Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
This week, I thought about my exit strategy, was pessimistic about storage coins, and optimistic about IPFS. In previous weeks, I did this.
The profit check-in

I’ve actually surprised myself that I haven’t been checking the prices obsessively, and rarely even think about it. I opened this table once during the week, saw that it was two-point-something percent profit and shrugged an uninterested shrug.
What I have been thinking about, is …
Exit, stage left
I have decided that no matter what, I will carry on with this $500-a-week investment cadence for one year. And no matter how many times I’m told to stop writing about it because it’s boring, I will keep writing about it.
At the end of one year, if the overall value is down, I’ll stop putting money in and leave everything where it is.
Remember 2014–2017?
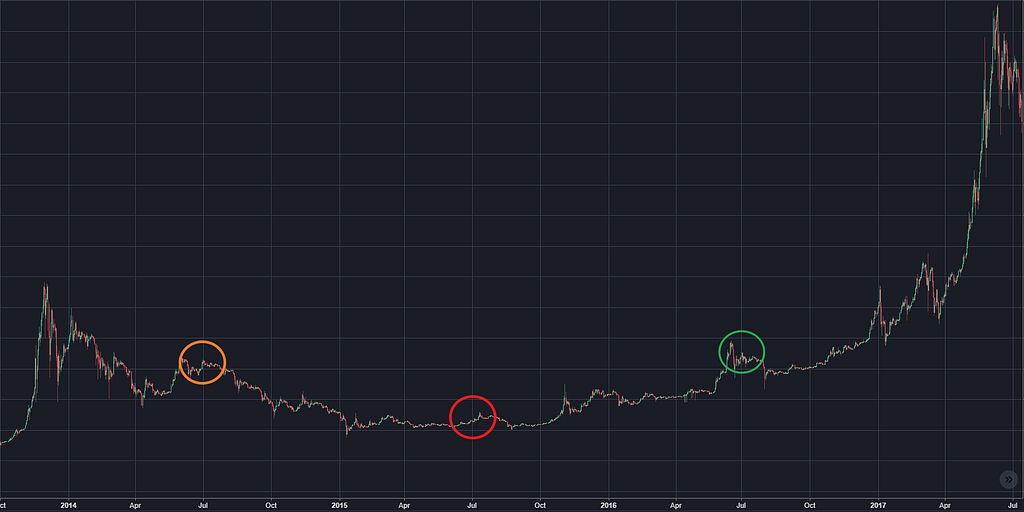 Why are they circles? Nobody knows.
Why are they circles? Nobody knows.
Maybe we’re at the orange circle now, in a year we’ll be at the red circle, and in two years we’ll be at the green circle, breaking even.
People might list the reasons that bitcoin won’t go through another dry spell like this; argue that it’s all wet from now on, but they’d be guessing.
On the other hand, do you remember 2013?
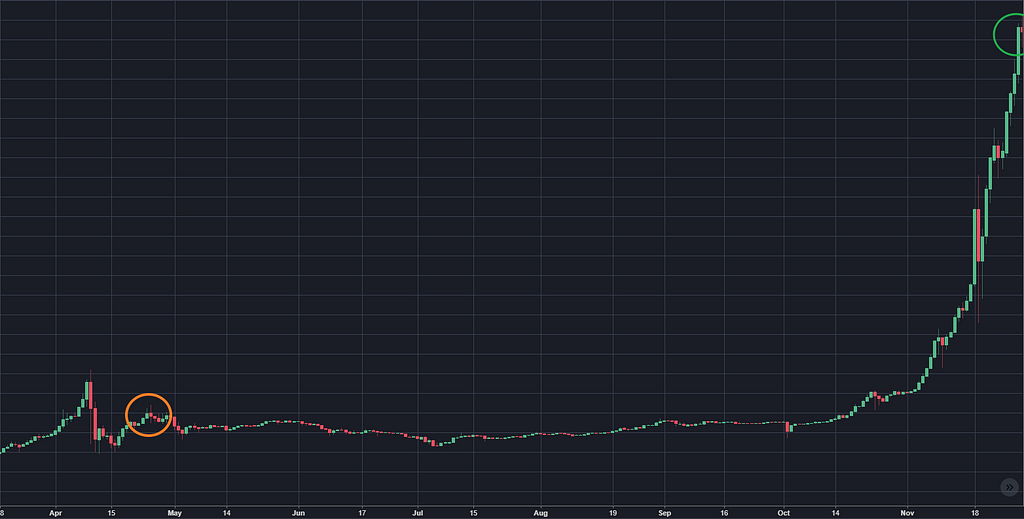
Maybe we’re at the orange circle now and in six months we’ll be at the green.
So what’s my plan if things go really well?
If, years from now, my portfolio gets to $200,000 then there’s little point in me throwing $500 cups of water into the ocean. What I’d love to do is start taking back the money I’ve put in. That way, if it all goes to shit, I’ll be able to say I never lost a cent.
If the value goes even higher, at some point I’ll want to take out some cash and do grown-up things like pay off my home loan and buy a lemur.
Throughout all of this, if you ever see me use the letters ‘HODL’ unironically, I give you permission to come to my house and punch me in the face.
