Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
This article is for all those times when the data you’re getting isn’t the data you’re wanting.
Allow me to outlay a contrived example, based on a few true stories.
Let’s say I’m building a new website in an organisation that has been around for a while. There are already some REST endpoints lying around, but they’re not exactly tailor made for what I want to build.
I’m going to zero in on the endpoints I need just to authenticate a user and get some details about them:
- /auth: this will authorise a user and return a token
- /profile: this will return basic information about the user
- /notifications: this will return all unread notifications for the user
For the use of my app, let’s imagine that I will never want these separately, so ideally they’d be a single endpoint.
But my problems reach further than simply having too many endpoints. The data that’s returned by these endpoints is a little bit terrible.
For example, the /profile endpoint was written in simpler times, and written in NotJavaScript, so it’s got prop names only a mother could love:
Gross.
And the /notification response makes the /profile response look like Shirley Temple.
Oh my, that list of messages is an object, not an array. And there’s the same complex representation of a user, oh and that timestamp appears to show seconds since the start of 1970 — surprise!
If I was to draw a picture of this situation, it would look a helluva lot like this, with red signifying the crappy state of the data.
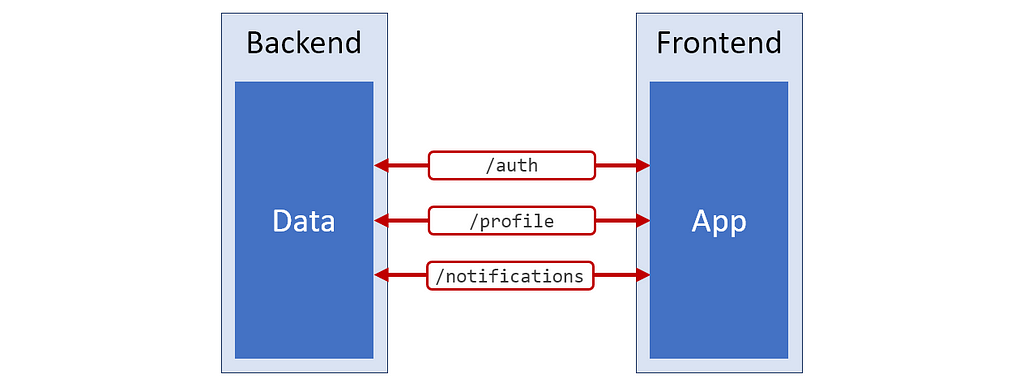
Now, I don’t have to do anything about this situation. I can just load these three APIs and use the data that I’m given. If I want to render the user’s full name on the screen, then I’ll combine Christian_Name and Surname when I need to.
(A side note about names. The idea that a person’s name can be split into two parts — and that the first part can be used as an informal name — is a very Western concept. If you want to be internationally loved, I urge you to consider a person’s name a single string, and do away with any assumptions about how you can break this up into smaller chunks for varying levels brevity and informality.)
Back to my non-ideal data structure. The obvious problem with concatenating data in my UI code is that I might need to repeat this action in a few places. A small problem if I do it a small number of times, a big problem if I do it a big number of times. That’s some wise shit right there.
Problem two is that I’m creating complexity in my UI code. In my opinion, UI code should be as simple and as readable as humanly possible. The more inline data manipulation I have, the greater the complexity, and — as I’ve said before — complexity is where the bugs hide.
The third problem is about types. For one thing, in the above examples, message IDs are strings, but user IDs are numbers — there’s nothing technically wrong with that, but it’s confusing. And what about that date! And that profile photo mess — all I want is the URL of the photo, darn it.
If I manipulate this data as I pass it down into my UI code, then in any given modules, it will be unobvious exactly what it is that I’m dealing with. Changing the shape and type of my data as I pass it around is mental overhead that I could be living without.
(I could implement a static typing system to address this problem, but strongly typed bad code is still bad code.)
So, having spent what feels like a really long time trying to convince you of a problem, let’s talk solutions.
First prize: change the APIs
If the current state of the APIs have no real reason to be so terrible, then creating a /v2 set of endpoints that better suit current requirements might be the best solution.
