Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 From SOAP to REST and probably GraphQL
From SOAP to REST and probably GraphQL
During my software development career I built and consumed a lot of web services. Usually they were consumed from server side apps built with .NET, One of the biggest project I have worked on was a platform where we merged a lot of data from different sources and displayed the results to the user on a web interface(yes, I was working on some kind of broker firm at that point).
SOAP Web Services — with XSD
Almost all of those web endpoints were using SOAP and they were pretty easy to query because we always got a schema (an XSD) file from our partner. Receiving the XSD is a very good start because the client is generated for you by the tools. On the other hand it is not the best solution, sometimes we had to manually change the generated code because of the differences of stacks between the client and server. Which could lead to issues when upgrading to a new version, because you could overwrite the changes, so we had to spend some time comparing changes in source control and we ended up making the upgrade manually, change by change. The generated code in c# uses partial classes, so theoretically any change that you would need to do can be done outside the generated code. But I still remember cases when the change was so big that we couldn’t do it in another file.
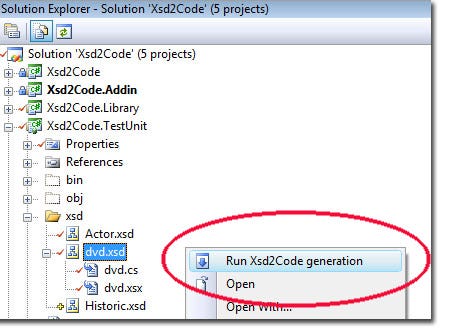 XSD code generation in actionREST — loose coupled web services
XSD code generation in actionREST — loose coupled web services
But nothing compares to the first time we had to use a REST endpoint. This company advertised their new great shiny cutting edge out of this world API. Everything was looking great, until we started to actually build our .NET client for it. Imagine 5 or 6 endpoints each returning tens maybe hundreds of parameters with several levels of nesting. And you had to write those boilerplate properties one by one, browsing through examples, wondering which is an array, if it can be an int or to leave as string and so on.
And then they ask you why does it take 3 months to connect to their new API? Duhhh…
So XSD helped you a lot on day 1: get your client fast at a running state and then worry about future upgrades and versioning later. Most of the time we would consume much more data than needed. I don’t remember spending time removing the fields which we didn’t need to make the process lighter. While on the REST side, there was a lot of code to be written, and that was important because do a mistake there and all your deserialization fails. Indeed we could get to a more flexible client in the end, by adding only the needed fields, but it was an error prone process.
SOAP was still coupling the client and server with that schema generation, while REST came with the real loose coupled promise enabled, just that we weren’t ready for it (at least on the backend side). And because the problem was real, projects like SWAGGER appeared, which translated your api to a open source DSL which other clients can consume automatically. Lately there is an increase of providing some sort of SDK along with the API for REST endpoints, which requires an extra effort but is a step in the right direction, because clients can connect much faster to you. But there are still many companies that lack that understanding.
Entering GraphQL
Now when you hear about GraphQL the main thing that you read about is that you can pick the columns that can be returned from the server. And how great is that for building your mobile and web clients without the needs of creating several REST endpoints just because they need different fields to manipulate and display. If you browse the jobs that have GraphQL as a requirement, you will see almost all in the front end and mobile development. That’s where it is really popular.
What about backend development? If you are building an external API for your product, can GraphQL be a reasonable choice? Do you have any advantages on switching from a REST API with Swagger to a GraphQL one?
GraphQL Schema
For me as an API builder and consumer the most important benefit in creating a GraphQL API is the schema and all the tools it gives you out of the box for versioning it.
GraphQL offers a schema out of the box with scalar and complex types (which are made of other complex types or scalar types), queries, mutations (whihc are also some special types) and many other elements that help your API definition.
In the image below (screenshot from https://www.graphqlhub.com of the Twitter API — not official) you can see a Tweet object composed from some scalar types like String, Int, ID and a few object types like TwitterUser or Retweet.