(And no, I don’t fully understand the meaning of the word ironic. Isn’t that ironic?)
Now, on to the many-faceted world of ‘storage coins’. There’s not really a clean way to compare Sia, Storj, Filecoin, MaidSafe, and Shift, but my favourite type of internet comment is “you oversimplified these things when making a comparison between them!!!”.
So I’m going to do exactly that.
Storage coins
I think a lot about wasted resources. Idle CPUs, empty hard drives, my two seater lounge.
I work in an office surrounded by 101 people poking away at MacBook pros — I’m basically sitting in a supercomputer that lies unused for 16 hours a day. It seems like being able to harness this power to train our ML models would be a really neat use of technology.
So when I hear about plans to harness the world’s unused disk space, making money for the owners and providing cheap storage for the users, I get more than a little excited.
I get a lot excited.
I’ve got the hots for the theory, let’s look at the reality…
Existence
Sia exists. Good for Sia.
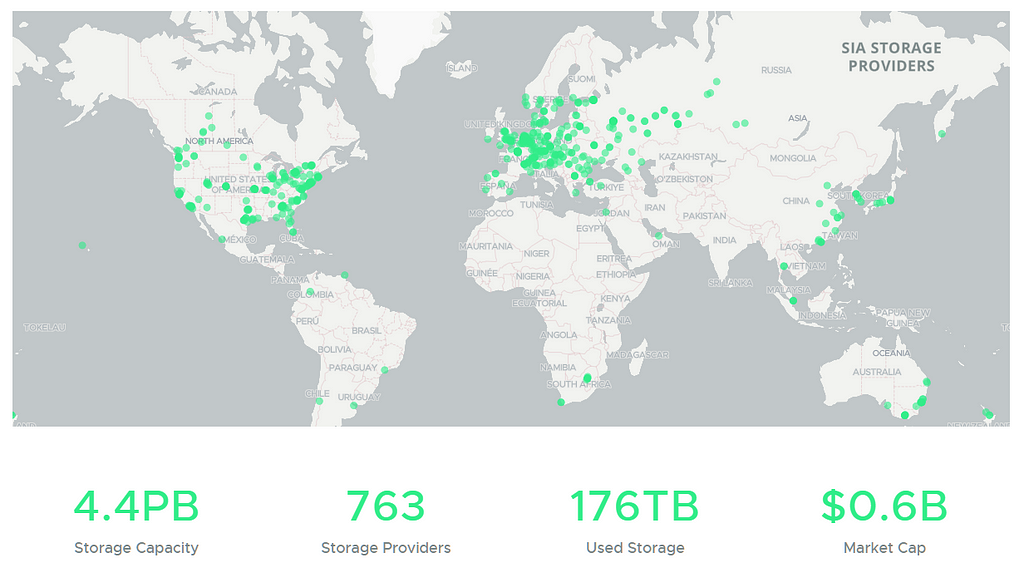
In one way this map is impressive, in another way it makes me want to wear a gas mask and stock up on supplies, and in a third way it’s surprising that there’s only 176 TB being stored.
I don’t want to demean any efforts, but 176 strikes me as shockingly low for something three years old. One guy alone — who I will forget to mention later — uploaded at least 5 of those 176.
Regardless, Sia is out in the wild, spreading around the world like an international travelling butter knife salesman.
Storj (who accidentally spelled storage wrong but have doubled down on that mistake) appeared to exist at some point in 2016 and 2017, but now seem to not exist in the traditional sense. I can “request early access” and they “expect to release the new version by the end of 2018”.
MaidSafe was thought about in 2002, work began in 2006, and an alpha released in 2016. Now, in 2018, they’re up to Alpha 2. That’s, um, a long time.
Shift exists too. Perhaps starting with ‘s’ is the key here. Shift is a little bit different, they’re a layer on top of IPFS. I only discovered them today so I don’t have anything more to say about that. Sorry Shift.
Filecoin is a work in progress (and spoiler alert, pretty exciting). The people that will eventually get around to bringing us Filecoin (Protocol Labs) will also bring us IPFS — the InterPlanetary File System.
I originally wrote a really long summary of my investigation into the coins that exist. But in the end, I was so disillusioned by the available opportunities that I’ve dropped all that.
Instead, here’s a summary of my disillusionment:
I’m not quite sure that the incentives make sense. Say you want to advertise that you can supply storage for $2 per terabyte per month, like Sia does. You’ll want to store that terabyte in at least three places so it’s available even if some people are offline. Which means you can pay each of those people 66c per terabyte per month.
Maybe I like the idea of earning cash-for-capacity, so I buy at 1 TB drive for $80. If I’m lucky enough to have the whole drive filled all of the time, then at 66c a month I’ll have paid it off in a mere … 10 years.
Let’s say I don’t actually buy a drive, but I have 500GB spare. Could I be bothered doing a whole lot of setup, running software, and leaving my computer on 24/7 to earn a maximum of 33 cents a month? That’s exactly zero dollars when rounded to the nearest dollar.
So it will only be with economies of scale that this system makes sense. At which point your data is going to be in large data centres. Owned by organisations. And possibly all three copies will be with the same organisation. And when it no longer makes sense for them to be in business, they’ll close their doors.
