Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Applying the Lean Startup Method to AI Products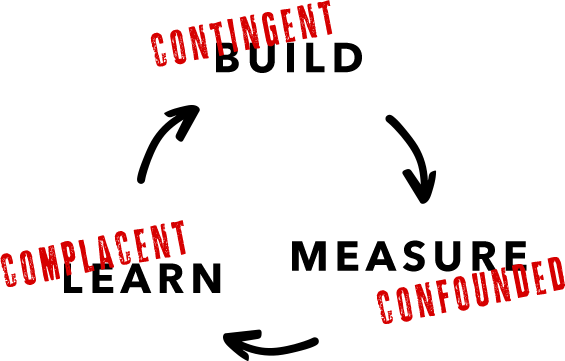
Machine learning and AI are becoming critical components of more and more products. Some applications, like image recognition and natural language understanding, seemed out of reach just a few years ago but are now reaching the mainstream.
But, these powerful tools also create new product development challenges.
Having worked on building machine learning based products at various companies, I started noticing a common theme: data creates a fit challenge.
What is a fit challenge?
Before the maturation of AI, the lean startup method transformed the way people think about developing products. It tackles the fundamental challenge of finding product/market fit: identifying a market need and building a product that satisfies the need.
Why is this so hard? Because the market is a source of uncertainty. You don’t know what the exact market need is and if your product really solves it.
There are other sources of uncertainty about the ability to satisfy a need. Each of them creates a different fit challenge. For example, Uber has encountered a regulatory fit challenge over whether its drivers should be classified as employees or independent contractors.
Product/Data Fit
In a data product — a product that relies on large amounts of data or involve machine learning and AI — you run into the challenge of product/data fit. It arises from the uncertainty about the ability of data to satisfy product needs:
- Machine learning models make predictions that aren’t always correct. You don’t know when they’re right and when they’re wrong.
- You can’t guarantee in advance the level of performance of a model. Let’s say you can afford up to 10% wrong predictions. You may not be able to build a model that’s 90% accurate.
- It’s entirely possible that you don’t have enough data or that there’s not enough signal, but you don’t know that in advance.
- Even if the model performs well on training data, its performance in production may vary significantly.
So when building a data product, you are tackling at least two sources of uncertainty simultaneously: the market and the data. Let’s understand how product/data fit impacts the process of finding product/market fit.
The Lean Startup Framework and Data Products
The Lean Startup methodology addresses fit challenges via validated learning: quick iterations on a series of minimalistic experiments designed to test a hypothesis about the market.
These iterations proceed along the build-measure-learn cycle. You start with the value hypothesis, figure out metrics to measure it, and design an experiment to test the it in the market. Then you build what’s needed to run the experiment, measure the results, and learn by adjusting or refining the value hypothesis.
In data products you also have a product/data fit problem, and that adds challenges and risks to every step in the build-measure-learn cycle:
- The build step is contingent
- The measure step is confounded
- And the biggest risk: the learn step can be complacent
Let’s understand this in more detail.
Contingent Build
As we just saw, data creates a fit problem. This means that you may not be able to build the model that you need (not accurate enough, not enough signal, etc.)
The build step is non-deterministic, or contingent.
This isn’t an issue in traditional software products. Building great software is not easy. It takes hard work. But generally speaking, it’s a deterministic process: engineers know what they can and cannot build.
By contrast, data science is non-deterministic: you have little control over the end result. This is one of the reasons for the distinction between software engineering and data science.
Confounded Measure
This situation leads to confounded measure.
You go and measure the results of the experiment. They are not what you were hoping for. Is it because the models are not accurate enough, something that might improve with more data and better models? Or is it because the value hypothesis actually doesn’t pan out in the market?
The measurement is confounded, and you can’t untangle data uncertainty from market uncertainty.
Can’t you just A/B test that? No. You can A/B test two models against each other, or a model against no model. But you can’t A/B test the model that you have against that model that you want, but don’t have. You can’t measure a hypothetical model.
Complacent Learning
So how do you go from the measure step to the learn step? The biggest risk here is complacent learning: instead of recognizing the confounded measurement, you attribute all the uncertainty to the data. Then, you decide that the value hypothesis holds and that the models will improve as you collect more data.
But in reality, instead of learning from the market, you are hinging your market hopes on data dreams.
Blindly putting your faith the Gods of AI is is one of the biggest risks in data product development.
Example: Stitch Fix
Stitch Fix is a personal styling service that sends subscribers several pieces of clothing monthly. Members pay only only for the items they keep.
In an interview, Stitch Fix founder and CEO Katrina Lake describes how she started the company. She asked friends to fill out personal styling surveys, and then went out and bought clothes for them.
So the MVP was essentially the CEO serving as a personal stylist. This simple build-measure-learn cycle enabled her to validate the market need and delivery model.
Here is what happened a year later as the company was expanding beyond personal connections:
“You might guess that our audience is coastal, Coachella-going, early-tech adopters. But our clients were moms who were like, ‘I need longer hemlines because I volunteer at my son’s preschool, and I want to wear a fun summer dress but it needs to be appropriate.’ And we had a backless Coachella romper for her.”
So what happened here? Stitch Fix had a model that predicted which items members would keep (backless Coachella rompers). At this stage it didn’t involve any fancy machine learning, just guesses about the clientele (“early tech adopters”), but that doesn’t really matter.
This model failed miserably, and the company had to write off a large inventory.
So for the learn step, the company went and talked to its members (“I need longer hemlines”). This process also improved the data it had about members (preschool moms).
Imagine what would have happened if instead Stitch Fix had doubled down on better models. You might think that’s a terrible idea. But how many times have you heard people say in situations like this “we need to use machine learning / deep learning / AI”?
These are all great tools, but only if they are used to leverage product/data fit towards product/market fit. Sometimes the real insight is to avoid complacent learning and listen to the market.
Bottom Line
Data is a source of uncertainty. It creates the product/data fit problem, adding new challenges to each step in the the lean startup cycle: contingent build, confounded measure, and the biggest risk of all, complacent learning. This happens when you double down on fancy machine learning instead of listening to the market.
Machine learning and AI are powerful tools. But to create value, they must drive towards product/market fit and product/data fit. How to do this? I will discuss this question in future posts.

The Challenge of Product/Data Fit was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.