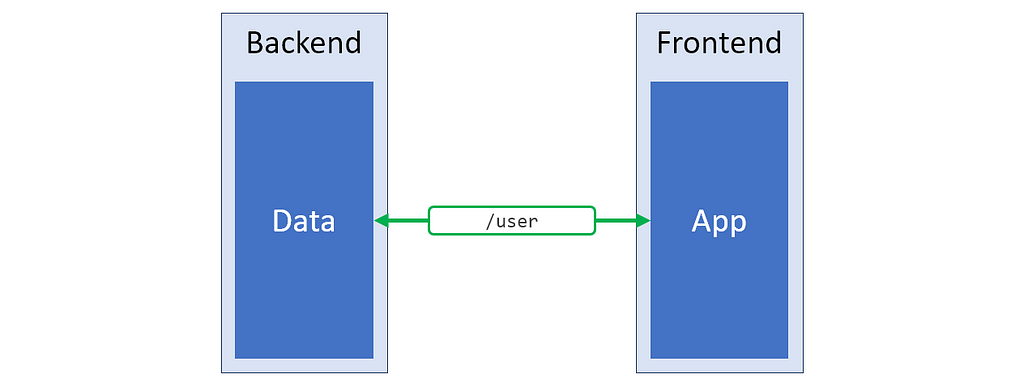 Green = real nice data structure
Green = real nice data structure
When starting a new project with imperfect APIs, I will always ask if this is an option. But there’s occasionally a very good reason that APIs are the way they are, or it’s simply out of scope to change the way they work.
In which case, I will try for …
Second prize: a BFF
Ah, the good old BFF. The backend-for-the-frontend.
With a BFF, I can abstract away those goofy general-purpose REST endpoints, and provide the payload perfection that my new frontend deserves.
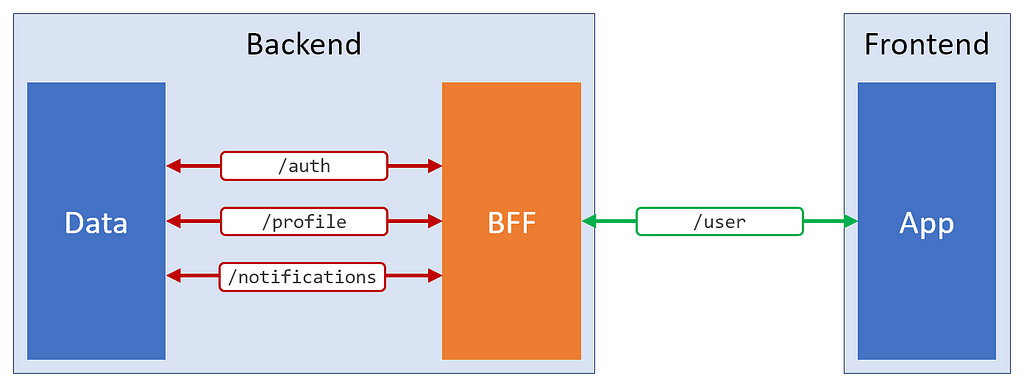 A caption for the image above
A caption for the image above
A BFF’s raison d’être (sorry) is to please the frontend. Maybe it serves up more REST endpoints, or a GraphQL service, or web sockets or whatever. The point is, it’s there to serve the needs of the UI.
My favourite architecture (yes I have a favourite) is a NodeJS BFF where frontend developers can roam free and create the perfect APIs for the frontend they are building. Ideally, it sits right within the same repo as the rest of the frontend code, so sharing logic between the frontend and the backend is easy (e.g. validating submitted data).
This also means that doing a task that requires frontend changes and API changes will take place in the same repo. Small things, but nice things.
In the scenarios where this isn’t possible, then I must settle for …
Third prize: The BIF
A Backend In the Frontend takes the same logic that you might have in a BFF (combine APIs and clean data), and moves it into the frontend code.
(Is BIF a stupid name? Yes. Did this even need a name? No. Has this been done before, 20 years ago, and already has a name? Yes, that seems to be how these things go.)
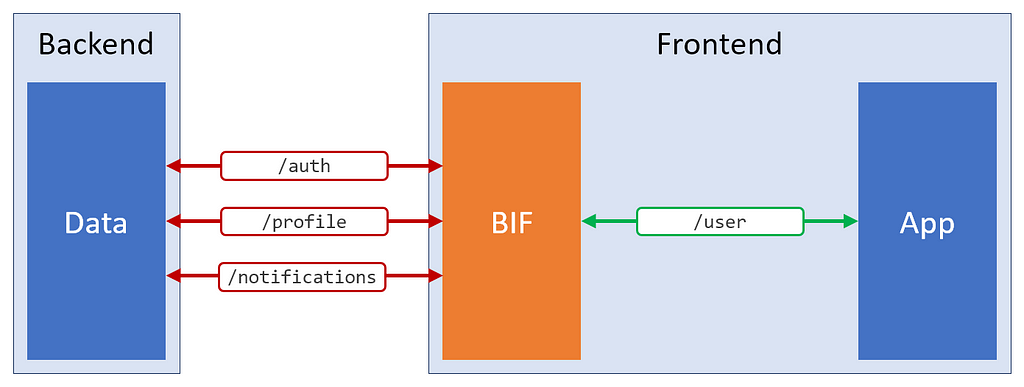 I like the font style of these image captions. Small, but not too small. Light, but not too light.What is this really?