So, just like it is now, but with no SLAs.
The verdict
I heard a guy on a podcast this week being quite disparaging about ‘storage coins’, saying something like “a lot of these kids are quite young, and I don’t think they fully understand how hard what they’re trying to do is”.
I don’t share that sentiment, but as I’ve looked at these long timelines and seemingly slow progress, I wonder if, from an investment perspective, it’s a bit too soon to be putting money behind any one player.
What if the one I pick hits a two-year snag and in the meantime someone else comes out of the woodwork with guns blazing.
(That someone else will be Filecoin.)
Maybe that’s why the performance of these coins over the past year has been less than Stellar.
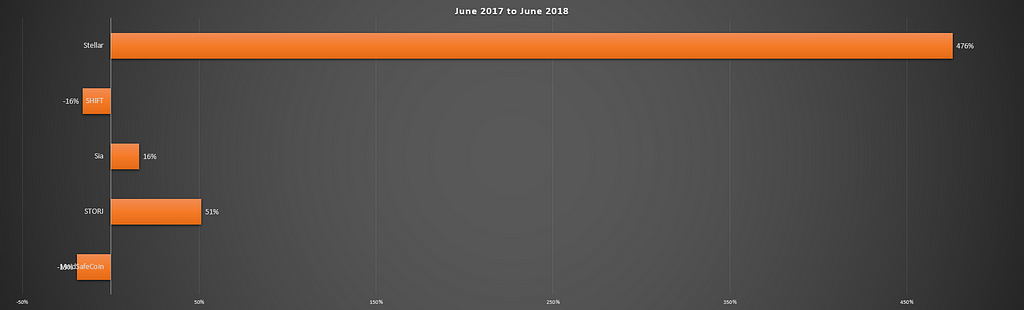
The overall rankings, by market cap, have dropped pretty drastically over the last year, too:
- Sia was 16th 📉 now 32nd
- MainSafeCoin was 25th 📉 now 69th
- Storj was 48th 📉 now 123rd
- Shift was 95th 📉 now 341st
It seems that in the greater cryptocurrency space, people are losing interest in storage coins.
I don’t think this is so surprising. Filecoin have IPFS and a good team and $250m in funding ready to spend on even more good team (including me?). I wouldn’t want them to be my competition.
So, what to do.
What. To. Do.
I think for this week, I’ll buy more Bitcoin.
You’re not even halfway through.
While I was looking into storage coins, and getting a bit depressed, I came across IPFS, by way of Filecoin. And it stirred in me a great many thoughts.
Those thoughts on IPFS I mentioned in the previous paragraph
Over the past few months, I’ve been spending so much time reading about crypto-everything that I’ve come down with a bad case of BCF (Bold Claim Fatigue).
So when I read that the IPFS people want to “replace HTTP” because the “internet is broken” I just rolled my eyes and thought of course they do and of course it is.
But a few hours later I was shaking the pom poms for team IPFS, and I’d like to share my excitement with you.
I must warn you of two things: the following section contains some anti-excitement, and talks about networking for probably longer than you want to read about it.
(Unrelated product idea: an ant poison called anti-anty.)
What does IPFS stand for?
IPFS stands for the InterPlanetary File System.
Tell me more
Something you need to know first: when you open a website, every little file that is loaded to display the page has a unique address that points to a particular server. As you’re probably seen, that file is referenced by a bunch of text starting with ‘http’. The browser requests the file at that HTTP ‘address’ and the server at that address responds with the file.
Boom, it’s all quite simple.
IPFS is fundamentally different. You don’t refer to a file by its location, because a file no longer has a location. Instead, you refer to a file by a unique ID that is generated based on the contents of the file (called a hash). Two identical files will have the same ID (the same hash).
So with IPFS, you request a file from the IPFS network (which is distributed around the world) by this unique ID. The network then says “hey, I found the file with that unique ID, here it is”.
You no longer care ‘where’ the file is. In fact, the concept of ‘where’ ceases to have meaning, much like it makes no sense to speak of ‘where’ your bitcoins are.
This is genius, and to me, seems like a move in the right direction.
At the moment, we have a very, very wasteful internet. Case in point: medium.com serves 120 KB of fonts to render this page in a web browser. Not so bad, I suppose, but they then ensure that the fonts are destroyed from your cache every four hours so that you must download them again and again and again, even though the contents of the file never change.
Bonkers.
And it’s not just you downloading the same files again and again. It’s your ISP downloading the same files again and again and again for all of it’s users, when you all just want the same file.
There are millions of examples like this all over the internet, a relentless stream of downloads of things that have been downloaded before.
It’s digital waste on a scale dwarfed only by Bitcoin proof of work.
Here’s a brick wall.

I found it on Unsplash, (a dude called Jakob Braun took it while waiting for a bus probably).
I downloaded it and dragged it into Medium. Medium uploaded it to their servers. Now every person that reads this article will download it. And thousands of other people have, for some reason, also downloaded this photo of a brick wall from Unsplash and it has probably been re-uploaded to all sorts of other sites, each of which probably compressed it by half a percent and stored a copy on their own servers.
This is the story of a brick wall. But it’s the same for font files. For j-query-1.9.1.js, for the Twitter bird logo.
