Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Hi reader!
A note to the reader:This article presumes that you are unreasonably fascinated by the mathematical world of deep learning. You want to dive deep into the math of deep learning to know what’s actually going under the hood.
Some Information about this article:
In this article we’ll discuss and implement RNNs from scratch. We’ll then use them to generate text(like poems, c++ code). I am inspired to write this article after reading Andrej Karpathy’s blog on “The Unreasonable Effectiveness of Recurrent Neural Networks”. The text generated by this code is not perfect, but it gives an intuition about how text generation actually works.
Let’s dive into the mathematical world of RNNs.
So What is the basic structure of RNN?
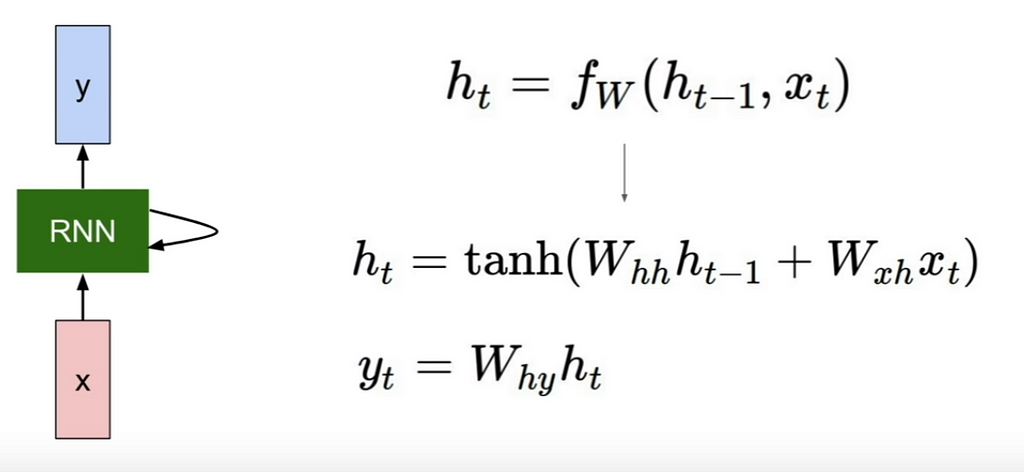 Fig 1 :Vanilla RNN
Fig 1 :Vanilla RNN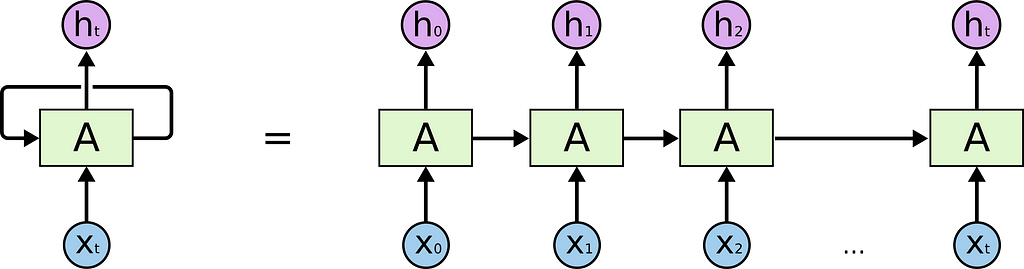 Fig 2: Unrolled Vanilla RNN
Fig 2: Unrolled Vanilla RNN
Don’t worry about any of the terms. We’ll discuss each of them. They are pretty easy to understand.
In Fig 1:
h(t): hidden state of RNN at time t=t
fw: non-linearity function(mostly tanh)
Whh: randomly initialized weight matrix. It is used when we move from h to h (hidden state to another hidden state).
Wxh: randomly initialized weight matrix. It is used when we move from ‘x’ to ‘h’ (inputs to hidden states).
Why: randomly initialized weight matrix when we move from ‘h’ to ‘y’ present hidden state to output.
bh(not in the photo): randomly initialized column matrix as bias matrix to be added in calculation of h(t).
by(not in the photo): randomly initialized column matrix as bias matrix to be added in calculation of y(t).
