Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Best practice from the Alibaba Tech Team in program testing

Test environments are an important aspect of any software R&D process and provide a system for effectively testing new features before release. The stability of such systems is one of the biggest factors impacting R&D efficiency.
This article outlines the main pain points and constraints of test environments and introduces improvement methods that can effectively improve the stability of such systems. The main goal for improvements on test environment stability for the Alibaba tech team is to optimize the container application success rate and improve the stability of test environments. This article shows that by solving problems with applied resource availability and new resource applications, Alibaba has created a smoother software R&D process and, by extension, better final products.
Pain Points
Container applications consist of entire runtime environments and are an effective solution to hiding differences in hardware infrastructure that may be used for test environments. Failures in these container applications commonly suspend R&D progress while tests are run to find out where and how issues occurred. These tests can involve all systems across the test environment.
Issues with Alibaba’s test environment containers have occurred up to 10 times within half a year, resulting in hundreds of hours of wasted R&D time. Therefore, there is an urgent demand for significantly improving the stability of the test environment.
After a thorough analysis of all issues encountered, Alibaba has identified two main challenges facing test environments:
· Already-applied resources becoming unavailable
Poor performance and a high virtual-ratio of hosts (which are out of warranty) of the test environment are fault-prone. Containers of a faulty host are not automatically migrated, which is very likely to result in the failure of their redeployment and restart.
The patrol of the scheduling system renders faulty hosts non-schedulable. As these hosts still have containers that cannot be taken offline, repaired, and reused, the host resources are increasingly limited.
· Low success rate of applications for new resources
Test environment hosts are grouped into resource pools of different priorities that do not share resources. Non-transparency of the total/available capacity of test environment hosts, combined with a lack of warnings, results in a failed scheduling due to insufficient resources.
The resource scheduling system is not optimized to suit test environments which are strikingly different from the online environment, resulting in a low success rate.
Performance Insights: It’s all about the data
In order to optimize test environments, data collection was key to understanding the main stability issues. Alibaba’s approach to understanding test environment stability is outlined below:
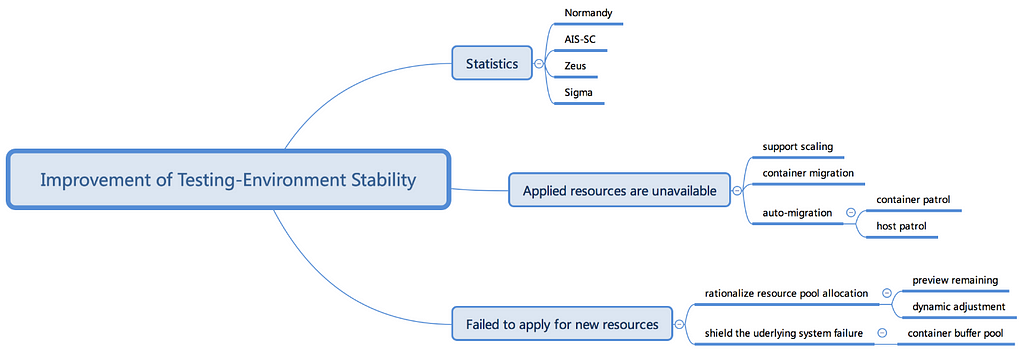 Test environment stability factors and platforms
Test environment stability factors and platforms
The top-down process to get to the bottom of test environment stability issues included looking at the following platforms:
· Normandy: a platform for operating basic applications
· Hornet: a resources application platform
· Zeus: two-layer scheduling system
· Sigma: group resources scheduling system
· Atom: faulty host replacement system
All upstream and downstream systems have their own separate data. A major constraint of this is that this data is not integrated and compatible across platforms. Even though error analysis is undertaken on daily, weekly, and monthly timeframes, it is still fragmented across platforms which makes comprehensive data analysis even more challenging.
Nevertheless, the data gathered helped the team identify specific issues with container availability and underlying system shielding and develop solutions according. These solutions included automatic container replacement and shielding against underlying system failures. After implementation, the stability of the test environments was monitored to determine whether the solutions were effective.
Rationalizing Resource Pool Allocation
Resource pool allocation is generally rationalized based on the following factors:
· Logical resource pools
Host tags are used to indicate different resources and priorities for each resource pool. The higher the priority, the better the host.
· Container specification estimation
Test environments have relatively few container specifications, the most general of which is the conversion to 2 core 4G. Other estimations include:
- The average daily container increment for each resource pool. Namely, the increment that day: P0, the increment m days ago: Pm, and the daily average increase: (P0 — Pm)/m.- The computing resources and daily incremental share of each resource pool within the group:- The predicted margin value for each resource pool: Ti = Ri * T, where T is the total margin.
