Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In this post I explain the work done in my paper “A Computational Approach to Feature Extraction for Identification of Suicidal Ideation in Tweets” accepted at the 56th Annual Meeting of the Association for Computational Linguistics. I look forward to presenting our work at the most prestigious conference on Natural Language Processing this July. Being a minority and underrepresented student, I’ve not had many chances to interact much with industry professionals or access to mentors that are working on projects at an international level who would help me explore further programs aligned with my interests and present our work that impacts millions of lives at such an enormous platform.
My main motivation for writing this post is to introduce students and professionals from the diverse communities that I am a part of, to Natural Language Processing for Humanitarian causes and the immense impact they can make in the world. This includes breaking the taboos and stigma revolving around mental health and suicide in particular, in developing countries. This post features a brief introduction, and more technical details can be found in our paper in ACL Anthology. Additionally, please feel free to contact me for any queries/help/doubts regarding this post. I’m always looking for ways to help other students get started, motivate them and give back to the community that has given me so much.
A Deeper Look into the problem
Technological advancements in the World Wide Web and social networks in particular coupled with an increase in social media usage has led to a positive correlation between the exhibition of Suicidal ideation on websites such as Twitter and cases of suicide. I don’t have to emphasise on the devastating impact suicide can have on families and the surrounding community, however, I feel there is a strong need to explicate the severity of this problem.
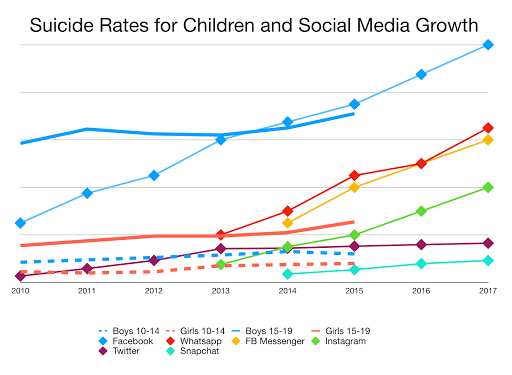
According to World Health Organization, suicide is the second leading cause of death among 15- 29-year-olds across the world. In fact, close to 800,000 people die due of suicide each year. The number of people who attempt suicide is much higher.
Many suicide deaths are preventable and it is important to under- stand the ways in which individuals communicate their depression and thoughts for preventing such deaths. Suicide prevention is mainly hinged on surveillance and monitoring of suicide attempts and self-harm tendencies.
Suicidal Ideation: The What
Suicidal ideation refers to thoughts of killing oneself or planning suicide, while suicidal behaviour is often defined to include all possible acts of self-harm with the intention of causing death.
A number of successful models have been used for sentence level classification, however, ones that are successful for being able to learn to separate suicidal ideation from depression as well as less worrying content such as re- porting of a suicide, memorial, campaigning, and support. etc, require a greater analysis to select more specific features and methods to build an accurate and robust model. The drastic impact that suicide has on surrounding community coupled with the lack of specific feature extraction and classification models for the identification of suicidal ideation on social media, so that action can be taken is the driving motivation for this work.
Formulating the Problem
Development of an accurate and robust binary classifier that can identify content on social media that may potentially hint towards suicide activity to prevent suicides and provide help. This involves:
- Creation of a dataset consisting of tweets exhibiting suicide ideation and those not exhibiting suicidal ideation and their annotation.
- Identification of features for text classification by the process of hand engineering and analysis in a supervised setting.
- Development of models based on features selected in phase-2 and exploration of deep learning approaches such as RNN, CNN-LSTM to the problem.
In the following article, I will cover the technical aspects of each of these subproblems in depth.
Data: Collection and Annotation
Anonymised data was collected from microblogging website Twitter — specifically, content containing self-classified suicidal ideation (i.e. text posts tagged with the word ’suicide) over the period of December 3, 2017 to January 31, 2018. The Twitter REST API2 was used for collection of tweets containing any of the following English words or phrases that are consistent with the vernacular of suicidal ideation.