CODE:
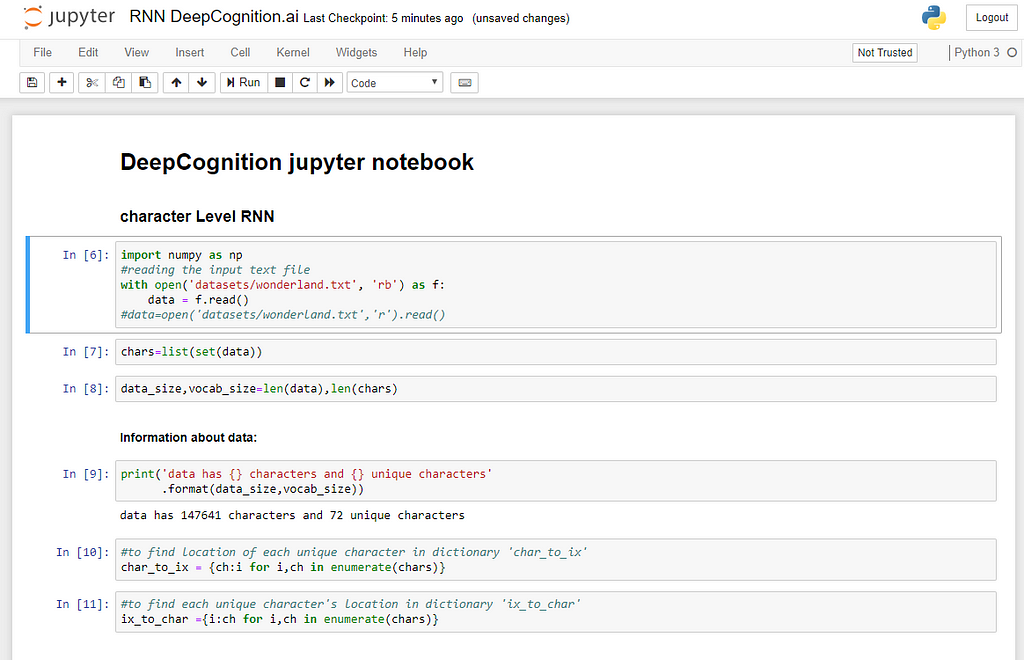
We start by importing data:
download data from here.
char_to_ix: it's a dictionary to assign a unique number to each unique characterix_to_char:it's a dictionary to assign a unique character to each number.We deal with assigned number of each character and predict number of next character and then use this predicted number to find the next character.
hidden size: number of hidden neurons
seq_length: this refers to how many previous immediately consecutive states we want our RNN to remember.
lr: stands for learning rate.
Initialize the parameters:
Initialize the parameters we discussed above(Whh …… by).
Forward Pass:
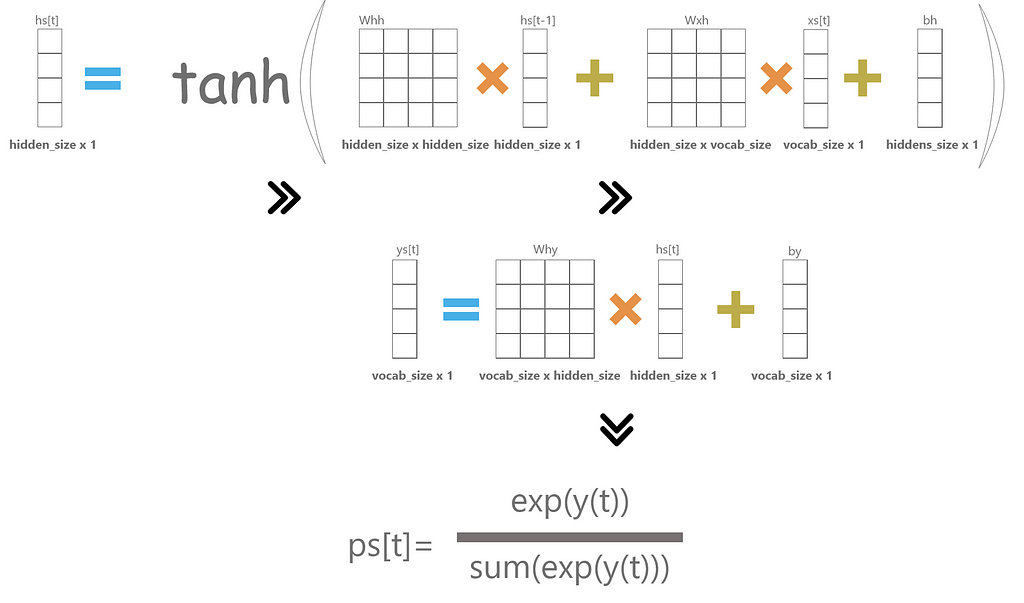
xs, ys, hs, ps are dictionaries.
