Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
This informative and technical story tells everything about Ethereum and its pitfalls that we’ve encountered while binding Ethereum blockchain to our product, DreamTeam, the first esports and gaming recruitment and management network. At the time of writing this article, the total number of registered users on our platform stands at more than 500,000.
Blockchain, on our platform, handles all operations in regards to payments. All “money related” operations are processed with the use of Ethereum smart contracts. Smart contracts are needed when users create teams, add or remove players, receive compensations, transact between each other, etc. Blockchain and smart contracts are used in such situations to guarantee payments and avoid scams, which are unfortunately, fairly common in esports.
Numbers
We opened our Blockchain solution on the Ethereum test network for our users on Friday, March 30. So far, around 45 days after the launch, we have reached 50,000 mined transactions made from our master account, which manages teams and payouts on our platform. This is approximately 42 transactions per hour, or 0.25% of the total Ethereum network capacity (considering consumed gas), which is quite impressive when the timeframe is taken into account.
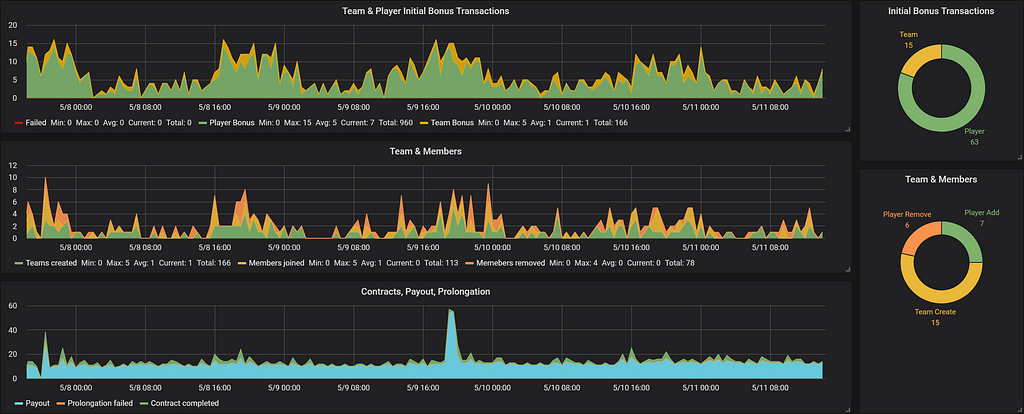 Blockchain transactions on DreamTeam with 30 minute interval
Blockchain transactions on DreamTeam with 30 minute interval
These numbers will change once we migrate to the live Ethereum network (mainnet), as the majority of transactions won’t take place there. There’s a couple of reasons behind that:
- The current majority of transactions are just initial bonuses which players and teams receive once they “activate” their blockchain wallet. We’re not going to give bonuses on the live network, hence the number of transactions will drastically decrease in the beginning (currently over 63% of transactions are initial bonuses).
- Only a percentage of users on our platform are expected to use “blockchained” teams and payments once this transitions to real money — again decreasing the number of transactions.
Taking these two points into account, we expect that only around 10% of all transactions to take place on the real Ethereum network, if not less, resulting in 0.025% of the total capacity of Ethereum network theoretically occupied by our business with approximately 4 transactions happening every hour.
However, this statistic does not take into account that almost 80% of the transactions happen during peak periods (see the chart above), which makes either:
a) A high price for Ethereum transactions to be mined in a rational amount of time during peak periods (~$0.25+ fee per token transfer transaction);b) A long wait time for cheaper transactions to be confirmed (more than 10 hours for a ~$0.15 fee transaction).
That is, the truth behind the current “traditional” blockchain solutions — they are not as scalable as regular data platforms. Once the public blockchain becomes popular, it will eventually become expensive to use. Hence Ethereum, as the most popular public ledger of transactions, being pretty expensive right now. And in our case, as well as in the cases of other businesses, the constantly growing number of users and upcoming features will definitely make Ethereum’s transaction rate higher, which may drive Ethereum to be only a short-term solution for our “Token economy”.
We are aware that the Ethereum blockchain is not yet scalable, which I did mention in my previous article. The upcoming sharding feature in Ethereum will, possibly, drastically increase the network throughput, but, in the case it happens too late we may decide to move to another blockchain platform. There are many out there. However, there are yet to be any that are as popular and reliable as Ethereum.
