to track down the source of a problem.
Ultimately rebasing commits and rewriting changes is about efficiency. The aim is to trim away any cruft and distractions whilst ensuring that all the information needed to understand the set of changes is clearly and easily available.
Now the what
So what do good commit messages and pull requests look like? The first thing to recognise is that, like code, commit messages are written once and read many times. So in order to identify what makes a good commit message you need to consider who the audiences are that you are writing for. There are 3 key audiences that you need to think about.
You
The first person is yourself. One of the most useful parts of the rebasing and commit writing process is sorting the changes you have made into the different steps and tasks that you took. Here is where you take your code from good to great. Do you understand why each individual change within a commit was necessary? What does it achieve? Do your changes follow a logical progression? Now that it works could you do the same thing in a better way? Have you done everything that is required for the story? Have you missed any edge cases? Did you skip a test here or there? etc etc etc
You should be able to split your work into clear coherent chunks and then it should be easy to describe what you were trying to achieve and why you chose the solution you did.
If your commit includes lines that start with things like ‘Also changed…’ that’s a smell that you have bundled more than one change into the same commit
Your team
The next set of people you are writing for are your team. Assuming all your code goes up for code review — and it should — the easier you can make it for your team to understand your proposed changes the better it is for everyone. Coherent focused commits with an explanatory message mean that people can quickly and effectively review your code without getting bogged down in trying to figure out what is going on or why a particular change was required. It means you will get better feedback and your team mates will be more willing to review your changes because they will feel more like it will be a constructive and efficient use of their time.
Your commit messages should always focus on the narrative of the changes and not the the technical details. Anyone reviewing the code will be able to see the technical changes from the diff. If you are writing things like ‘Changed class X in file Y to call method Z` you are wasting everyone’s time as the diff says exactly that in a more precise and efficient manner. What is interesting is why did you do that particular change. Is there any context that may result in you choosing this solution over something that on the surface may be more obvious?
Your commits should guide the readers of your PR through the changes that you have made. If it is a complex set of changes they should be broken into separate steps so that it is easy to follow, even if it means that the same code gets modified in multiple commits throughout the PR. Reading through the set of commit messages on a PR should be sufficient to explain the “what” and the “why” of the changes. The final “how” should be explained by reading the code itself.
You again in 2 years or 5 years or 10 years
The final audience you are writing for is your future self. Imagine you are neck deep in git archeology trying to figure out how some code arrived in a particular state and this commit comes up. What would you want to know in order to understand why this set of changes was made in the way that it was?
Bear in mind that much of the context you may think is obvious now probably won’t be obvious then. The project that is consuming your life at the moment will be nothing but a distant memory, the painful 3 hour meeting you’ve just sat through hammering out different possibilities with the stakeholders will be long forgotten and all you will have to explain this set of changes is the paragraph or so at the top of the commit.