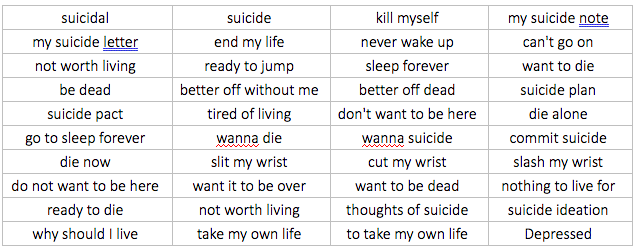
Then, text posts equaling 5213 in all were collected which were subsequently human annotated. Human annotators were asked to indicate if the text implied suicidal ideation using binary criteria by answering the question Does this text imply self-harm tendencies or suicidal intent?
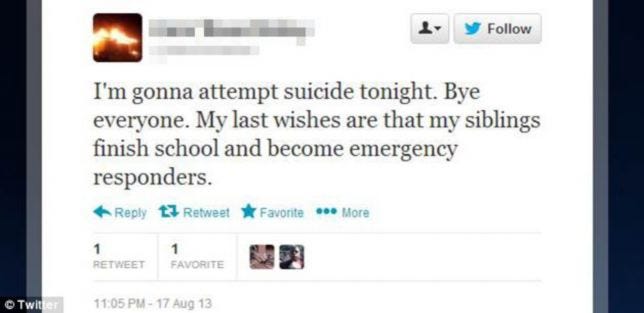
Tweets with suicidal intent present show a clear indication of suicidal tendency and are different from flippant references, condolences, news etc. The tone of text is sombre and also includes posts encompassing future plans of attempting suicide. These tweets make up 15.76% of the dataset.
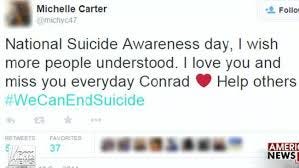
Tweets with suicidal intent absent include news, reports, condolences, suicidal awareness, flippant references and are the default category for tweets.
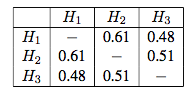 Cohen’s Kappa for Interannotator agreementProposed Methodology: The Pipeline
Cohen’s Kappa for Interannotator agreementProposed Methodology: The Pipeline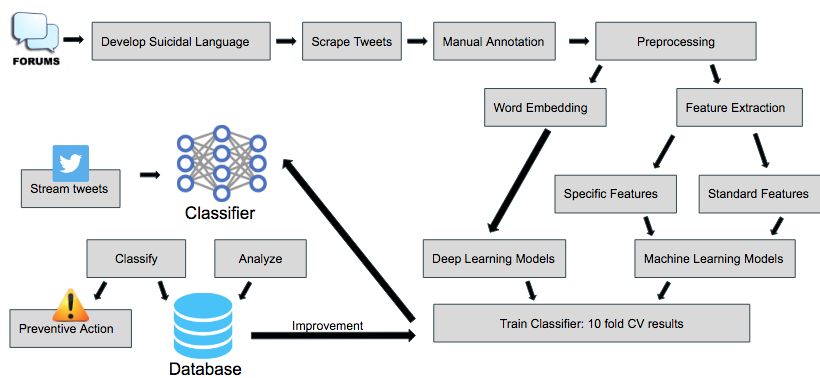 Preprocessing
Preprocessing
Preprocessing is achieved by applying a series of filters in the order given below to process the raw tweets.
- Removal of non-English tweets using Ling- Pipe with Hadoop.
- Identification and elimination of user mennions in tweet bodies having the format of @username, URLs as well as retweets in the format of RT.
- Removal of all hashtags with length > 10 due to a great volume of hashtags being concatenated words, which tends to amplify the vocabulary size inadvertently.
- Stopword removal.
Feature Design and Extraction
Tweets exhibiting suicidal ideation lack a semi-rigid pre-defined lexico-syntactic pattern. Hence, they warrant the use of hand engineering and analysing a set of features in contrast to sentence and word embeddings in a supervised setting using Deep Learning Models.
