Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
 Created with https://canva.com
Created with https://canva.com
Puns definitely intended, keeping some connections alive is essential for a healthy life in reality and production.
Redis Pubsub is pretty awesome, along with the swiss-army-knife-esque Carmine — all-Clojure Redis client(Clojure as we at Swym like our functions lispy :)). Redis standard documentation can be interpreted as Pubsub connections are undying, meaning they can survive long idle times.
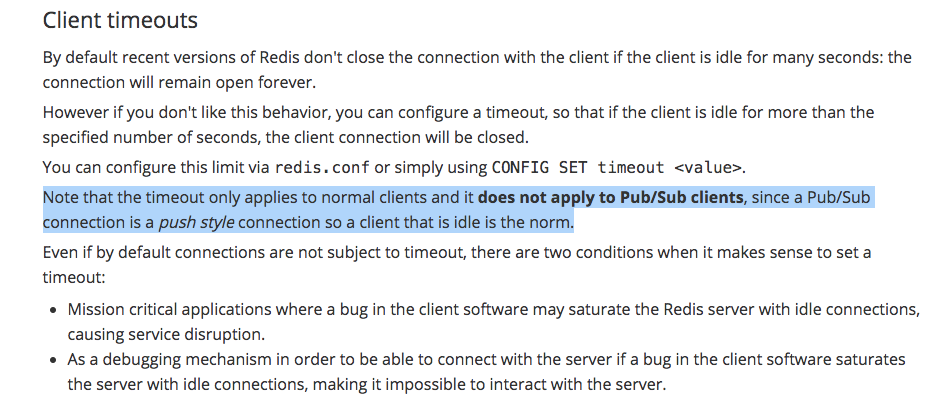 Source — https://redis.io/topics/clients
Source — https://redis.io/topics/clients
Sounds like the perfect story. And like every perfect story, it is not perfect :/, a paradox. Redis client connections have been the topic of numerous discussions, across tech stacks (Issue links at the bottom of the post).
- How does one ensure long-living connections or undying connections for their Pubsub clients?
- How do the connections get recycled without holding on to deadbeats, in the client connection sense?
- What is the best config to handle this? Surely we are not the only ones on the face of this planet to encounter this
At Swym, we have scenarios where Redis Pubsub pushes out events primarily to purge any cached data. The cache is distributed across load balanced services. Hence the events need to reach the far depths of the service to really purge all relevant data.
That’s the crux.
So it is critical for it to be healthy. Thanks to some inexplicable issues with our Redis service on Azure, our Pubsub connections will die out for “no” reason. Ideally, we would like to be alerted when those go down, so something can be done, or even better, to keep them alive as much as possible.
Are you alive even?
According to the client, the connection is alive. According to the Redis server, the connection is kinda alive, but not really.
Here is an example
 Client state 1
Client state 1 Publish 1
Publish 1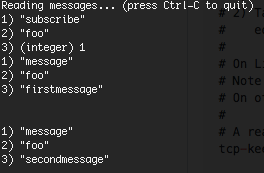 Subscriber 1… A few minutes later …
Subscriber 1… A few minutes later … Connection state 2
Connection state 2 Publish 2
Publish 2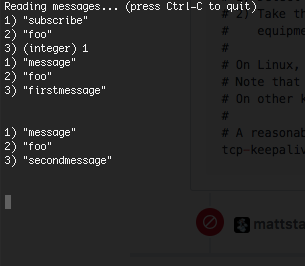 Subscriber 2 — nope, can’t hear you
Subscriber 2 — nope, can’t hear you
Another case is when Redis clustering kicks in with secondary shards, kinda rendering the previous connections invalid, or the Redis instance decides to reboot.
So we had two main issues
- Connection failures are not notified as an “error”, in most cases. These are system failures and should be reported to devops/tools so something can be done about it
- Connections should not fail because of idleness. The connections should continue to survive periods of radio silence, reducing the number of stale connections (read 1).
One potential way to manage TCP timeouts - by setting tcp-keepalive to some reasonable value instead of defaults (300 in my case). > https://github.com/antirez/redis/issues/1810, but as you see in the screenshots, the connection “existed” at 322, maybe my client TCP needs to be configured as well. This seems like a configuration issue, or is it?