At this point, which of these would you rather see?
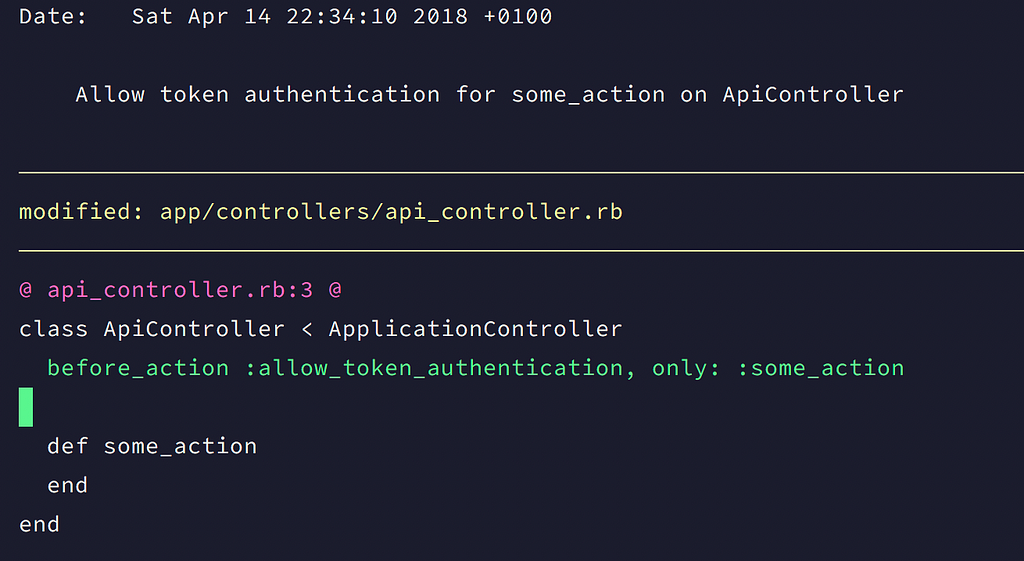 A completely useless commit message
A completely useless commit message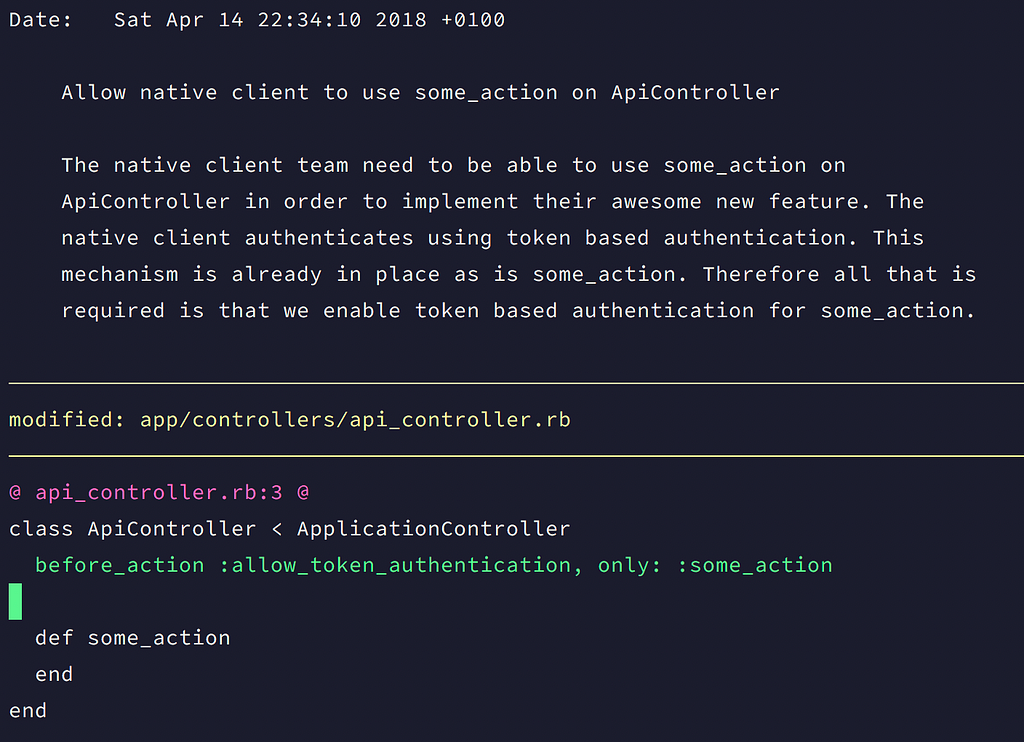 A commit message that might actually be of some use to some one
A commit message that might actually be of some use to some one
In order to write effectively for all of these different audiences you need to be able to take your time and focus on this as a separate task to writing the code itself. It is a very different skill and one that should be practised mindfully as it is as important a skill for developers as writing the code. At least bad code can be fixed later. This is why trying to do this whilst maintaining a code-writing mindset is futile and inefficient.
As a final note here are a couple of other things to consider when writing commit messages and pull request messages.
Commits are part of the repository, pull requests aren’t
If you want to reference previous changes it can be tempting to link to a pull request. However pull requests are not a feature of git, they are specific to the particular git hosting provider you are using at the time. If you change provider, all those links to PRs now become useless. It may be that one day a new super awesome git hosting provider appears on the scene that you would like to try. It is much better not to have to consider that losing all your pull request information is a big drawback or that your commit log will now contain lots of broken links.
There are two implications of this. The first is that you should link to commits rather than pull requests in commit messages. Reference them by SHA and let Github, Bitbucket or whatever tool you are using convert them to links. Then they will always work regardless of the tool you are using. The second is that all important information should be in the commit messages, not the PR message. Depending on how your provider handles merges, you may still end up with the PR message in the merge commit but it is still much better to have the important details with the relevant commits, even if this means repeating some information from commit to commit. This means that if the commit does show up in several years time as part of a git blame, the chances of the person seeing the information is greatly increased.
A pull request should tell a story
A pull request should have a clear goal that can be written as a narrative. In many ways it echoes the guidelines to writing a good agile story. It should have clear motivations and beneficiaries. It should be written from a business perspective and be as non-technical as possible. It’s a bit like the summary that appears on the back of a book. Then the commits are chapters within that story and the commit messages should read as such. Each one is a step towards achieving the overall goal laid out in the pull request. Finally the diffs provide the individual code changes that were required for each chapter.
Just as it is redundant to repeat all the information contained in the diff in the commit message, it is redundant to repeat the information in the commit messages in the pull request message. The pull request message should be aimed at code reviewers since this is its primary audience (quite possibly its only audience). It should be brief and non-technical. Don’t invest a lot of time in the pull request message as it is the most transient of all, save your energy for the commit message.
The exception here is when the pull request consists of a single commit. In that case the PR message should simply be the commit message, which most providers will do by default anyway.
So having looked at some of the motivations for using git rebase to prepare our pull requests and some examples of what to do, the next question is how to put that into action. For help with that, check out How to rebase safely for profit and pleasure.
The poetry of pull requests was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.