So, this article is all about Ethereum!
body[data-twttr-rendered="true"] {background-color: transparent;}.twitter-tweet {margin: auto !important;}
Sharding is coming. https://t.co/Aqo9MBiCj0
function notifyResize(height) {height = height ? height : document.documentElement.offsetHeight; var resized = false; if (window.donkey && donkey.resize) {donkey.resize(height); resized = true;}if (parent && parent._resizeIframe) {var obj = {iframe: window.frameElement, height: height}; parent._resizeIframe(obj); resized = true;}if (window.location && window.location.hash === "#amp=1" && window.parent && window.parent.postMessage) {window.parent.postMessage({sentinel: "amp", type: "embed-size", height: height}, "*");}if (window.webkit && window.webkit.messageHandlers && window.webkit.messageHandlers.resize) {window.webkit.messageHandlers.resize.postMessage(height); resized = true;}return resized;}twttr.events.bind('rendered', function (event) {notifyResize();}); twttr.events.bind('resize', function (event) {notifyResize();});if (parent && parent._resizeIframe) {var maxWidth = parseInt(window.frameElement.getAttribute("width")); if ( 500 < maxWidth) {window.frameElement.setAttribute("width", "500");}}
Ethereum Integration & Backend Architecture
Things always get a bit complicated once we start dealing with real value. Regarding blockchain, it is important to build a system which ensures that none of the transactions get lost on their way to the Ethereum network. I would like to share some of the pitfalls we have encountered during the development of our project.
Technology Stack
We use microservice architecture along with continuous integration, where the blockchain solution consists of four logical parts:
- Solidity with Truffle framework for development and deployment of Ethereum smart contracts.
- Geth blockchain client node.
- NodeJS backend with MongoDB.
- RabbitMQ message broker for all blockchain transactions.
Let’s briefly walk through all technical internals and discuss why we have decided to build the platform this way.
Backend
Ethereum was made for the decentralized web, and the main tools for this platform were written on JavaScript. Thus, the most straightforward decision regarding backend was NodeJS. We also decided to use MongoDB, a “traditional” document-oriented database for NodeJS, which seamlessly integrates with JavaScript.
One of the most important parts of our backend architecture is the use of the RabbitMQ message broker. For those who are unfamiliar with RabbitMQ, I recommend you read this or this. In short, RabbitMQ is a dedicated service to which other services (like our blockchain service) push “messages”, and then those “messages” are consumed by other (or the same) services.
Using RabbitMQ has many advantages. But in particular, before we even publish a transaction to the network, we first send a “transaction publishing request message” to the message broker, which is then picked up by workers that actually publish the transaction to the Ethereum network. This allows us to implement the following tricks:
- The message sits in the message broker queue until it is processed, which minimizes the risk that the transaction will not get published due to various reasons (network failures, outages, human error, etc.).
- Publishing transactions to the queue allows us to easily stop processing blockchain transactions for a while (temporary killing message consumers), do some maintenance and then resume transaction processing (bring consumers back). All messages will simply stack in the queue until they are all released and processed after any platform scheduled maintenance.
One of our smart contracts is upgradeable, and we successfully use #2 to upgrade the contract in the production environment without any observable downtime.
Truffle Framework for Ethereum
At the time of writing this article, Truffle is the most popular framework for Ethereum development. It has a nice API which abstracts developers from low-level Ethereum stuff (like assembling and signing raw transactions, compiling Solidity code, working with smart contract ABIs, etc.), but also introduces some patterns which may or may not fit into the workflow of some projects.
In Truffle, in order to deploy a smart contract to the network (or to do any initial setup in regards to smart contracts), you are supposed to write migration scripts in JavaScript, where each migration only runs once, sequentially, one after another for each network setup. According to the concept, the first migration deploys a little smart contract (Migrations.sol) to the network, which Truffle then uses to keep track of which migrations have already been run on the network. Once this smart contract is deployed, its address is recorded to an artifact file (Migrations.json). Truffle reads this file in order to understand which migrations were run and which were not.
Now, suppose you want to deploy a new smart contract and then (possibly later) call some “initialization” method in it, you need to write three migration scripts, which will:
- Deploy a migrations smart contract.
- Deploy your smart contract.
- Call the initialization function in your smart contract.
Note that the last two actions can be merged to a single migration script; I used 3 scripts to demonstrate that migrations are atomic actions which you develop one by one and then run one after another.
These migration scripts, once run by Truffle, produce the following transactions on the network:
- Migrations smart contract deployment.
- Saving migration 1 to the network (Truffle will make a call to the migrations smart contract).
- Your smart contract deployment.
- Saving migration 2 to the network.
- Smart contract function call.
- Saving migration 3 to the network.
As you can see, in order to do 2 transactions on the network Truffle requires 4 more transactions, resulting in a total of 6 transactions made on the network.