xs[t]:At time(character) t=t, we use one-hot encoding to represent characters that is all the element of the one-hot vector are zeros except one element and we find location of that element(character) using char_to_ix dictionary. Example: assume that we have data as ‘abcdef’. We represent ‘a’ by using one-hot encoding as
this is what we are doing in 25th,26th line in the code above.a=[[1], [0], [0], [0], [0], [0]]
ys[t]: At time(character) t=t,we store the final output of that RNN cell.
hs[t]: At time(character)t=t, we store the hidden state of the present RNN cell.
ps[t]: At time(character)t=t, we store the probability of occurrence of each character.
As you see in the above code, we implemented simple calculations as given in Fig1 for xs[t], ys[t], hs[t], ps[t].
And then finally we calculate the softmax loss.
 Forward PassBackward Pass
Forward PassBackward Pass
dWxh : derivative w.r.t matrix Wxh. We will use this to correct our Wxh matrix. And similarly dWhh, dWhy, dbh, dby, dhnext.
To backprop into y: we subtract 1 from probability of occurrence of correct next character because:
 stanford CS231N notes
stanford CS231N notes
Now:To calculate:dy: ps[t]-1
dWhy += : dy•hs[t].Tdh += Why.T•dy + dhnext
dby += dy (As matrix multiplication term becomes zero in derivative )
#backprop in hs[t] now:dhraw adds derivative w.r.t tanh(derivative of tanh is 1-tanh^2)dhraw= (1-hs[t]^2)*dh
dbh += dhraw (because derivative matrix multiplication terms is zero w.r.t dbh)dWhx += (dhraw•xs[t].T)dWhh += (dhraw•hs[t-1])finally:dhnext += (Whh.T•dhraw)
Everything is setup:
It’s time to run program: DeepLearning Studio
RNNs are computationally very expensive. To train our program I used Deep Cognition’s Deep Learning Studio. It provides preinstalled DeepLearning Frameworks such as Tensorflow-gpu/cpu, keras-gpu/cpu, pytorch…and many more. Check it out here.
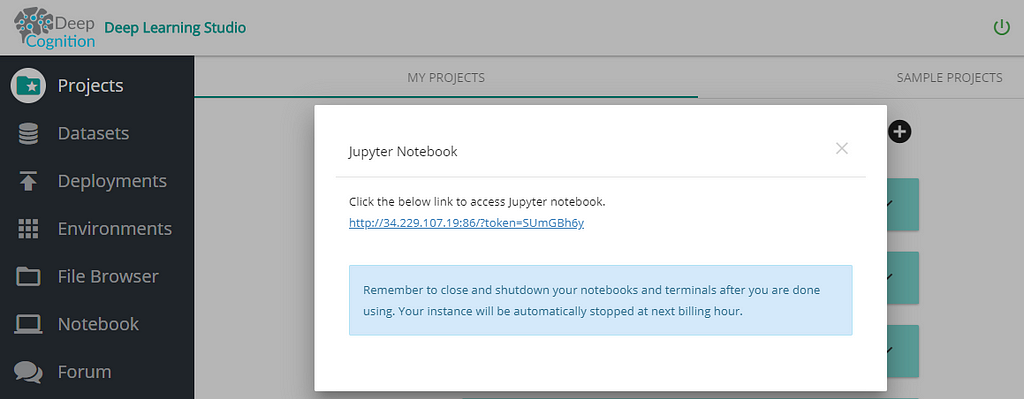
 click on Notebooks and you’re ready to code! ✋
click on Notebooks and you’re ready to code! ✋
DeepCognition - Become an AI-Powered Organization Today
mbh,mby are memory variables for Adagrad optimiser.