· Host rating
The host device can be adjusted based on the rating of its room, number of historical failures, hardware configuration, and date of issuance.
· Container distribution rules
Host tags corresponding to the resource pool are distributed based on the host rating and resource pool priority.
An outline of this dynamic allocation of resource pools is shown below.
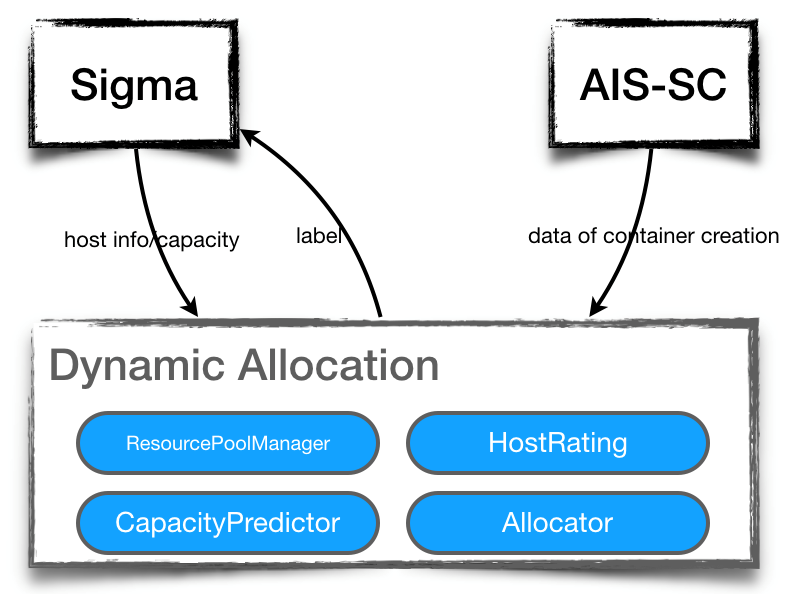 Rationalization of the dynamic allocation of resource pools
Rationalization of the dynamic allocation of resource pools
Automatic Container Replacement
In cases where containers in use become unavailable, automatic container replacement will take place. Essentially, this function creates a new container on a stable host and takes the original container offline from the faulty host.
The process starts with the Sigma system identifying a faulty host, such as one with a full disk or faulty hardware. Sigma then notifies the Atom system, which then replaces containers on the faulty host. Then, the Atom system initializes a host replacement to the Normandy system. Finally, the faulty host is emptied by an automatic replacement and is followed by an offline repair.
Shielding against Underlying System Failures
Embedded buffer pools
Due to the differences between test and online environments — and to save costs –test environments with a high ratio of virtual hosts are primarily used. This causes problems creating and using containers, so container buffer pools are applied to prevent underlying failures from affecting users.
Buffer pools are embedded into the end of the production link of test environment containers to pre-produce a batch of containers that are allocated to the user when necessary. Even if the application for the buffer containers fails, the original production link can continue to produce containers. Whenever the user gets a container from the buffer pool, another container of the same specs is added into the pool asynchronously to maintain its capacity or number of containers.
Buffer-pool capacity
Another key point is working out the buffered container specifications and buffer pool capacity, which required counting the number of past applications for each spec-image-resource pool and deciding the capacity of each buffer on a proportional basis. To ensure that the entire system is still available when the bottom layer system stops service, the number of peak hour container applications, the allowed duration of service interruption, and the host resources of the test environment must be confirmed.
Furthermore, another point that should be considered is that users include common users (R&D and test staff) and system users (such as automatic testing systems) that each have varying priorities. Common users generally have higher priority than system users in terms of the availability of the test environment.
Shielding functions
To minimize the possible influence of buffer pools on users, a number of dynamic switches are added to the buffer pool to shield some of its functions. For example, whether the host name of the container must be changed or not can be set for specific applications. If the host name is not changed, a successful application takes less than 1s on average. In this case, the buffer function can be immediately shielded if an application does not use it. If the buffer pool itself develops faults, a quick degradation can remove the buffer function from the entire link.
Before delivering buffer containers, the buffer pool makes an additional inspection on whether the containers are usable or not to avoid failed service deployment. The buffer pool regularly removes containers that are unusable and adds new buffer containers.
Resulting Trends
Success rate analysis is key to fully understanding the effectiveness of optimizations. As shown below, utilizing the full capacity of the buffer pool from December 21st lead to a vast improvement in success rate and its stability. Drops in success rates, such as that on December 1st, were caused by failed scheduling.