With IPFS, each asset will exist at one ‘address’ (based on a hash of its content), and exist forever at that address. If you’re running an IPFS node, then the assets will replicate to your node and any content you’ve fetched before from a remote IPFS node, you can fetch again from your local IPFS node, even if offline.
One of the most promising aspects IPFS is that it’s adoption is not at all far fetched.
How I think this will go down
As previously established, I’m quite short sighted. So the following is completely without value. But anyway, I think IPFS will take off along a few fronts:
- Universities will experiment by putting their own sites (student directory, maps, etc) on their own IPFS nodes using an HTTP-to-IPFS gateway, or the IPFS browser extension.
- Udacity will put its course content on IPFS, making those learning materials more accessible to kids in underdeveloped countries. They will start a charity so you can sponsor sending a NAS pre-loaded with an IPFS node holding their courses to a remote school.
- Google will put the millions of books from the Google Books project on IPFS (and promptly get sued).
- The more intrepid governments and corporations will make their content available on IPFS.
- Someone from the IPFS team will do a pull request to the Chromium project adding native support for the protocol in Chrome. The Chromium folk will say LGTM and hit merge.
- Google will look at getting the AMP project to work with IPFS.
- Big commercial websites will experiment with IPFS as a CDN alternative. Perhaps Amazon will push all of their product images to the IPFS network.
- WordPress and Squarespace will release IPFS versions of their site design tools, the output of which will be stored entirely on the IPFS network.
- ISPs will realise: hey, we can just run IPFS nodes in our exchanges and only ever fetch an asset once. No more fetching that little Facebook thumb icon 20,000 times a day.
That’s my thoughts on how the IPFS protocol will come to the existing web.
But there’s more …
The next web will come to IPFS: there will be not just static content but full-blown apps and social networks that tie together IPFS, distributed computation, distributed identities and maybe some other distributed things to form entire interactive experiences with no fixed address.
And it’s all going to need distributed advertising to keep it all free (unless you’re of the mind that content creators should not be paid to do what they do).
Now, even though I’m fully on board the IPFS train (and am sitting right up the front with my little train driver hat on) I think some of the arguments in its favour are a bit questionable.
From what I can see, I don’t disagree with anything the IPFS people say, it’s the enthusiasts getting a bit carried away who are writing cheques that IPFS can’t cash.
I wouldn’t bother arguing with these things, except that I think saying IPFS will do something that it won’t do is only setting it up for (perceived) failure.
So here’s a few things I think are being oversold.
The whole Egypt/Libya/Turkey thing
In a few places, IPFS advocates talk about the internet being switched off in Turkey, Egypt and/or Libya, and how IPFS could have made a difference in those instances.
This is one third true.
About a year ago, Wikipedia was blocked in Turkey (and still is) by some mean idiots.
A project like IPFS could (and does) make this static content available if users can connect to a server hosting the IPFS node containing Turkish Wikipedia (for the record, if I was the Turkish government I’d also block any IPFS traffic).
As a Turkish citizen, it’s probably not easy to get to Wikipedia, but you would still be able to.
This is a valid use case and good stuff.
Some IPFS advocates have extended this to the situation where the internet was shut down in times of turmoil, often referencing Egypt or Libya, and sometimes making the case for countries hammered by mother nature.
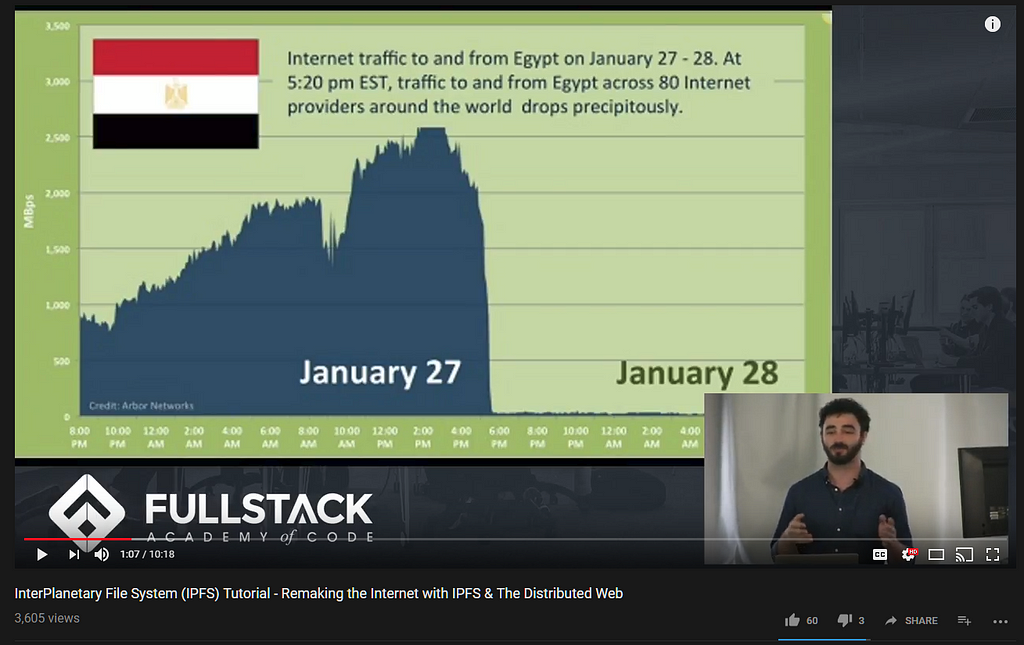
But when there’s mass turmoil in your country and the government tries to sensor the internet, Wikipedia won’t help you get the latest news, or get in touch with loved ones, or let the global press know of the atrocities being committed (so that they can care for 6 hours).