I like the font style of these image captions. Small, but not too small. Light, but not too light.What is this really?
As suggested in the title, this is a pattern — a way of thinking about and organising code. It doesn’t remove any logic, it just separates logic of one type (modifying data structures) from logic of a different type (rendering UI).
This must be the ‘separation of concerns’ I keep hearing about.
Now, although this is nothing earth shattering, I’ve seen it not done plenty of times, so I figure maybe some people would find it helpful to see it all laid out.
You can think of the BIF code as code that you could one day lift out and put on a Node server and everything would still work just the same. (Or even move it into a private npm package that’s shared between multiple frontends in your organisation — exciting!)
You will recall from earlier that I’ve got two problems: too many API calls, and a data structure I don’t like.
These will be handled by one file each and so, for this contrived example, my entire BIF will consist of just two files (and a test).
First …
Combining API calls
Making multiple API calls in my app code is not such a big deal. But still, I’d like to abstract these out so that I can make a single ‘request’ (from my app to the BIF) and get back the data in the perfect shape.
Of course, I can’t help the fact that I must make three HTTP requests, but the app doesn’t need to know about this.
My BIF is going to expose its API as functions. So when my app wants to get some user data, I will call getUser(), which will return the user data.
First I make a request to the auth service to get a token I can use to authorise the user (let’s not worry about how this happens, we’re in imagination land).
Once I have that token I can make two calls simultaneously to get the profile and notification data.
Check out how sexy async/await with Promise.all and destructuring syntax is. Hubba hubba.
If async/await could get enough time off work, I’d take it on a romantic trip around the world.
OK so that was step one, to abstract away the fact that this is three network requests. But you will have noticed the call to parseUserData.
Let’s talk about that.
Cleaning the data
I have one recommendation that I think makes all the difference when first implementing a BIF — particularly on a new project: forget about the data you get for a moment and think about what data your app needs.
Don’t be clever and try and plan for how the app might behave in 2021. Just make it ideal for today (over-planning for the future is the #1 cause of over-complexity).
OK, getting back to it. I know what the incoming data looks like from those three APIs, and I know what the ideal output of this parsing process should look like.
It would seem that this is one of those rare cases where TDD actually makes sense. So, let’s write a big long test!
I have a special button on the side of my computer labelled “make tests work” — so I just hit that and the following code magically appears in my editor:
I tell you what, (if I may be serious for a moment) there is something really satisfying about pulling out 200 little data-modification snippets scattered all about an application, putting all that logic in one file, and having it properly unit tested and commented.
I mentioned earlier that a BFF is my preferred method for combining/cleaning data, but there’s one area in which the BIF has it beat: the data returned to the app can have JavaScript objects that aren’t supported in JSON, like Date or Map (the most underused thing in JavaScript).
So, in this case, I’m converting the date that came from the server (expressed in seconds since 1970) into a JavaScript Date object.
And that’s all there is to it.
Is this something I should think about doing?
Attractive and good at questions!
I’d suggest this: go cruising through your UI code with the following thoughts rattling about in your mind:
- Am I combining properties together that are never used separately (e.g. first name and last name)?
- Am I putting up with PascalCase? (You deserve better.)
- Are IDs sometimes strings, sometimes numbers, or otherwise confusing?
- Are dates sometimes a Date object, sometimes a number, and maybe even a string?
- Am I often checking if a property exists and is an array before looping over it to render UI? Could that not be an array — sometimes empty — in all cases?
- Am I sorting/filtering an array that ideally would have been sorted/filtered correctly in the first place?
- Am I checking for the existence of a property and falling back to some default value if it doesn’t exist (for example a placeholder image URL)?
- Am I using properties with different (perhaps old) terminology, mixed in with properties that use different terminology, but they represent the same thing?
- Am I passing around properties of an object that are never used, because they came in from the API? Is the extra clutter when inspecting what’s going on making me sad or anxious?
If one or two of these things are happening in your code, I wouldn’t fix what ain’t broke and I thank you for reading this far.
But if you’re fiddling with data all over the shop, and it makes your code harder to think about, or harder to test, or more likely to harbour bugs, then I reckon you should get yourself a BIF.
One last word of praise for the humble BIF is that for an existing application it’s easy to implement in little steps. You can set up a parseData function that mostly just passes data straight through. Then bit by bit, you can move logic out of your UI code and into this function — perhaps something to do on Tidy Fridy, or TODO Toosday.
Thanks for reading. Seriously, I mean it.
And for all my cryptocurrency readers that aren’t web developers that have been wondering for the last 9 minutes what on earth is going on: hi!

Backend-in-the-frontend: a pattern for cleaner code was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.