Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Research Paper (Scalable Deep Reinforcement Learning for Robotic Manipulation by Alex Irpan, Software Engineer, Google Brain Team and Peter Pastor, Senior Roboticist, X) Explained
Google is famous for their cutting edge technology and projects including Self Driving Car, Project Loon (Internet balloon), Project Ara and the list goes on. But alot of research goes behind the scenes, which yields in some interesting research papers that literally gives us access and insight on these fun experiments. Encouraging us to replicate the experiments by ourselves and build further to push the boundaries.
 Project Ara | Source
Project Ara | Source
The Learning Robots Project by GoogleX has published QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation that tries to master the simple task of picking and grasping different shaped objects. Aiming to replicate some common human activities.
 Source (Look at robot no. 6 learning stuff)
Source (Look at robot no. 6 learning stuff)
And the success rate is fascinating.
This experiment uses 7 robotic arms that ran 800 hours at a course of 4 months to grasp objects placed infront of them. Each uses a RBG camera (image above) with a resolution of 472x472. The closed-loop vision-based control system is based on a general formulation of robotic manipulation as a Markov Decision Process (MDP).

 Same objects with Different Colours | Source
Same objects with Different Colours | Source
To be efficient, Off-policy Reinforcement Learning is used which has the ability to learn from data collected hours, days or even weeks ago.
The Qt-Opt algorithm is designed by combining two methods:
1.Large-scale Distributed Optimization (using multiple robots to train model faster, making it a large-scale distributed system)
2.Deep Q-learning algorithm ( RL technique used to learn a policy, which tells an agent which action to take under which circumstances)
What is Qt-Opt?
QT-Opt is a combination of large-scale distributed optimization and Q-learning algorithm resulting in Distributed Q-learning algorithm that supports continuous action spaces, making it well-suited to robotics problems.
To make the robot not go crazy at their initial attempts, the model is initially trained with offline data which doesn’t require real robots and improves the scalability.
For this case, the policy takes an image and returns the sequence on how the arm and gripper should move in 3D space.
RESULTS
The results gives a unbelievable 96% grasp success rate.
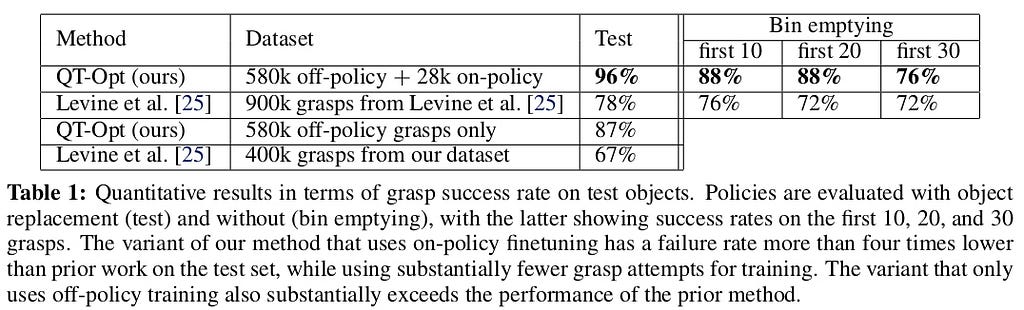
The model learned many new things that are sophisticated and borderline humane.
1.When blocks are too close to each other and there is no space for the gripper, policy separates the blocks from the rest before picking it up.

2.Swatting objects from gripper were not the part of dataset but it automatically repositions the gripper for another attempt.

I encourage you to read the research paper for more insight.
Follow me on Medium and Twitter for more #ResearchPaperExplained Notifications.


If you have any Query about the paper or want me to explain your favourite paper, comment below.
Clap it… Share it…. and Clap it again.
Previous Stories you will Love:
- DeepMind’s Amazing Mix & Match RL Technique
- Playing ATARI with 6 Neurons | Open Source Code
- 50 TensorFlow.js API Explained in 5 Minutes | TensorFlow.js Cheetsheet
- TensorFlow on Mobile: Tutorial

Google X’s Deep Reinforcement Learning in Robotics using Vision was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.