Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Mono/Multi Repo, Balancing Feature Branches and Continuous Integration
If you are confused between mono repository or multi-repository or a branch and merge strategy for micro-services - feature branches, trunk based development or release branches, then this post will have something for you. There is no one right way, but as with life, to choose a better way ,you need to be first self aware. Similarly to choose a source control strategy for your project, you need to be aware of the analysis process, development process, balance of parallel feature development with CI and CD,code review and merge process and component ownership patterns in your teams.
Git is by default the version control system used by most modern software projects. I have seen that the perspective is different if you have worked in worse version control systems at first. But for the new generation of programmers Git may be the their first ‘worst’ source control system. And for those many now and many more in the future, maybe it is good to start with a little about Git first.
Most SW developers who has worked for a decade or more would be familiar with one or the other of the centralised version control systems that was prevalent at that time. I started out with building a windows client for CVS as part of industry project. After that, for quite a lot of years was using the monster called ClearCase, and then I moved to a more modern project based on Java and Agile practices and there was introduced to Subversion/SVN and things started looking good. Everything looks good after ClearCase.
SVN looked good, and it seems there was nothing better to wish for. But then came Git and it suddenly felt empowering; that’s something strange to be said about a version control system. Git was built by a developer for the developer. Very few people would write a poem about SVN, ClearCase or the like, but Git is different.
Till then I dreaded to branch fearing the cost,Or more the dread to think of the merge,But then came Git,And lo! I am in branching heaven!`
There was no more need to be heavily depended on the source control operations team. Since it is a distributed version control system, everyone has a copy of the repository in his laptop, that one can work offline with. That is incrementally commit to, branch out etc as with any SCM (source code management). Linus designed and implemented Git as a SCM replacement for Linux as the one they were using Bitkeeper became licensed. The key here is distributed version control system. Linus Torvalds presentation regarding the rationale of why he developed Git , in his inimitable style is a must watch before you do anything with Git.
So what is lost from centralised version control system; nothing much.You can always designate one repository in a server as the central repository- ‘origin’, to which all others raise a ‘merge request’ or ‘push’ their local commits.
Branching and Merging in Git,perfectly implemented:
Git which makes it very easy to branch and merge. All SCM’s support branch and merge; but the implementations were not as good to say the least. In SVN a branch is a copy of the folder in the server and all its contents. In Git a branch is nothing but a pointer to a commit.
This ability to easily branch and merge means that there quite a lot of ways to structure the flow of code from development to release. We will come to this part in a short while. Before that, maybe it is as well to dwell a little on some characteristics of Git that some may not realise at first.
Since Git is a DVCS (distributed version control system), if someone has committed a large file or set of files in a different branch,and pushed to ‘origin’ repo, it will be downloaded to everyone’s machine once they do a ‘pull’ or ‘fetch’ from ‘origin’; that is synced their repository with the designated ‘central’ repository. This is not a typical use case, but sometimes binaries or generated files gets ‘added’ and ‘pushed’ inadvertently. And even if the developer realises and immediately deletes the file, and commits and push again, the Git history has the file in its commit and history is usually kept immutable unless of course you do a ‘hard reset’ and do a forced push. This is not recommended as it may cause inconsistency if somebody already has ‘pulled’ the history with the commit into his or her local repository.
This means that if you are on a slow network,which strangely even now most of the enterprise IT systems are,the clone of big repository take some time to download. You can do some tricks like shallow clone etc, but Git was not meant for huge (>1 GB) repositories. Of course, if you store only source code, you would no have this problem. Note you could use something like Git Large File System (https://www.atlassian.com/git/tutorials/git-lfs) or other in your server to take care of it.
Tip: Want to clean your repo, use https://rtyley.github.io/bfg-repo-cleaner/; https://stackoverflow.com/questions/2100907/how-to-remove-delete-a-large-file-from-commit-history-in-git-repository
The other problem, if you can really call it that, is that it is slightly complex to use; primarily because it is distributed in nature and primarily it was written by a developer (see the video if you have not). But in the years hence many have contributed and now it is as usable as any other tool. It may look and feel similar to SVN, but you will commit mistakes if you do not take a day or two to learn the basics. I am no expert in it, but have used it for some years now, reverted merge commits across parent branches ( bit chilly) and prayed and did hard resets of the history more than once.
