Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

The current development of public blockchains (as private ones) is very similar to what happened to the Internet at its beginning. The Internet was only constituted of intranets, i.e private networks attached to an institution or to a group of people working on the same subject. Yet these intranets were working in isolation without the possibility to communicate with each other and share information.
At the beginning of the 1970s, appeared the TCP/IP protocol which has been created to link these networks and allow inter-network communication (hence “internet”). It is the same now with the networks based on a blockchain. Even public networks, that are open to everyone such as the bitcoin network, operate independently fro m the other public networks without the possibility to communicate directly between them. In the current state of the technology, it is not possible to directly exchange bitcoins for Ether (issued by Ethereum another public blockchain). It is only possible to buy ether with bitcoins on a cryptocurrency exchange which connects buyers and sellers.
Before describing the solutions appearted until now to connect these different blockchain (II), it seems interesting to briefly describe how the Internet, as well as the applications that use it, are organized and shall communicate the information (I). This will also help us to better understand how the decentralized networks use the existing structure of the Internet to develop.
I — CIRCULATION OF THE INFORMATION BETWEEN TWO APPLICATIONS SOVER THE INTERNET
1 — THE GENERIC STACK OF AN APPLICATION BASED ON THE INTERNET:
The Internet as we know it today works through several layers of a same stack that can be resumed as follows:
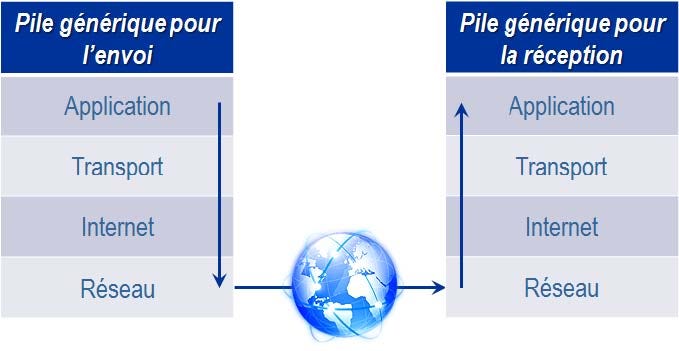
Each of these layers include one or several protocols which gaol is to select and prepare the information before it is sent through the Internet.
You need to follow the arrows to understand the path of the information through these layers from sending to receiption of the information. The information travels from the top of the stack which is where it is sent and goes through the different layers of the stack to reach its recipient.
The first layer is the application that represents the interface with the users. If we take the example of a mail box, an application that we all use. Writing an e-mail and clicking on the button “send” triggers the process of sending data to your recipient. Your e-mail will be sent using a protocol called SMTP (Simple Mail Transfer Protocol). A protocol is a list of rules and steps allowing a good communication between several computers. There are many types of protocols and the choice of protocol depends on the layer and the type of data sent. For clarity reasons, we will focus on the most commons protocols. At application level, the File Transfer Protocol (FTP) will be used if you send files or HyperText Transfer Protocol (HTTP) if you send a query on the web (for example a Google search).
The next layer is the transport layer which objective is to organize the transport of the message without taking into account (at this stage) the type of network to route the message. The most common protocol in the transport layer is “TCP” (for “Transmission Control Protocol”), which objective is to segment the message into multiple packets to be able to send them separately on the internet, check that all messages arrive well in order, send new packets when some are not arrived and verify that the network is not congested.
On the side of the party who receives the message, the role of the TCP protocol is to collect the packets and reassemble them to reconstitute the message.
The goal of the Internet Layer is to send the packets that we have just described through the Internet network. To do this, the Protocol “IP” (for “Internet Protocol”) performs two main actions. First, it identifies the recipient thanks to his address “IP” as well as its location. Then it sends the packets to the server the closest to the final recipient.
Finally, the lowest layer of the stack is the network which objective is to transmit the message physically, using the infrastructure of the Internet network (wifi, telephone cable, optical fiber…).
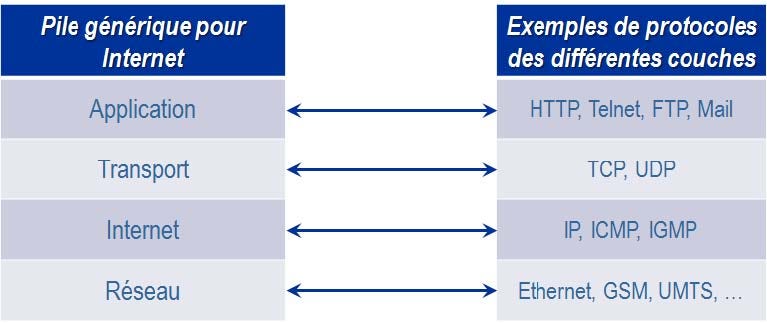
You will find below a short summary of the different protocols used according to the layer of the stack of the Internet network:
2 — The Generic stack of a Traditional Application:
We focus here on the first floor of the generic stack, the “application” layer. The three constitutive elements of an application are the storage, the treatment and the communication of the data.