 Description of Feature Design and Classifiers
Description of Feature Design and Classifiers
One of the most important features are the LIWC Features. Linguistic Inquiry and Word Count program (LIWC) is a transparent text analysis program that counts words in psychologically meaningful categories. Empirical results using LIWC demonstrate its ability to detect meaning in a wide variety of experimental settings, including to show attentional focus, emotionality, social relationships, thinking styles, and individual differences.
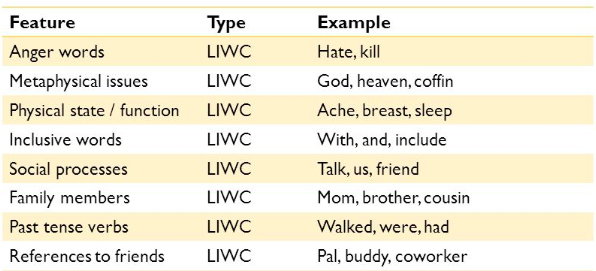
Suicidal Ideation detection is formulated as a supervised binary classification problem. For every tweet t ∈ D, the document set, a binary valued variable y ∈ {0, 1} is introduced, where y = 1 denotes that the tweet t exhibits Suicidal Ideation. To learn this, the classifiers must determine whether any sentence in ti possesses a certain structure or keywords that mark the existence of any possible Suicidal thoughts. The features presented above are the used to train classification models to identify tweets exhibiting Suicidal Ideation. Linear classifiers such as Logistic Regression as well as Ensemble Classifiers including Random Forest Gradient Boosting Decision Tree and XGBoost are employed for classification.
Deep Learning for Suicidal Ideation
Deep Learning architectures show promise in Sentence level classification when clubbed with word embeddings. Two models, Vanilla-RNN and subsequently CNN-LSTM(The CNN LSTM architecture involves using Convolutional Neural Network (CNN) layers for feature extraction on input data combined with LSTMs.) were used. The motivation for using these models was their ability to capture long term dependencies in text. The architecture for the Vanilla RNN is shown here. Vanilla RNN doesn’t perform very well due to the vanishing gradient problem, and thus becomes inefficient to learn long distance correlations in tweets. CNN-LSTM was used specifically to alleviate the problems in an RNN using an LSTM to capture long term dependencies with relatively more insensitivity to gap length unlike RNN. CNN was used to extract features more efficiently from word embeddings.
Baselines
Validation of the proposed methodology is done by comparison against Baseline models that act as a useful point for comparison. More on these is explained in the results below. Accuracy, Precision, Recall and F-1 Score are the evaluation metrics used for comparison.
Results and Analysis
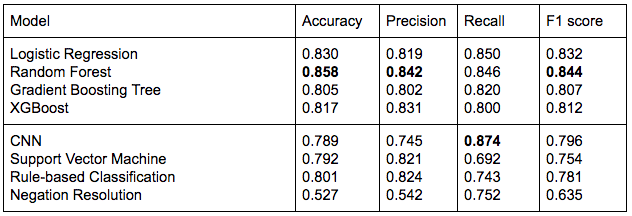
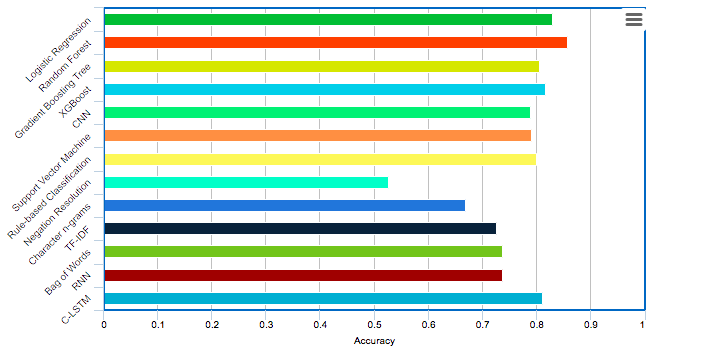
The proposed features used in conjunction with the first four models described in the Classification section supersede the baseline models in terms of performance along most metrics. The LSTM model has the highest recall, owing to its abil- ity to capture long term dependencies, however its overall performance in terms of accuracy and F1 score is relatively less. Both SVM and Rule- based classification don’t perform as well as the proposed methodology, owing to the lack of fea- tures used in these models that are not suitable for learning how to classify tweets with Suicidal Ideation. Both of these methods are more suit- able in a general domain, however, the features in the proposed methodology are more specific to the particular problem domain of Suicidal Ideation detection, particularly the LIWC features and Top- ics probability. Lastly, the Negation Resolution method performs poorly on the dataset, due to its inability to adapt to a vast and highly diverse form of suicidal ideation communication and its implicit rigidity. This in comparison to the pro- posed methodology, is unable to effectively learn and extract the essential features from input text, and thus does not perform as well.