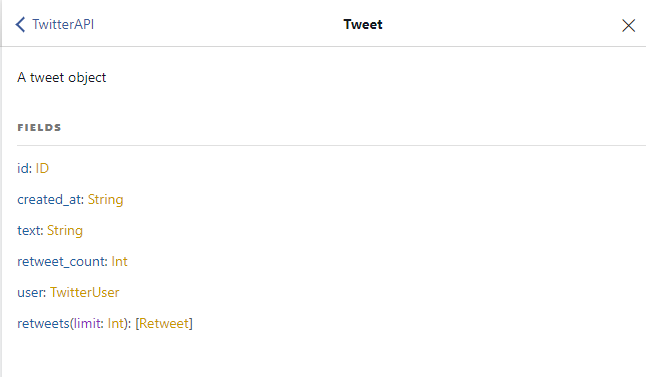 TwitterAPI defined at GraphQLHub.com seen in a Graphiql UI
TwitterAPI defined at GraphQLHub.com seen in a Graphiql UI
When the industry moved from SOAP to REST it took a while to understand the new concept. That there weren’t anymore methods exposed on a protocol, but the schema was about creating endpoints and exposing data around those endpoints. With REST it was about using Uniform Resource Identifiers and how the HTTP verbs can be transformed into actions. The same path it will apply to the transition to GraphQL. Like I said, first time you read about it you see that you can chose your columns on the client. Then you find out that it has a schema with types, which is a big advantage over REST. And maybe just after that or maybe a few more steps you will realize that in order to build a GraphQL API it is all about seeing data as graphs. When you start defining a new schema, it is not about exposing methods, or creating endpoints, it is actually about how your data is connected because it always is.
It’s graphs all the way down
Lets take a simple example, but complex enough to explain the concept: books and authors. In a REST architecture you would build 2 endpoints, one for authors and one for books. Thinking about the GraphQL schema, it is clear that there are going to be 2 types: Author and Book and a query to expose those 2 types. But these objects are closely related, because an author has written one or more books. So on the Author type we will add a list of Books.
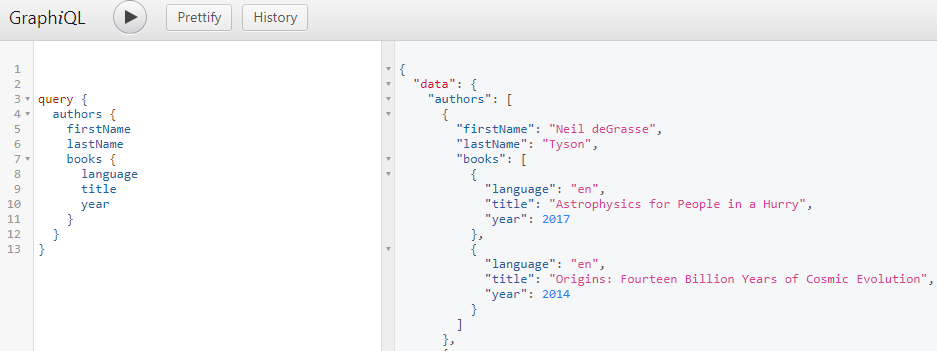 authors query — an author has a list of books
authors query — an author has a list of books
Even more, the relation between authors and books is n to n, because a book can have more than one author. Which is exactly the case in our example, the book Origins: Fourteen Billion Years of Cosmic Evolution was written by 2 authors: Neil deGrasse Tyson and Donald Goldsmith. Which means we will add a list of authors to our Book type and we already have a cycle in our graph.

And now we have the full information in one query: we have the author with his books and we can also include all the authors of a book if we need the info. So it is not anymore about endpoints and URI, instead it is about the data and the connection between the nodes of the data. And on our GraphQL query we can clearly see the relation between our types.
Thanks for reading. Btw, if you are from Iasi, Romania you can join my free GraphQL in .NET Core workshop happening on 5 June. Being a workshop there are limited places, but if many more people are interested we can have a second run.
You can also register for my newsletter for software developers interested in .NET technologies. I am planning to send that twice a month, starting June 2018.
GraphQL APIs for backend devs was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.