So if your goal is to just deploy a simple smart contract to the network, you may probably want to avoid using Truffle migrations workflow. One of the ways to do it with Truffle (say, deploy smart contracts manually) is to use a single migration script or some manual automation around Truffle migration scripts. In any scenario, you can run all of the scripts in the migrations directory sequentially with truffle migrate --reset (this also does not require Migrations.sol to be present).
Geth Node Syncing
Geth client node runs well only after being properly set up, which, unfortunately, is not a quick process. Running Geth node today (5/18/2018) requires:
- Minimum of 66 Gb of SSD disk space for testnet and 92 Gb for mainnet (some volunteers post statistics where you can track it).
- Minimum of 8.3 Gb of memory.
- Good bandwidth to boot up, but then it uses very little internet traffic (25 kb/min on average).
- Average processing power while syncing.
- The better the disk I/O, the faster Geth node will sync up the state.
It takes around 0.5–2 days to sync the node for testnet, while syncing it for mainnet can take 1–3 days with the above setup.
If you have tried to sync Geth node, you may wonder why Geth syncing sticks at the last 100–200 blocks, while continuing to download “known states”. I advise you to read this awesome post for a detailed explanation of why this happens, but in short, to be “in sync” your node needs to download all state entries before it is ready to process all of your requests. There are more than 140 million out there, which takes 1–3 days to download as mentioned above (depending on disk I/O, network and processor).
Here are some Geth-related charts from our monitors (plotting interval = 1 minute):
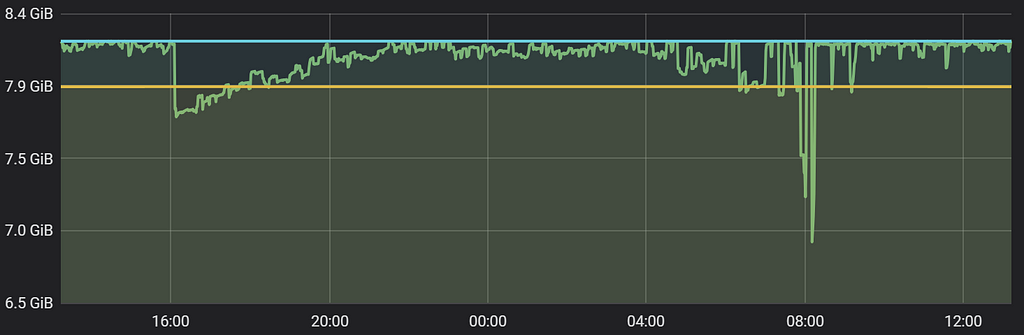 Geth node daily memory usage (after sync)
Geth node daily memory usage (after sync)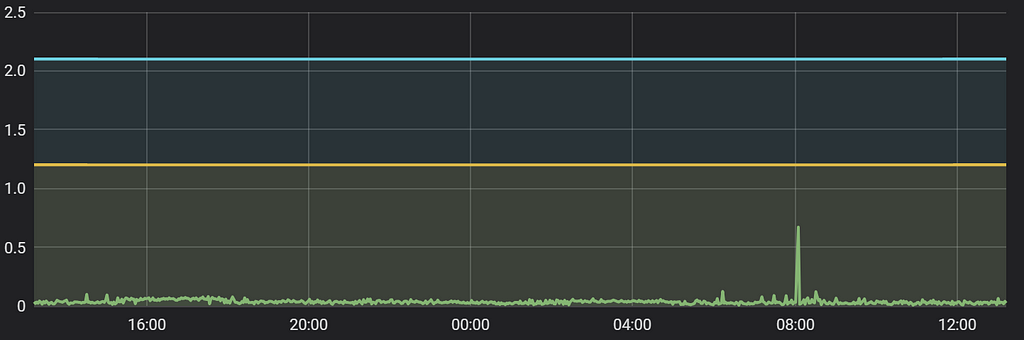 Geth node CPU usage (after sync)
Geth node CPU usage (after sync)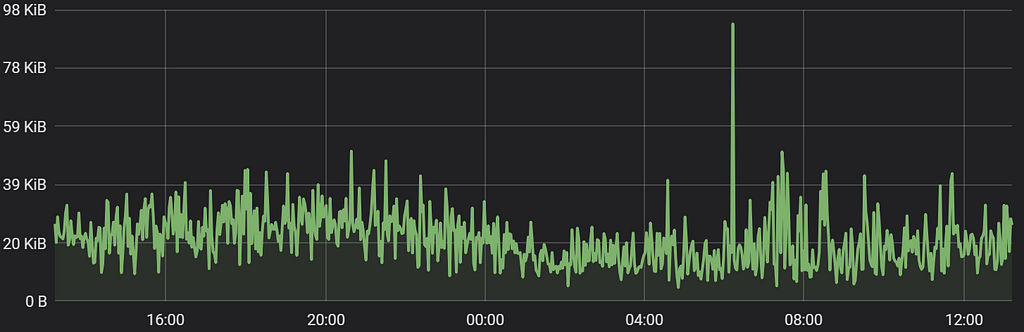 Geth node network usage (after sync)Transaction Publishing
Geth node network usage (after sync)Transaction Publishing
One of the very weird but required things in Ethereum is that each transaction sent from a particular account must have a unique sequential integer, which is called nonce. Nonce numbers are used in Ethereum to prevent double spend attacks. There are two important consequences which this integer introduces:
- All transactions submitted from one account are processed (mined) in series. For example, if you submit 2 transactions with nonce integers equal to 1 and 2 respectively (sequential unique nonce integers for each transaction are a must) to the network, the second transaction will not even be taken into account by miners until the first one is processed (mined). But in the case you submit multiple transactions with sequential nonce numbers to the network at once, there’s a chance that some of these transactions (or all) will be mined in the same block (if you provide good gas prices respectively, but it is also up to the miner whether to pick these transactions or not).