While the performance of the four classifiers is comparable, Random Forest classifiers perform the best. This is attributed to the ability of Random Forest classifiers that tackle error reduction by reducing variance rather than reducing bias. As has been seen with various text classification problems, Logistic Regression per- forms fairly well despite its simplicity, and has a greater accuracy and F1 score in comparison with both Boosting Algorithms.
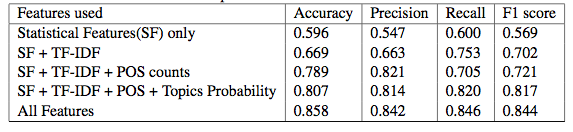
The table above shows the variation in performance of the Random Forest classifier with the inclusion of the various features. The precision reduces by a small amount with the inclusion of Topics prob- ability feature implying that a greater subset of tweets is classified as suicidal due to the LDA unigrams included via Topics probability features, but is finally boosted by the inclusion of the LIWC features. The POS counts also lead to a reduction in the recall, which is compensated with the sub- sequent inclusion of Topics Probability and LIWC features. The drastic improvements are attributed to the TF-IDF, POS counts and LIWC features in terms of most evaluation metrics. It is observed that the proposed set of features perform the best in conjunction with Random Forest classifiers, and the improvement in performance with the inclusion of each feature validates the need for the extraction of that feature.
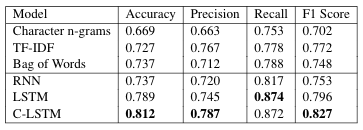
Via Deep Learning, we infer that baselines perform poorly, RNN also performs poorly. LSTM shows promise in capturing long term dependencies given greater recall. CNN-LSTM uses greater feature extraction and gives a overall performance.
Detailed Analysis
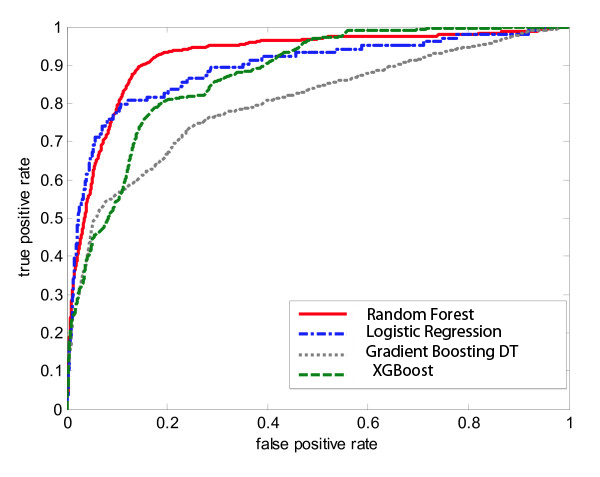
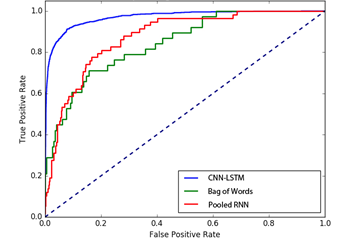
Receiver Operating Characteristics
ROC and AUC analysis was conducted given the imbalance in the dataset and measuring the sensitivity and specificity. Random Forests and CNN-LSTMs supersede performance as in terms of accuracy. Surprisingly GBDT performs poorly.
