Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

I recently had a project, where I needed to create references to one collection in another collection. Referencing databases or collections is a common need with data. With document based databases, creating these references is fairly straight forward if you are creating the data from scratch, but sometimes becomes a little more complicated if you already have collections, and need to retroactively create references between the collection items, which was my case.
My project involves text from speeches, and I’ll briefly explain my scenario, and how I solved it with Python, and hopefully go over some tools that you can integrate into your own projects. Here’s the basic scenario:
1 — Relationships Between Collections: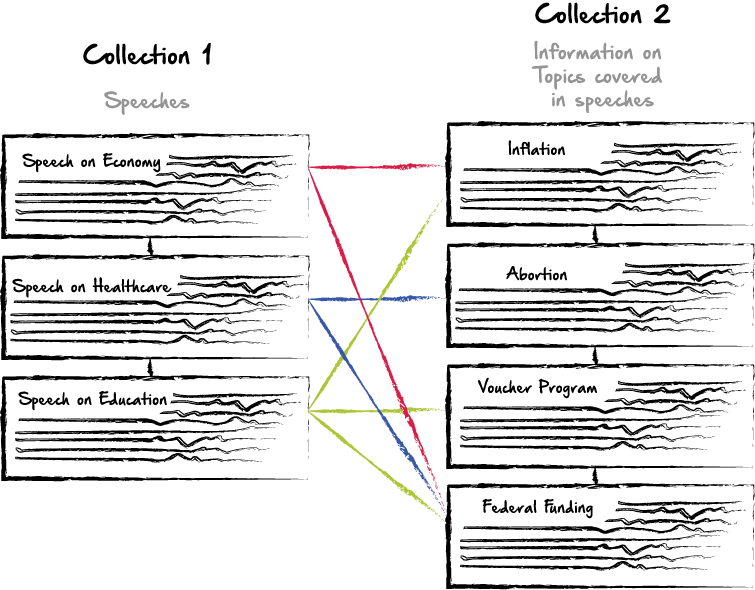
In my case, I have speeches in one collection. Then, I have information in a separate collection. In each ‘speech’, a speaker might reference any number of topics that a user might want more information on. Each record in the information collection is basically a small paragraph describing a specific topic, while the speeches are long, and cover multiple topics. So the relationship between the two collections should be One to Many, or Many to Many, since one talk will reference multiple topics, and one topic will be associated with multiple speeches. Since I’ll be working with a document based database, I won’t be using tables, but I’ll use python to add and create these relationships. The first thing I thought of doing was, if I found a match, to actually add that entire info section to the first database. That structure might look like this:
Solution 1 — Combining two collections into one collection:
However, this isn’t a great idea, and you can quickly see why. That’s a ton of text in each collection. If a user has to fetch the entire database, or even only one entry at a time, the load times could be pretty large, and wouldn’t be a good user experience. A better solution would be to only add the references from one database to the other. This is similar to the way that SQL databases work anyway, by simply adding the id of a referenced collection to the first collection or table. So we’d basically be adding those same references in a mongo database. The new structure would look like this:
Solution 2 — Adding References from One Collection to another Collection:
Now, the process of actually finding those connections could be a process as well. Typically, in an SQL database, you would have a join table for these many to many relationships. For example, we might have a table of topics. And if a speech contains a topic in that table, and an information record also contains that topic, we would link the information and the speech through the joined topics table. I’ll do a similar scheme with Python, but instead of a table, or even a second database, I’ll just have an array or list of the topics I’ll search for, add the connections to each collection, and then I can get rid of the list, or save it for later use. But either way, I don’t need to add that list as a separate collection. Here’s what that process might look like in pseudo code:
Identifying Related collections with a “Join” Collection: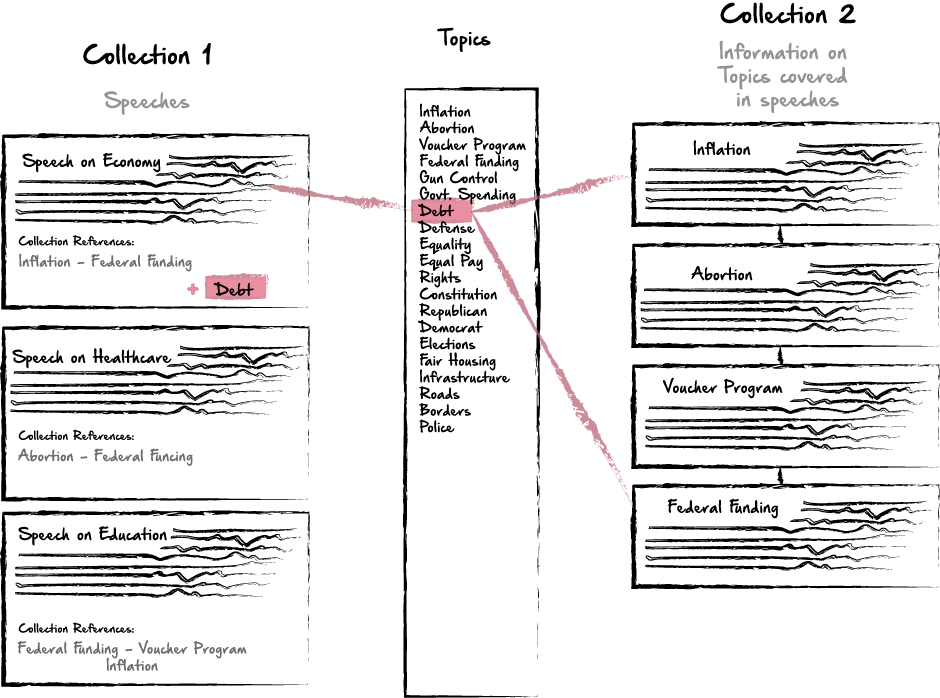
You can see here, my general thought process on this is to have this array, and most likely I would start by looping through the speeches collection. Then, if any topic is in the array of topics, I would then loop through the information collection…if that topic is also found in any of those records, I would take the ID from the information collection, and add it in a reference object within the speeches collection.