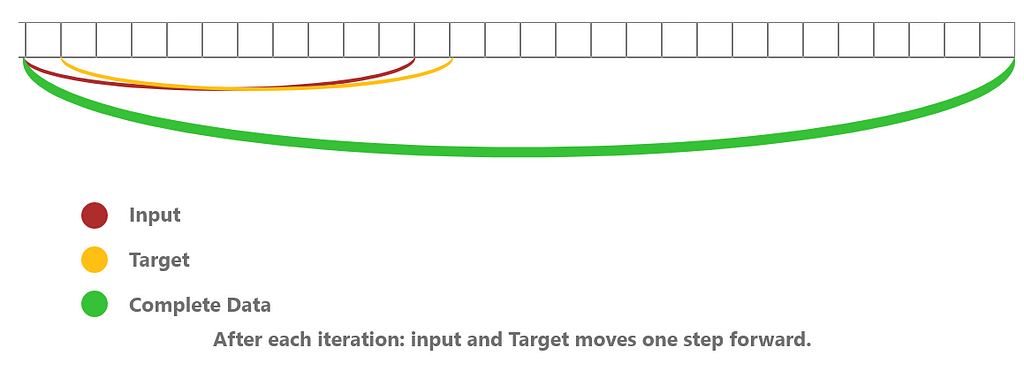 For line number 7–11. Here one-step = seq_length.
For line number 7–11. Here one-step = seq_length.
Finally loss is calculated from our loss function for different parameters(Why…h(t)) and is subtracted from respective parameters.
line number 5-6 is the way we Adagrad works.Like in normal gradient descent we do:theta= theta-lr*grad1e-8 is used to prevent DivisionByZero exception.
Results of Training: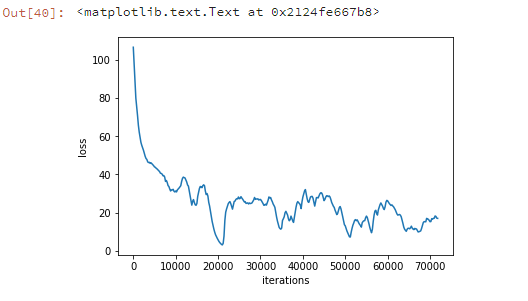
At epoch zero:Generated textloss=106.56699692603289iteration:0
QZBipoe.Mprb’gxc]QXECCY“f);wqEnJAVV-Dn-Fl-tXTFTNI[ ?Jpzi”BPM’TxJlhNyFamgIj)wvxJDwBgGbF!D“F‘bU;[)KXrT km*;xwYZIx-AXdDl_zk(QlW(KolSenbudmX.yqH-(uPUl-B:mj]o’E-ZTjzH)USf:!sCiTkTMcmgUY)rCjZaL*rhWVpS-------------------------------------------------------l was beginning begiginning to Alice walicegininn to geteginninato giteginniito geteginninn to geteginninatg gegeginninasto get beginninnninnigw to gicleaaaa was ginniicg benning to get a wen----loss=11.115271278781561iteration:66200
It begins to learns words like ‘beginning, Alice, was, to, get…’. It’s not perfect at all. But it gives an intuition that we can generate proper text, given some sample data. LSTMs performs much better than RNNs. LSTMs are an extension of RNNs with 3–4 gates. Do check my article on LSTMs
Understanding architecture of LSTM cell from scratch with code.
Access to the complete code with datasets on github repo.
Congrats to the reader, now you know in-depth mathematics of RNNs(simple linear Algebra).
Thanks for giving your precious time for reading my article. If you really liked it, do share and clap 👏.
Follow me on medium and LinkedIn.
Happy Deep Learning.

Generate stories using RNNs |pure Mathematics with code|: was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.