Using the source
Carmine is a great library with all things one can think of, and shoutout to Peter Taoensso for putting such awesome pieces of Clojure out there. I started with a reading of the source, like Master Yoda would counsel (may his memory last longer than these redis connections :/). I was happy to see a few outstanding issues and code TODOs in the source.
The issue has been open for years. So, naturally, this presents an opportunity to roll up my sleeves and figure out a way. Redis (v3.2+) has had “PING” on Pubsub connections for a while now. This means that connection idle time can be managed with a series of heartbeat pings.
Here is how carmine’s with-pubsub-new-listener works
- Start a long-running thread with a future-call to poll on the connection socket stream
- When a reply is received, pass it back to the message handlers.
There is one big issue with this — as a Clojure future catches an error within the thread of execution and does not notify anyone unless another thread tries to realize the future. In this case, the future never finishes evaluation unless there is a socket read/timeout error. This needs a timely poll to check the evaluation state of the future. Here is some code to show that,
(require '[taoensso.carmine :as car]);(def conn-spec {:host "localhost" :port 6379}) ;; replace with your spec(def l (car/with-new-pubsub-listener conn-spec {"ps-foo" #(println %)} (car/subscribe "ps-foo")))(realized? (:future l)); false(def l-status (future (while (not (realized? (:future l))) (println "realized" (:future l)))));;realized #object[clojure.core$future_call$reify__6962 0x154a8d5 {:status :pending, :val nil}];;...... A lot of logs later ......
;;realized #object[clojure.core$future_call$reify__6962 0x154a8d5 {:status :failed, :val #error {; :cause nil; :via; [{:type java.util.concurrent.ExecutionException; :message java.io.EOFException; :at [java.util.concurrent.FutureTask report FutureTask.java 122]}; {:type java.io.EOFException; :message nil; :at [java.io.DataInputStream readByte DataInputStream.java 267]}]; :trace; [... <<truncated>> ...]}}];;That doesn’t sound like the best use of CPU cycles. So first thing, add a way to callback an error handler in the future-call — This will allow end clients to be notified of connection failures and retry based on the exception.
Next up, add a future call to PING in case there are no messages received after a specified timeout ( ping-ms in the conn-spec, default to 30 seconds). Add timely heartbeats when the connection goes idle.
With those two in place (using my new library :)), here is what it looks like,
(require '[taoensso.carmine :as car])(require '[redis-pubsub.core :as pubsub])(def keepalive-l (pubsub/with-new-keepalive-pubsub-listener conn-spec { "ps-foo" #(println %) "pubsub:ping" #(println "ping" %) "pubsub:listener:fail" #(println "listener failed - add try again" %)} (car/subscribe "ps-foo")));; prints ping [pong pubsub:ping] after 30 seconds of idleness
;; When listener fails, immediately a callback is fired; listener failed - add try again [pubsub:error pubsub:listener:fail #error {; :cause nil; :via; [{:type java.io.EOFException; :message nil; :at [java.io.DataInputStream readByte DataInputStream.java 267]}]; :trace; [... <<truncated>> ...]}]After running test cases successfully, time to share the goodness with other people. There is a Pull Request opened on the main library project, but it could take a while as I might have broken other deeper test cases (I hope none). So here it is as an add-on library (my first on clojars, yay!) that can be included with carmine. With that, you can give your connections the heartbeat they need.
Thanks for reading! Do try it out and let me know how you have handled it in your Clojure services?
Shameless plug — If you are interested in being more than a reader, let’s work together —we are actively looking to work with cool people like you :)!
References
- https://groups.google.com/forum/#!topic/redis-db/MwHnkLLs070
- https://github.com/andymccurdy/redis-py/issues/386
- https://stackoverflow.com/questions/8678349/subscription-to-redis-channel-does-not-keep-alive
- https://github.com/ptaoussanis/carmine/issues/15, https://github.com/ptaoussanis/carmine/issues/201
- http://rossipedia.com/blog/2014/01/redis-i-like-you-but-youre-crazy/
P.S:
You have come this far :), maybe you’d like my other Clojure posts too, just putting it out there -
Keeping your connections alive — A Clojure - Redis story was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.