Top features
Top features were analysed using Chi-Squared test based ranking to identify helpful features for future classification problems and eliminate redundant features. LIWC and POS features though small in dimension have huge contributions.

A user interface was also developed to identify and analyse trends in tweets that were being streamed live.
RF wins due to ability to reduce variance which is very important in suicidal tweets given their diverse nature. CNN-LSTM is a close second. Work supersedes current state of the arts on the same dataset. Greater validation may be needed as we incorporate more data, which our model aims to do.
- Seemingly Suicidal tweets: Human annotators as well as our classifier could not identify whether “I want to kill myself, lol. :(” or “Haha just kill me now” were representative of suicidal ideation or a frivolous reference to suicide.
- Pragmatic difficulty: The tweets “I lost my baby. Signing off…” or “Cancer killed my wife. I will go too now.” were correctly identified by our human annotators as a tweet with suicidal intent present. This tweet contains an element of topic change with no explicit mention of suicidal ideation, but our classifier could not capture it.
- Ambiguity: The tweet “Is it odd to know I’ll commit suicide?” is a tweet that both human annotators as well as the proposed methodology couldn’t classify due to its ambiguity.
- High fluctuation: Tweets reflecting multiple mood swings and fluctuations are difficult for both the classifier and human annotators, e.g., “I need to kill myself now, Hahaha, no seriously. I’ve had enough 🙂”.
- Strict Feature Reduction: Assigning a large weight to the penalty function reduces computation and improves overall accuracy but leads to incorrect classification of tweets hinting subtly towards suicidal ideation such as “It is time to sleep forever.. by eliminating uncommon features in the dataset.
Ethics
Two main issues were addressed:
- Individual consent from users was not sought as the data was publicly available and attempts to contact the Twitter account holder for research participation could be deemed coercive and may change user behaviour.
- Psychological support was not offered to those Twitter users who appeared to be at-risk as intervention via Twitter as it may not be appropriate. This is due to several reasons: suicide risk fluctuates; uninvited contact with participants is an invasion of privacy; such contact could lead to unsolicited attention; and most importantly, the main aim of this study was to determine whether it was possible to categorise tweets in this way, rather than to immediately assume the coding was accurate.
I accept that Internet research for suicide prevention is complex, and in its infancy, and believes that there is a dire need for scientifically valid data before uninvited contact with individuals is made.
Limitations
In order to improve the reliability and accuracy of the automatic classifier, future efforts would benefit from expanding the range of suicide-related search terms to ensure that more expressions of suicidality are included. Future modelling should attempt to normalise words by removing prefixes and suffixes, incorporating regular expressions and by analysing adjacent sequences of words as well as the words themselves, since as rare words or expletives may represent greater risk of suicide. As stated, the current methods were unable to clearly discern, beyond a required level of accuracy, those who were experiencing passive suicidal ideation from those who were in immediate danger of taking action. The current study did not attempt to validate the risk of suicide with offline measures, such as family and friends, standardised questionnaires or clinical consultation. The Twitter data used in this study was also unable to provide sample characteristics, such as age and gender, which limits the generalisability of results.
Conclusion and Future Work
This paper proposes a model to analyse tweets, by developing a set of features to be fed into classifiers for identification of Suicidal Ideation us- ing Machine Learning. When annotated by humans, 15.76% of the total dataset of 5213 tweets was found to be suicidal. Both linear and ensemble classifiers were employed to validate the selection of features proposed for Suicidal Ideation detection. Comparisons with baseline models em- ploying various strategies such as Negation Resolution, LSTMs, Rule-based methods were also performed. The major contribution of this work is the improved performance of the Random forest classifier as compared to other classifiers as well as the baselines. This indicates the promise of the proposed set of features with a bagging based approach with minimal correlation show as com- pared to other classifiers.
Some of the future work entails:
- Create social network graphs and analyse communication and communities.
- Incorporate user history and past activity to improve robustness.
- Expand to more social media and web forums to capture wider target audience.
Suicide Prevention by Detection: Leveraging AI on Social Media was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.