- The storage of the data.
First it is important to différentiate the “File System” (“files system”) from the “database” (“database”). The first system is a set of programs which allows you to add and to classify folders on the hard drive of a computer while the second is a set of programs that allow you to organize and maintain a database.
A file system is less complex to the extent that it is tailored to store unstructured data, i.e all data are based on different formats. For example, some files will be in Word, others in PDF, but will not share a common structure. The idea is therefore simply to add these data in files and organize those files in order to find the data easily (through an index for example), as you would do with any computer.
It is different with a management system database in that it organizes the data with a similar structure to which we can apply a logic of organization generally in the form of tables. In other words, it is possible to create a program (based on a language like SQL for example), which will manage the automatic storage of data and all other operations necessary for the management of these data. For this reason, this type of system such as MongoDB, MySQL and Cassandra, is more complex to put in place, but very suitable when the amount of data to manage and the number of users who need to access it is important. Create logical management allows to avoid duplicate datas and strongly secures the system.
However, there is still the problem of the access and the update of these data when several applications use the database at the same time. The problem is to organize the use of the database by these different applications to ensure that they use only the last updated version and do not insert their changes in an hold version. Processes better known as “multiversion concurrency control” are essentially intended to allocate the use of a database according to the needs of such or such application and allowing its simultaneous access.
In practice, the applications send transactions to change the database. The “multiversion concurrency control” have a mission to organize these transactions and avoid any conflict. As we will see, the mechanism of consensus of a blockchain can be defined as a distributed « multiversion concurrency control ».
- The treatment of data
The processing of data corresponds to all operations carried out by the computer on the data. This definition covers for instance the transformation of data into information readable by the machine or the movement of data across the processors and memories.
Depending on the applications, this treatment of the data can be performed with or without registration of the state of this information. To simplify any computer is a “state machine”. This means that a computer continuously checks if a request was submitted to him by constantly operating a “state function”. Each time a query is submitted, the computer detects this change of state and action it. For example, when you press an icon to activate an application, your computer will launch the application and once completed, save that the state of the application is now “enabled” until you decide to close the application in which case the computer will record the new state relating to this application.
When a command is only operated, but the new state is not registered, we are talking about a stateless program, of an application or a protocol. The difference between the two lies in the recording or not of the action.
- The communication
As described earlier, the TCP and IP protocols have been imagined to connect different networks by allowing the transfer of data.
However, these protocols transmit the data in the same manner regardless of their values. The Protocol decomposes the information in packets and sends the packets until it has received the confirmation that all packets have been received and reconstituted by the recipient.

3 — The stack of a decentralised application:
The decentralized applications based on a blockchain are not totally different in their structure from traditional applications that we have just described. We have identified the various components of an application to be able to compare them with those of a decentralised application. Note that we will rely on the bitcoin protocol but also and especially on the Ethereum protocol to illustrate the different layers of a decentralised application, since this last platform has been created to develop decentralized applications.
1 — The storage of data
As already mentioned, a blockchain is a database of a new kind since it is at the same time decentralized, transparent and protected by cryptographic processes.

We have just explained what is a « multiversion concurrency control ». The role of a blockchain through the consensus mecanisms is the same, but achieved in a decentralised manner.
The primary role of a consensus mecanism is to organize the addition of the transactions to the blockchain. Networks based on a blockchain are by definition decentralized. This means that the members of the network are in charge of updating the database and not more a trusted third party. The difficulty of consensus mecanisms is to ensure that transactions are added to the blockchain only once and according to an order that is appropriate to all members of the network. It is indeed vital for the life of the network to ensure that a transaction is only added to the blockchain only once in order to avoid the problem of the « double spending ».
Imagine that the bitcoin that you receive has also been received by another person, the transfer of value over the Internet which is the main purpose of the bitcoin network would immediately be questioned.
When all the members of a network are anonymous, which is the case of the bitcoin network, a consensus mechanism is necessary to organize the addition of the transactions to the blockchain, i.e. to determine which members will have the right to add the transaction and get the reward attached to it (12.5 bitcoins at the present time — this number is programd to decrease at regular intervals).