In these times you want news sites, Twitter, and Facebook (who will then serve you ads for molotov cocktails and first aid kits for months).
It’s not the content that matters, it’s the communication.
And it doesn’t matter how ‘offline first’ the network is, you can’t be connected to the rest of the world if you’re not connected to the rest of the world.
IPFS won’t make the web faster
Much.
I remember the first time I used Microsoft Excel. Back then — if I recall correctly — I had long hair and an Intel 486, a 5,400 RPM HDD, and it took about 8 seconds to open Excel. Fast forward 20 years and I have a quad-core i7 with a crazy-fast SSD and Excel takes about … 8 seconds to open.
The sad truth is, even though IPFS will make networks more efficient, web developers will just add more junk to their sites.
It’s like Parkinson’s Law for web performance: the amount of crap in a website will expand to fill the acceptable load time. (Full-screen video background anyone?).
So, if you’re expecting a step change in the overall performance of the web once IPFS becomes common, I predict that you will be disappointed.
(This isn’t a mark against IPFS any more than Excel taking a perpetual 8 seconds to open is a mark against Intel.)
In addition to web developers being the sloppy gate-keepers of internet performance, there’s also the fact that there’s not a lot of improvement to be had.
To back up this probably-wrong claim, we will need …
Lots of words about networking
For the majority of sites, for the majority of users, the thing that makes the difference between fast and slow is latency (the time it takes a request to get from you to the place that has the file).
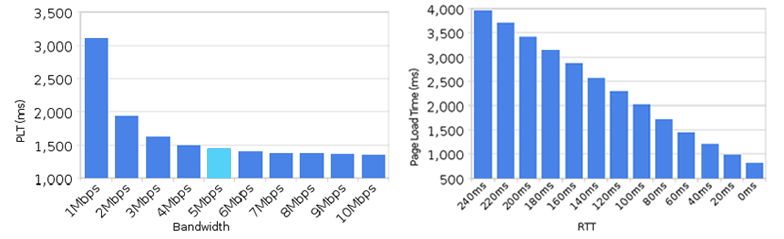 The effect of better bandwidth (left) and better latency (right) on load times
The effect of better bandwidth (left) and better latency (right) on load times
Bandwidth has surprisingly little effect, which is good, because latency is where IPFS is likely to have the most impact, specifically in places with poor access to large internet pipes.
Here’s a map of underwater internet connectivity.
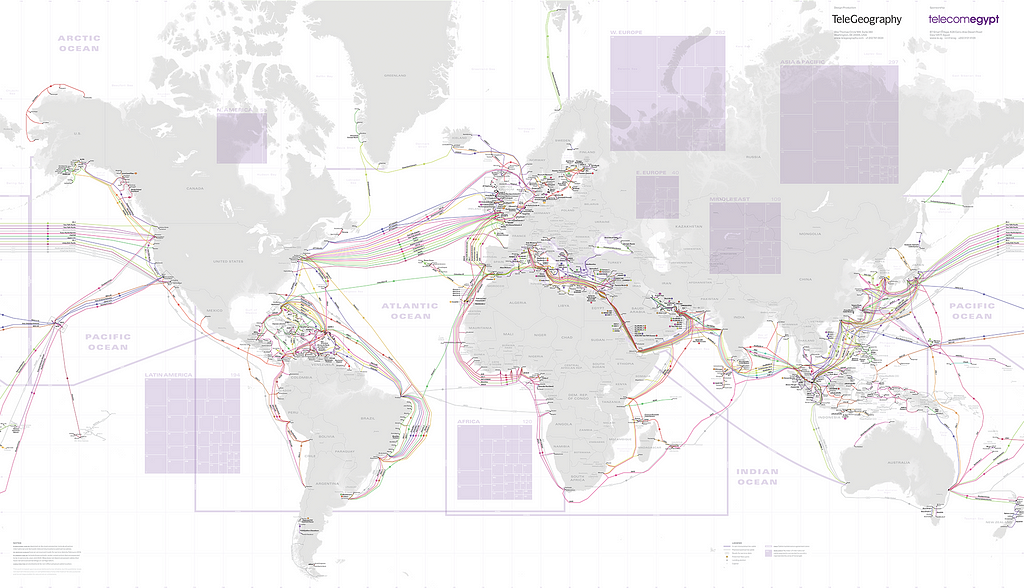 It’s interactive, if you go here
It’s interactive, if you go here
(Side note: I found this map in a Guardian article. The article linked to the source on telegeography.com. But that link is now a 404 page. That’s frustrating, and that’s what IPFS will fix.)
Based on that map, I’ve picked some places that probably have some pretty bad connection times.