- You need, either, to additionally keep track of each nonce number submitted or just use a single node to prevent nonce collisions.
Point #1 is especially painful if you’ve made such a permissioned smart contract where only one address is authorized to “manage” something and you need to frequently “manage” this smart contract. By setting low or average gas prices and making lots of transactions this can result in almost endless waiting time for new transactions to be mined.
The solution for #1 is to simply split transaction publishing to multiple Ethereum accounts. However, in this case you would never know which transaction will be mined before which. In the case of our smart contracts, we can even assign which team ID corresponds to which account in order to avoid messing up our team management smart contract.
Nonce collisions
Nonce collisions were another mysterious thing we’ve encountered when trying to scale the number of Geth nodes in order to cover the case when one node crashes. It turns out that
 You cannot just take and scale the number of Geth nodes, unfortunately.
You cannot just take and scale the number of Geth nodes, unfortunately.
We used a simple load balancer before the three Geth nodes, which was sending each transaction to one of the three nodes. The problem was that each time we submitted many transactions at once, some of those transactions were mysteriously disappearing. It took a day or two until we finally figured out that this was a problem with nonce collisions.
When you are submitting raw transactions to the network you are fine, because you keep track of nonce numbers yourself. In this case you just need a node to publish raw transactions to the network. But in the case you are using an account unlocking mechanism built into the node and do not specify the nonce when publishing transactions (with web3 or so), the node tries to pick the appropriate nonce value itself and then signs a transaction.
Because of the network delays, in the case two nodes receive the same transaction publishing request, they can generate the same nonce value. At the moment of receiving the transaction publishing request they don’t know that they both received a transaction with the same nonce. Thus, when propagating these transactions through the network, one of them will eventually be dropped because its “transaction nonce is too low”.
To fix nonce collisions introduced by adding a load balancer to a system, we needed to create a different kind of load balancer. For example, a load balancer which always uses one particular node and switches to another node only if the first one is down.
Gas limit
A gas limit is also a very important number. There are two ways you can submit your transaction in terms of a gas limit:
- Just hardcode gasLimit = blockGasLimit (or another number which you believe is enough for your transaction) in your code.
- Estimate gasLimit required for transaction by using something like estimateGas.
I always recommend to use option #2 because it influences the transaction mining time indeed. Processing time of a transaction, in this case, will be much faster.
Also, take note that option #2 is just a strict estimate of gas usage that will be used by running this transaction on the current state of the network. The state of the network can change before your transaction is actually processed, and finally can result in an out of gas exception. I advice to add 1–5% gas to the gas estimated value, and additionally investigate how and what can actually influence your gas estimation before publishing the transaction to the network.
Conclusion
There is no doubt that Ethereum is one of the greatest future-shaping things in the world. But in Ethereum, as well as in any other “revolutionizing” thing there are many points that are not ideal and are yet to be improved. Nowadays, the number of Ethereum analogues is so high that you struggle with which one to choose (EOS, Stellar, Cardano, Lisk and many other promising platforms which are under active development). But Ethereum is still a leader, as the community and historical trust is what really makes this platform.
Soon, I will publish a technical article about our Ethereum solution, where we made a token contract which does not require a user to hold Ether in order to make transactions. Subscribe to stay tuned ;)

Ethereum Blockchain in a Real Project with 500k+ Users was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.