In the databases universe, a transaction is used to change the database. This is true with bitcoin since each transactions added in blocks include a new output. This output will then be added in the input to the next transaction which will also include a new output. Each transaction therefore amends the database by adding a new output. If you want to better understand a bitcoin transaction, you can refer to the article.
This is also true with smart contracts platforms such as Ethereum. Smart contracts are saved directly on the blockchain and actioned by transactions (commands sent by external accounts to the blockchain) or messages (commands sent by other smart contracts). In other words, the state of smart contracts on the database is changed directly by a transaction or a message.
With blockchains, the program in charge of the database management is therefore the protocol which brings together all the operating rules of the network. Its role is to define the rules that will have to be respected for the transactions to be added to the blockchain (size, information required, valid output, private key corresponding to the public key…).
In its initial form (the bitcoin one), the blockchain is the only location where data are stored. The blockchain is downloaded by all complete members of the network, so there are as many databases on the network that there are complete members. Members must therefore constantly update it, to ensure that are always adding blocks to the most updated blockchain.
The technology has evolved a lot since bitcoin appearance in 2009, and today it is possible to store network information in databases that are external to the network and its blockchain. This is the case with IPFS which communicates with the blockchain thanks to smart contracts.
- Data processing
The bitcoin blockchain which corresponds to the most basic form of the blockchain, only proposes the decentralization of data storage, as we have just explained. The other two aspects, the processing and the communication of data, remain specific to each member of the network. In other words, these activities are not divided among the members of the network.
With the creation of Ethereum and its decentralized virtual machine, we saw the first decentralization of data processing. Unlike bitcoin network, the Ethereum protocol proposes to store transactions in each of the blocks of the blockchain, but also and especially, computer programs, the famous smart contracts. The blockchain, therefore, becomes a « smart » database because it has relatively advanced computing capacity. The blockchain became « Turing complete ».
This means that the computer programs stored in the blockchain can be operated by users (by transactions sent from external accounts) or other contracts (by messages sent from internal accounts). However, the commands are actioned by the Ethereum Virtual Machine which is composed of all the computers of the network. When a smart contract is operated, all the computers on the network are running the program simultaneously and update the new state of the Smart contract in the blockchain.
It is important to remember that with Ethereum, we passed to the second stage of decentralization in which it is possible to gather thousands of computers of people who do not know each other in order to execute the programs of a global network. It is also the reason why Ethereum is sometimes called the « first world computer ». To learn more about the operation of Ethereum, you can refer to this article.
- Decentralised communication
At the moment, decentralized applications are still based on the communication stack of the Internet (TCP/IP) to exchange of information, but the technological developments could change this fact in the near future.
The stack of a decentralised application could therefore be simplified this way:
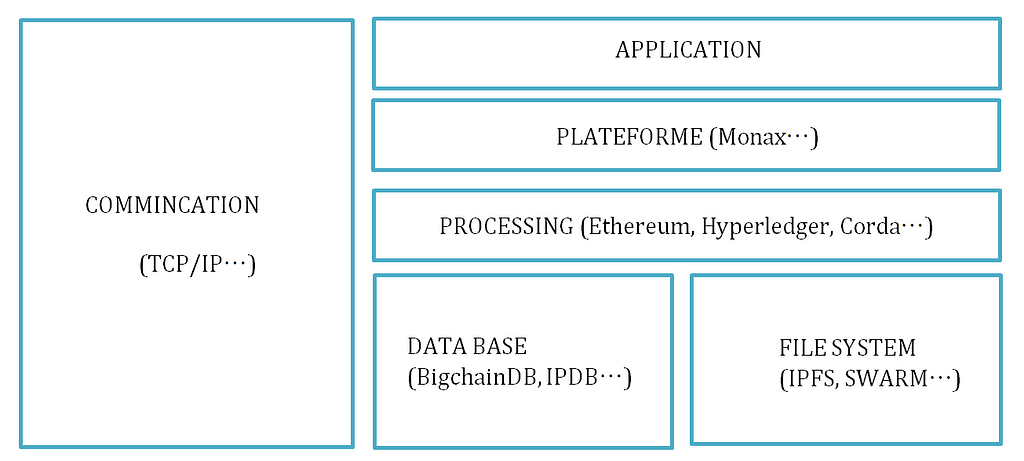
In the second part of the article, we will describe inter-blockchain communication methods.
If you enjoyed this article, please do not hesitate to share it on social media and clap 100 times!!
Decentralized Applications Stack was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.