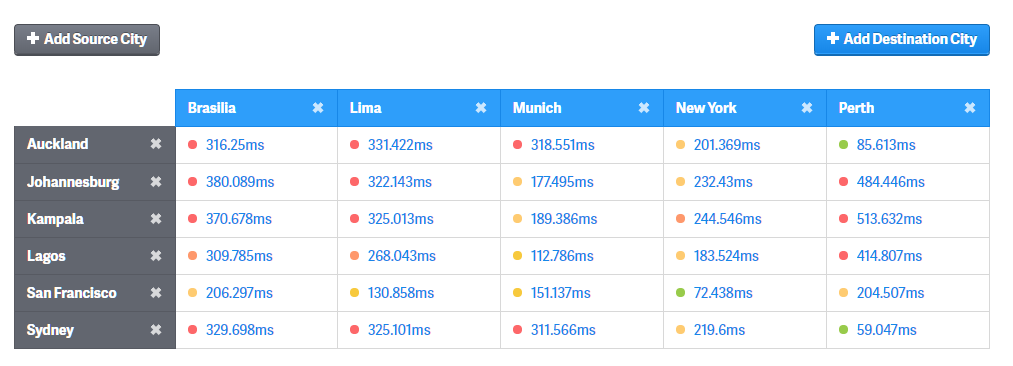 Thanks, https://wondernetwork.com/pings
Thanks, https://wondernetwork.com/pings
You can see that a trip between third-world cities like Kampala and Perth takes 500ms, whereas NY to San Francisco takes a cool 72ms.
One order of magnitude — not great but not super-terrible.
But this doesn’t actually tell the whole story. The sort of site that will switch to IPFS for performance is the sort of site that is already using a CDN [dubious]. Which means a user in Uganda isn’t likely to connect to a server in Perth. They’ll be connecting to a cache layer from Amazon or Akamai or Google, etc.
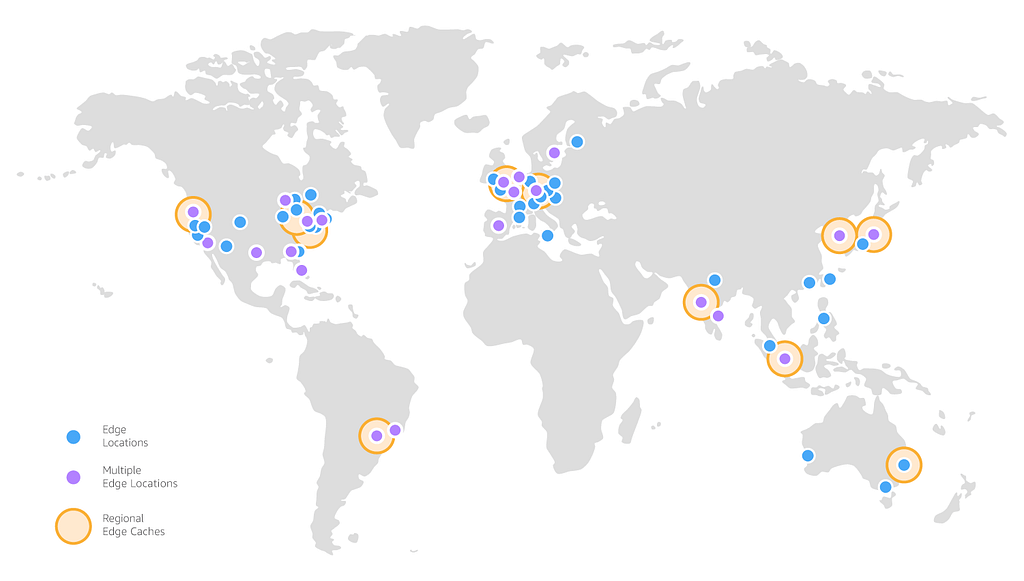 Amazon’s edge nodes
Amazon’s edge nodes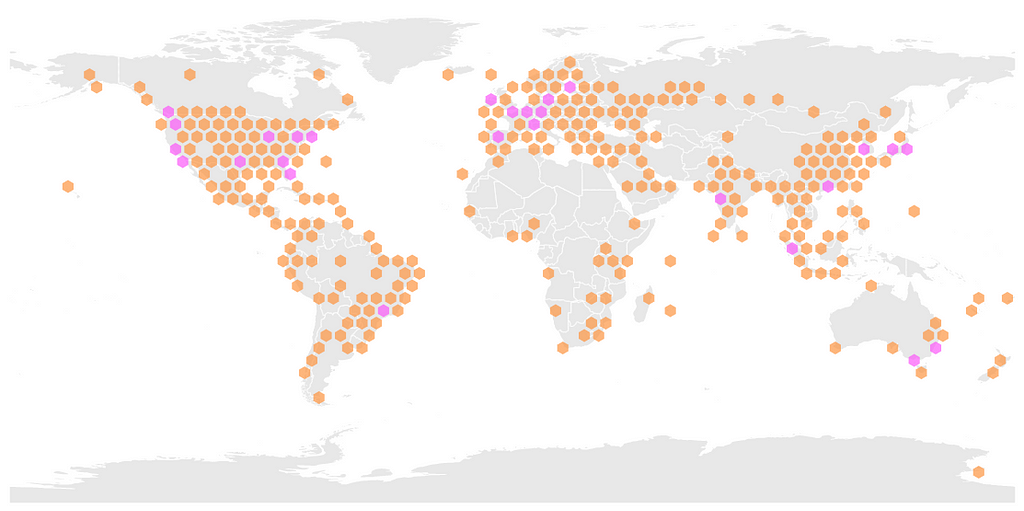 Akamai’s edge nodes. Hexagons are faster.