Tip :I have survived all this while with a few git commands;
git clone, git checkout (-b for new) <branch-name>, git branch (to see where you are), git fetch, git merge, git pull (does previous two in one go),git stash (sometimes), git reset (and its options- very very carefully), git log, git force push (very few times).. and maybe some more
There are a ton of other commands out there; be wary, understand and use; or better not use if you do not understand the implications fully — example git rebase- https://medium.com/@fredrikmorken/why-you-should-stop-using-git-rebase-5552bee4fed1
Mono Repo or Multi Repo ?
There are two way’s to host a project; as a single repository -mono repository or a set of multiple repositories. Before we go any further, let us ask this question first.
What constitutes a micro-service project?
If we define a project as a set of micro-services that collaborate with each other using some sort of typed interfaces (like protobuffer), then there is a clear advantage in sharing interfaces unambiguously and singularly. For this there should be only one copy of the interfaces and I feel the best way to do is is using a single repository /mono- repository.
Is there a way to do singular versioning of Interfaces using multiple repositories ? Not in an elegant, non manual way.
The very nature of multiple repository means that you need to assign one repository as a truth for interfaces and have some or other non elegant work agreement to copy manually to and fro from this repository to your repository or use sub modules. Both are prone to mistakes. Managing this via reference to an external repository via sub-module, sub-tree seems like a good fit, but it is an abstraction that is quite leaky and need to used very carefully.
The better way to share interfaces is by a shared branch, not by a shared repository.
The caveat here is that if your project is composed of ten’s of thousands components and gigabits of source files, all sharing interfaces, Git won’t be good in handling that; and you need to break this into different repository.
Choose your branching strategy: Feature branch vs Trunk Based development vs Release Branch
With Git the general tendency is to increase the number of branches that is used. When we talk about branches the context here is the ‘public’ branches or the one others collaborate on.There is no problem in having thousand’s of personal branches.
Branches have usually a hidden relation with your SW release methodology, merge quality, merge process and merge frequency. This will be especially evident when you have many SW developers working for a product collaboratively in an enterprise SW product development scenario. A good branching strategy should have clear code review and merge ownership for each branch, should give freedom to work in parallel for multiple features by multiple teams and still be able to release frequently. This is a hard ask than what you may think.
There is not one best solution for all scenarios.
Continuous Delivery is one of the hardest release strategy to achieve. When you are in such a mode, the master branch, or trunk, is pretty stable to incoming merges. That is, the code that passes the merge criteria, be it code review process, or SW developer process or SW developer quality is at a pretty high standard. In this situation the strategy is predominantly trunk based development. That is feature branches are cut from the trunk, they are relatively short lived and is merged back to the trunk.
Who owns the feature branch ? Usually it will be the feature lead who will also be an expert in the domain and in programming. Or it will be collective ownership of all the component leads contributing to the branch.
The same model may not make much sense and may cause problems if every other merge is causing instability in the product created from the trunk. When this happens you have production and development moving further away from the trunk. That is cut a release branch once master is stabilised for a release and then take bug correction merges on the release. Meanwhile the master is mostly red (meaning the CI driven automated test cases is red). Feature branches are cut and most of the time is spend in working on the feature branches without daring to or able to merge to master. Typical opposite of real Continuous Integration.
Between these two strategies, that is trunk based development with short lived feature branches, or release branch based development with long feature branches, there are a gazillion strategies you can choose or build, and whatever you choose, make sure to refine and adapt it over time as your team evolves into you release evolves towards CD.
Here is one such for every need and every hour https://www.atlassian.com/agile/software-development/branching . Or the much more famous one here (Git flow) with a develop branch for CI and a master branch for release — https://nvie.com/posts/a-successful-git-branching-model/
Is there any special branching strategy needed for Micro Services ?
Here is one I used. There is a special branch called ‘interfaces’ cut from master. This is done at the start. For each MS there is a folder created with the MS name, but which contains only the interface/GRPC proto file for the MS in ‘interfaces’ branch.For each MS there is a ‘MS main’ branch that is cut from interfaces, which contains a folder for the MS and implementation. This is merged to master branch periodically. The interfaces branch is merged into MS main frequently. The master is never merged to MS-main but the flow is from MS-main to master. Interfaces will have just interfaces for all MS. Development happens on branches cut from the MS main and merged back. The MS-main is merged to master. Each MS sees only the interfaces of other MS and its own folder/implementation.