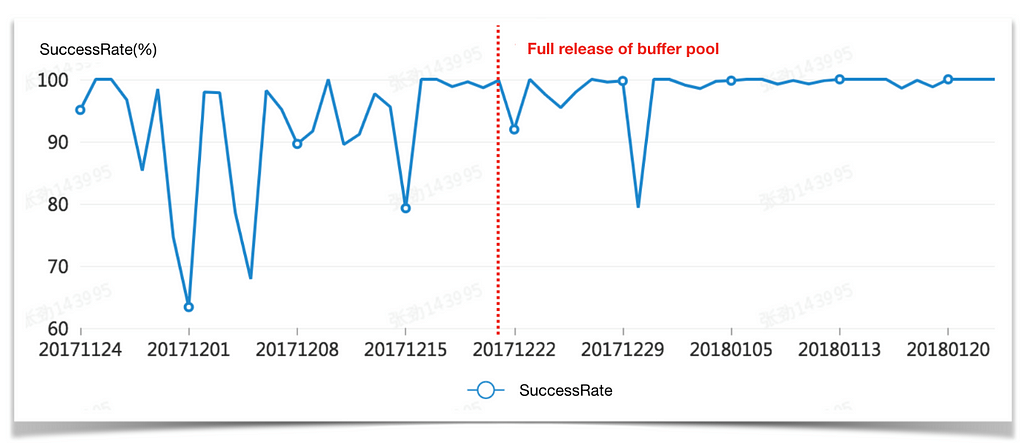 Success rate trend of container applications over a two-month period
Success rate trend of container applications over a two-month period
Adjustments in the capacity of each resource pool according to the projected balance of resource pools and warnings ruled out the probability of failed scheduling and significantly reduced the volatility of the success rate.
Within one week of the buffer pool being brought to full capacity, an internal bug and low hit rate of the buffer pool resulted in a volatile success rate, which was stabilized after the bug was fixed and the hit rate of the buffer pool was increased.
The daily success rate was also analyzed by performing a longitudinal comparison of the user perspective (with buffer) and the bottom layer system perspective (without buffer). As shown below, the buffer pool shielded most bottom layer system failures, and resulted in only one day of poorer performance when the buffer pool was exhausted.
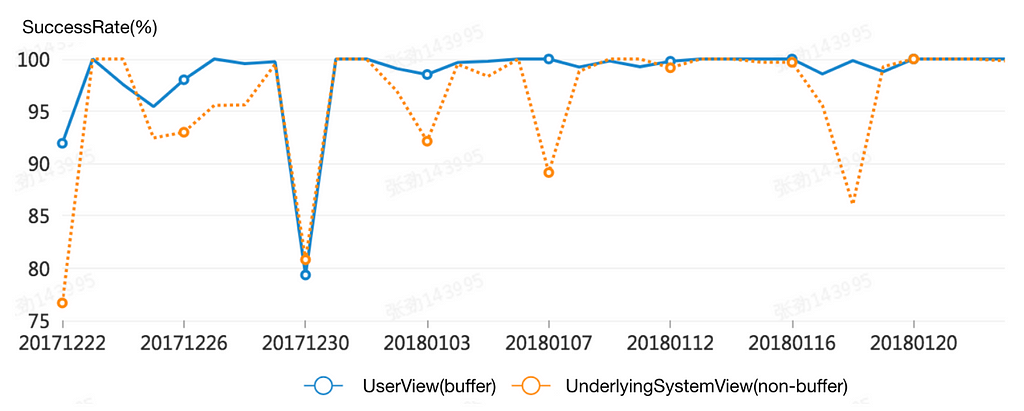 Daily success rate comparison of user perspective and bottom layer system perspective
Daily success rate comparison of user perspective and bottom layer system perspective
LOOKING AHEAD
Despite improvements in success rates following optimizations, there are three key aspects that still need further attention:
· Automatic scheduling of resource pool capacities
Current algorithms are not complex enough to handle certain scenarios, such as adding or deleting too many containers causing incorrect balance trend analysis. Another issue is the increased possibility of chaotic host tags caused by automatic scheduling.
· Dynamic adjustment of buffer template types and the quantity of each type of template
The types of buffer template and the quantity of each type of template should be predicted and adjusted dynamically, according to historical application data or real-time data.
· Expanding the capacity of the buffer pool
This requires enough host resources to be available.
In addition, there are the following more general issues with test environments, developing solutions to which will require a more varied approach:
· How can the utilization rate of resources be increased for the entire test environment?
· How can the time for container delivery be shortened (from user application to when the container is delivered)?
· How can applications be made more schedulable?
Moving forward, these are the questions and issues that the Alibaba tech team will be focusing on.
(Original article by Zhang Jing张劲)
Alibaba Tech
First hand and in-depth information about Alibaba’s latest technology → Search “Alibaba Tech” on Facebook
Optimizing Test Environments by Containing Stability was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.