Akamai’s edge nodes. Hexagons are faster.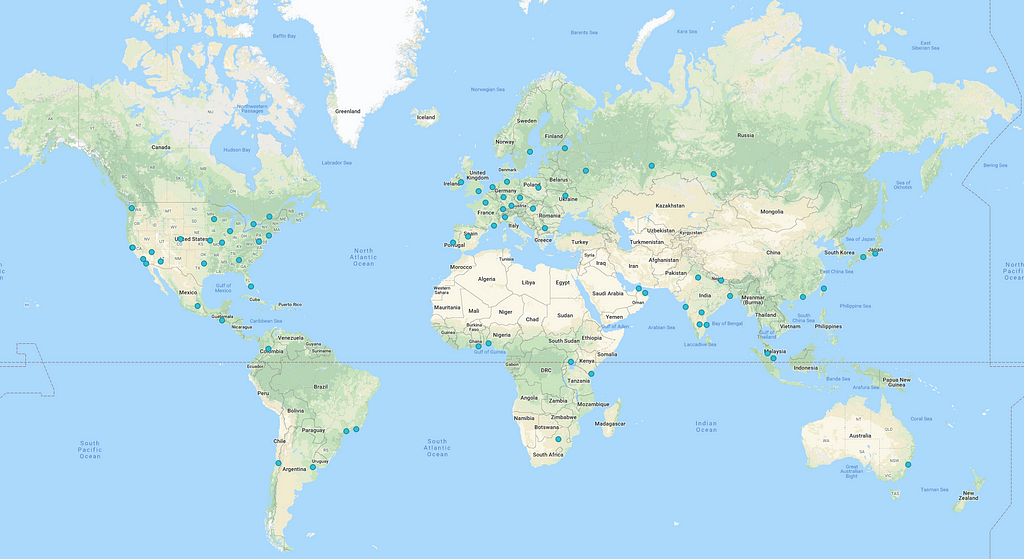 Google’s edge nodes
Google’s edge nodes
So, for many sites, the benchmark for IPFS to improve upon isn’t Kampala to Perth, it’s Kampala to … just down the road from Kampala.
Is peer-to-peer faster?
A little bit. Sometimes. Maybe.
A specific set of circumstances need to be in effect for peer-to-peer to offer an improvement in speed.
First of all, a peer running an IPFS node must exist with the file you want. So if you’re the first person to visit a new page in your area, you won’t have a peer. The less populated an area, the less likely this will be. And the less common the site you’re visiting, the less likely it is to be cached nearby.
Secondly, if a peer does exist, with your file, connecting to them needs to be faster than connecting to the source, which is not a given (even if the peer is 100m away and the source is 10,000 kms away).
This requires going into a bit of detail …
Peer-to-peer is actually a bit of a misnomer — it’s more like peer-to-ISP-to-peer. So to assess peer-to-ISP-to-peer, we must line it up against peer-to-ISP-to-source.
Or to boil it down a bit further, p2p is only going to be faster if your ISP can get a file from a peer of yours more quickly than it can get that file from the source.
But the infrastructure from the ISP to a peer is inferior to the infrastructure from the ISP to the source.
A world where p2p is slower is not so hard to imagine:
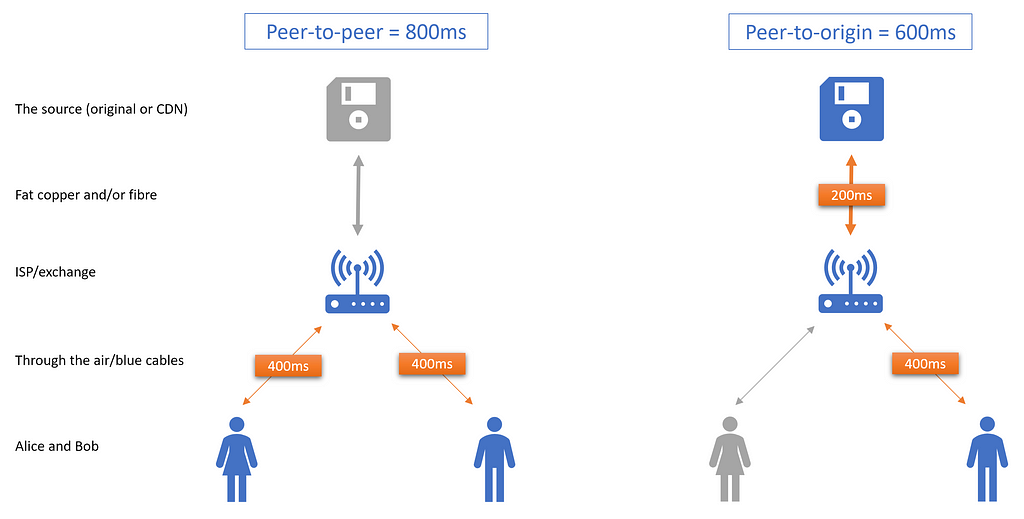 If ISP-to-user is slower than ISP-to-source, then peering isn’t faster.