A typical feature is implemented across multiple MS in feature branches that are merged into MS main by MS component lead. The advantage of this is that each MS can work on the feature in a isolated way. This reduces merge conflict and ownership ambiguity. The ownership to review and merge to MS main lies with the MS component lead. There is also a Jenkins pipeline configured for CI for each MS. Other than reduction in possible merge conflicts and non-ambiguity of branch ownership, this particular strategy has not much benefits.
We can also have the feature branch concept here. That is latest of each MS will be a folder in master branch, and latest of each released MS will be a folder in release branch. For a feature, a branch is cut from master and all component owners branch off this branch and raise merge request to this branch. There are two activities the feature branch owner (feature owner) has to do. Since there would be parallel development and merges to master, the master has to be merged periodically to the feature branch and merge conflicts if any resolved. Also the feature branch has to be reviewed and merged to master. There are quite a lot of redundancies here.
The same concept can be simplified by cutting feature branch by each MS and then raising merge to master, which the MS component owner will merge. The problem is that the system composed of the builds from latest master will have unfinished features in. Some of these could be DB table updates or GUI changes. It is not a good idea to release half baked features. The problem is that some other smaller feature may be already completed and merged to master, and the bigger unfinished features for the same component that is present in master makes things like feature toggles and related overhead necessary.
Is there a way out between choosing between Continuous Integration and parallel feature development ?
Feature branch and one-way continuous integration
What if instead of merging to master frequently, master is merged to the feature branch frequently. This will mean still that the feature is still not continuously integrated to master till it is fully Done. But since master is merged to feature branches the merge and functionality conflicts in the final merge of the feature branch to the master may be reduced. This may be a better way than feature toggles.
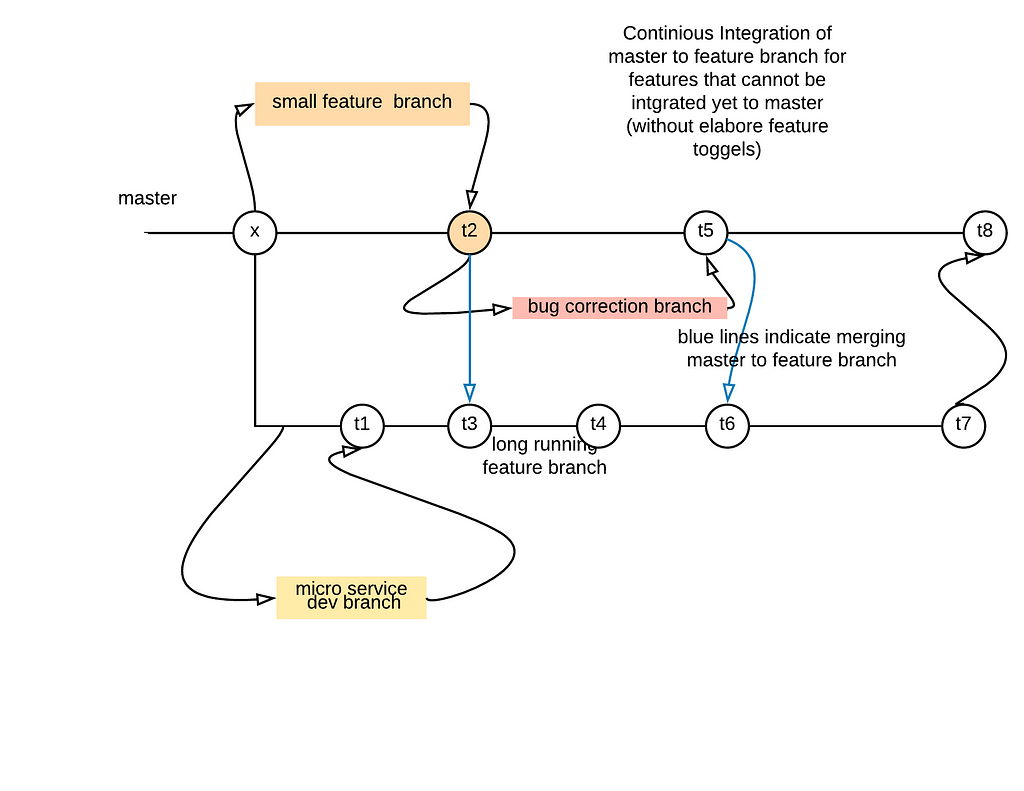
What should be realized is that there are more important things than branching strategy that has to be correct for CI and CD to work. This could start as early as requirement analysis and splitting features to smaller User Stories that can be released independently and integrated more frequently to trunk.
Micro Services & Git was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.