Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Photo by Alexandre ChambonThis is story is brought to you by Hacker Noon’s weekly sponsor, Manifold. Find, manage and share all of your developer services with 1 account on Manifold. Use code HACKERNOON2018 to get $10 off any service.
Photo by Alexandre ChambonThis is story is brought to you by Hacker Noon’s weekly sponsor, Manifold. Find, manage and share all of your developer services with 1 account on Manifold. Use code HACKERNOON2018 to get $10 off any service.
We’ve seen it many times. Yet it sill occurs on a regular basis, as if there’s no permanent cure for this chronic problem.
About 9 years ago, Sidekick, a popular T-Mobile smartphone at the time, lost all of user data in the cloud, leaving 800,000 users without access to their own personal data such as email, notes, contacts, calendars and photos.
Later on, Microsoft decided to discontinue the cloud service and eventually, sales of the device.
As a result, a massive business and its ecosystem ceased to exist. It was the biggest disaster in cloud computing history.
GitLab also suffered from broken recovery procedures when an engineer had accidentally deleted a directory on the wrong server, by running rm -rf /important-data on their primary database.
Side note: Kudos to their transparency! GitLab offered the full picture and anatomy of the elephant in the room, which is hard to come by in the wild or clinical settings. Their postmortem has a tremendous educational value.
Quote from the live notes:
So in other words, out of 5 backup/replication techniques deployed, none are working reliably or set up in the first place.
5 out of 5 layers of redundancy failed? How was that possible for a company that raised $25M+ at the time?
There must be something all of us could learn from. Let’s dig in further.
How did that happen?
3–2–1 Backup is a well-established mantra among sysadmins, which means having at least 3 total copies of your data, 2 of which are local but on different devices, and at least 1 copy offsite.
GitLab followed the principle by having offsite backups on top of local snapshots and hot standbys. Except they thought they did.
- Replication between PostgreSQL hosts was used for failover purposes and not for disaster recovery. (It won’t help when there’s a bug or a human error — it will just replicate the error instantly.)
- Azure disk snapshots were run on the file server, but not on the database. It was too slow to restore anyway, in one such case it took over a week to restore a snapshot.
- LVM snapshots were taken once every 24 hours, but fortunately one was taken manually about 6 hours before the outage, which was eventually chosen to restore from.
- Regular offsite backups using cron and pg_dump had been failing silently, producing files only a few bytes in size. The S3 bucket was empty, and there was no recent backup to be found anywhere.
- Notifications were enabled for any cronjob failures, but SMTP authentication was not active on cronjobs, causing all notification email rejected by recipients. Which means they were never aware of the backups failing, until it was too late.
If you think it’s an edge case of a sample size of 1, read on.
You may be unfamiliar with the empty backup bit, but actually it’s quite common.
Backup tools for both PostgreSQL and MySQL (pg_dump and mysqldump) fail silently when the server is incompatible with the client, generating almost (but not completely) empty dumps.
I even reported the problem and suggested a fix for MySQL myself.
If you just cp / tar / rsync the database files, you are likely to get completely corrupt data unless you shut down the database first. See details here.
Everything works when you first write the cron scripts, but it will stop working months or years later, as you grow your business, scale and upgrade some part of the system.
The worst part? It’s exactly when you need them that you find out that no backups have been taken.
Any sufficiently experienced sysadmins have seen silently failing cronjobs multiple times in their career.
GitLab was able to restore from the LVM snapshot that was taken 6 hours before the outage, but what if it was a physical damage on the storage device? LVM snapshots wouldn’t have helped because snapshots are kept in the same physical disk.
By the way, did you know that attackers can just play ultrasonic sounds to destroy your hard disks?
With no offsite backups, they would have been left with a blank database, losing all customer data since day one.
If you are using DB snapshots on Amazon RDS, or the backup feature of DigitalOcean or Linode, know their limitations and remember that backups are kept on the same physical disk. They aren’t intended for disaster recovery.
By now, you have learned that offsite backup is a must, even in the age of cloud computing. But at the same time, it’s hard to detect when backups are running but just taking empty dumps.
What are the best practices?
Accept that anything can break
If you are a small business that can’t afford to hire a dedicated DevOp and/or DBA to manually test the recovery procedures on a regular basis, is there anything you can do?
There are just too many possible exceptions that you can’t get yourself prepared in advance that would break the cronjob. You can’t know what happens in the future versions of everything, for instance.
System upgrade is one of the most ad-hoc, one-off procedures that can’t be generalized, and it’s hard to set rules of operation for such things.
The last resort seems to be a reliable notification when something goes wrong.
But ”no news is good news” does not apply when even the notification system can break, as demonstrated with the GitLab’s case.
Solution? On top of real-time notification of errors, send backup reports at a sane frequency that does not create “notification blindness,” but makes you notice when you stop receiving them. A weekly or monthly frequency would be sensible. Also make sure to detect an anomaly from a standard deviation in dump file size changes.
Or you can sign up for Dumper, which does just that.
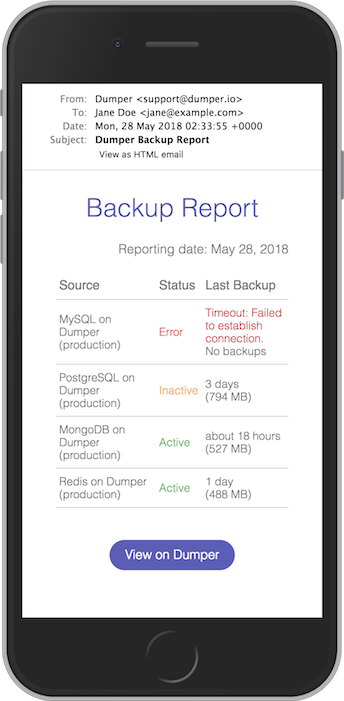
Even if backup seems fine…
Lastly, even if you have a working offsite backup, there are occasions when the dumps could be corrupt, and you won’t be able to notice until you actually restore the database and browse the data.
For instance, mysqldump will take dumps conforming to the client’s character set, and your favorite emojis such as 🍣 and 🍺 in utf8mb4 could be corrupt and replaced by ? in the backup. If you have never checked, do it right now. Just set--default-character-set=binaryoption — you’re welcome.
Or if you missed the --single-transaction option, you are likely to have inconsistent backups (e.g. item changed hands but money didn’t transfer) that are never easy to spot even if you regularly test the recovery procedure manually.
When your dataset grows to the point where full logical dumps are too slow to perform daily, you need to consider archiving WAL/binlog to enable incremental backup and point-in-time recovery. (More on that later — sign up to our mailing list!)
Yeah, I know it sounds insane. And that’s why I built Dumper — backup shouldn’t be this hard.
If you want to read more like this, visit Dumper Blog and subscribe to the mailing list. You can also follow me on Twitter. Unless you are 100% sure that your backup scripts are working, check out Dumper, offsite backup as a service.
This is story is brought to you by Hacker Noon’s weekly sponsor, Manifold. Find, manage and share all of your developer services with 1 account on Manifold. Use code HACKERNOON2018 to get $10 off any service.
Elephant in the Room: Database Backup was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.