If ISP-to-user is slower than ISP-to-source, then peering isn’t faster.
I’m assuming here that an IPFS node (that your peer is running) will be able to respond to a request for an asset in the same time that existing infrastructure does.
If, however, and IPFS node running on a librarian’s PC takes 100ms to respond to a request for a file, but an Amazon CloudFront edge server takes 1ms, then peer-to-peer is at a significant disadvantage.
You may have spotted something interesting in my amateur diagram that uses a save icon to represent a server: the one thing that’s guaranteed to be faster than everything else is peer-to-ISP (with no second hop).
I think this is where IPFS can/will make a big difference. If every ISP had their own IPFS nodes running in their exchanges, that reduces requests from the ISP out to the wider internet (and out to peers).
In countries where the outbound pipe is congested (e.g. Papua New Guinea), this frees up international bandwidth making everything faster, whether it’s using HTTP or IPFS.
This caching-at-the-exchange is such a great idea that it’s exactly how Netflix and YouTube videos are delivered — both companies install physical devices at exchanges to host content close to the user.
It’s one of those rare scenarios where everyone wins. The greedy ISP can cache content at their exchange, lowering the amount of traffic between it and the internet backbone. The greedy content providers have less bandwidth and less load on their servers. And the greedy consumer gets the content more quickly because it comes directly from the exchange.
The distributed Google machines make up the Google Global Cache, and there’s a lot of them:
 These are physical appliances, filled with YouTube, running in exchanges
These are physical appliances, filled with YouTube, running in exchanges
Google says that 70% of Africa traffic is exchanged without leaving Africa, in this weirdly formatted pdf describing new caching/peering strategies being trialled in Africa.
Netflix does the same thing with their Netflix Open Connect appliance which they plug in at a decent number of exchanges.
Keep in mind all of this is for static content. When you open Amazon.com and shop for clocks with sheep on them where the arms are sheep arms, it still needs to go back to the Amazon servers and do a database query and return the search results, and this is a significant proportion of the site load time.
To recap, latency is a thing that IPFS can and will improve. But the room for improvement isn’t huge, and it will probably only be noticeable if you live in a poorly connected place, and your ISP runs an IPFS node or a peer runs an IPFS node and has already downloaded whatever asset you’re trying to download and can respond to a request more quickly than it can be fetched via the internet backbone.
So, that’s everything you didn’t want to know about latency, but are somehow still reading.
Now to look at bandwidth, here’s that chart again, showing that increasing bandwidth (left) makes little difference to the load time of an average website once you get over 4Mbps.
Load time average for the top 25 websites (in 2010)
But you can see that a step from 1Mbps to 2Mbps makes a huge difference. So I went looking to see what internet speeds are like in the worst countries.
I was quite surprised to see that the country with the slowest mobile bandwidth — Libya (that’s not the surprising part) clocks in with 4.3Mbps (that’s the surprising part). That’s the average for the worst country in the world, on mobile!
By contrast, the average speed in the USA a mere ten years ago was 4.2Mbps, and that’s not on mobile.
Overall, 82% of users have internet faster than 4Mbps (see page 4 here). Five years ago, only 46% of users experienced this speed (page 5). Of course, a lot has changed in five years, so this is like comparing apples with five year old apples.
To summarise, speeds are surprisingly good, and getting better surprisingly quickly, and when IPFS is really picking up steam a decade from now, the HTTP internet will be even faster.
If I was to place a bet, I would say that in 10 years’ time, when IPFS is mainstream, the internet will not be noticeably faster.
(And the really fast sites will be those where web developers have made an effort to build a fast site — it’s really not that hard.)
So in summary, IPFS is awesome, beware the folk promising things that aren’t likely to come true, and god bless the internet.
Dumb idea of the week
Kincoin.
Kincoin is an ancestry blockchain, storing the history of every person who has ever lived, all the way back to Noah. And from this day forward, all births, deaths, and marriages will be entered into the kinchain.
To get things rolling, I’ll reach out to the Mormons, who have a list of two billion people stored in a hole in a mountain.
It will cost some small amount of kincoin to make an entry, to deter vandals. There will be built-in dispute resolution using some clever sort of calculation based on how many of the surrounding relations are ‘yours’. So if you want to say your great great, etc. granddad was Henry the 8th, but so does Henry the 72nd, the latter will win out.
It will be globally-minded and not make assumptions about ‘christian names’ and ‘surnames’ and monogamy and cloned children.
Records, such as scans of birth certificates, wedding photos, and why not even DNA will also be stored, via links to the InterPlanetary File System.
So years from now, if medical needs arise, you will be able to look up anyone’s DNA (when everyone gets over this whole ‘privacy’ thing that people keep moaning about).
Now I sit back and wait for someone to tell me it’s already been done.
Thanks for reading this incredibly long post. Ciao!
A crypto-trader’s diary — week 11; storage coins was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.