Pretty simple stuff. There are at least a couple of ways to get started with this process, and it depends largely on where your collections are stored. If they are stored in an online database like mlab, then we would need to import requests to access the database. However, if they are stored in a local database, or in a json file, we could simply access them locally, or read from a json file.
Reading from a local database:
import pymongofrom pymongo import MongoClientclient = MongoClient('mongodb://localhost:27017/')db = client.politicsspeeches = db.speechesIf we already have the database, but it’s stored locally, here’s how we would access that in python. We would need to import pymongo, and MongoClient, and then access our database, and then the collection we want. Here, our current collection, speeches, is now saved as the variable called speeches, and at this point we can loop through it as we please.
Reading from a JSON file:
import jsonwith open('speeches.json') as f: speeches = json.load(f)If our data is stored as a JSON file, we could simply import json, and then use the with open command and access our data that way. Here, our data is now saved in the variable speeches, and we could loop through that as needed.
Reading from an online database:
import requestsimport jsonspeeches = requests.get("online/database/speeches/url")If however, we are trying to access the database from online, we would import requests and also import json. Here, our speeches are saved in the variable speeches, and we could loop through them by using something like, for i in speeches.json():
At this point, if we’ve imported our speeches, wherever they are, we would also need to import our collection of topical information using a similar method.
Looping through the data:
There are probably a lot of ways to do this as well, but assuming our topic list isn’t too large, we could probably quickly extract the keywords and topics we wanted to search for in both speeches and topical information collections. It may be easier to do this manually. Or there are also great APIs for extracting keywords from large amounts of data, which may be an option. Now, let’s assume the data structure for our speeches and topical information is the same. Something like this for speeches:
Database Structure:
{"_id": "54893893","title":"speech on the economy","text":"...blab, blah, blah...","references": []}And then a similar structure for topical information:
{"_id": "HEJENSHENAH","topic":"speech on the economy","text":"...blab, blah, blah...",}We could set up our loop in python, which could look like this:
Basic Python For Loop:
for s in speeches: speechArr = s['text'].split(" ") for i in speechArr: if i in topics: for info in information: infoArr = info['text'].split(" ") for x in infoArr: if x == i: s['references'].append(info["_id"])Now, there are probably simpler and more efficient ways to do this than what I came up with, but basically we loop through the text of the speech, broken up into an array. If any of the words match a word in topics, then we loop through the topical information collection and see if the text in any of those paragraphs also matches the current topic. If there is a match, we add the id of that record to the references array in our current speeches record.
If we had an array in our code, at we could push the modified data into a new array, which we could then write to a new database, save as a new JSON file, or update a current database with.
import jsonwith open('speeches.json') as f: speeches = json.load(f)newSpeeches = []
for s in speeches: speechArr = s['text'].split(" ") for i in speechArr: if i in topics: for info in information: infoArr = info['text'].split(" ") for x in infoArr: if x == i: s['references'].append(info["_id"])newSpeeches.append(s)
Inside this loop, we could also do other things to each record in the collection. For example, if we wanted to add fields in our collection, we could do that inside the for loop. We could do that, inside our loop with the following line of code:
i[‘new_field’] = []
if we wanted the new field to be a list. Then, we could append data to the list inside our collection.
At this point, after looping through the data, we could either push the new collection up to an online database, or save it to a local file, which is contained in our variable, newSpeeches.
Inserting into a local collection:
In a previous example, I mentioned how you could access a local database. If that was our method and we want to now insert the new record into a local database, we could do that this way:
speechObject_id = speeches.insert_one(speechObject).inserted_id
We would need to make sure we are writing to the appropriate variables here.
Saving to a local JSON file:
If we opened a JSON file, or even if we used another method, we may want to save the new collection to a local JSON file. I think this is a good idea, as you’ll have a backup if something happens to a deployed database. Here’s how you would do that:
speeches = []
with open('myspeech.json', 'w') as outfile: json.dump(speeches, outfile)If all of our newly referenced collections are being stored in the speeches variable, then we would use that, and write a new json file with that information, obviously needing to import json here.
There are obviously a lot of ways that we could tweak this, and probably a lot of things I did wrong, or that might improve this process, so if you have any feedback, or want to point out all of my many mistakes, feel free! Thanks!
https://www.linkedin.com/in/ethanjarrell/

Basic Database Interaction-Python was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.