Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Let’s see how we can train a bot to evacuate the building in minimum time [Source]
[Source]
[Source]
I found Painless Q-Learning as one of the best sources over the internet to get started with Q-Learning. Apart from this Basic Reinforcement Learning also helps me to take an informed step in this field. This blog is highly inspired from Painless Q-Learning, I would be coding out the same example that has been mentioned there.
This blog assumes the reader to have an understanding of about Q-Learning. If not, do read this Painless Q-Learning and then come back to see the implementation of the same example. I will be making a dedicated blog on explaining Q-Learning in near future.
Let’s code…
class QLearning: def __init__(self): # initializing the environment here # ideally should have made a different class self.state_action_mat = { 0:[4], 1:[3,5], 2:[3], 3:[1,2,4], 4:[0,3,5], 5:[1,4,5] } self.state_action_reward_mat = { (0,4):0, (1,3):0, (1,5):100, (2,3):0, (3,1):0, (3,2):0, (3,4):0, (4,0):0, (4,4):0, (4,5):100, (5,1):0, (5,4):0, (5,5):100, } self.q_matrix = {} self.goal_state = 5 self.gamma = 0.5 self.episodes = 50 self.states = 6I made a class to handle all the functions required in the learning process, also I have initialized the environment here (should have done under Environment class), but it’s ok for now. Here is some specification about the variables from the initialization function.
- state_action_mat: Is a dictionary holding possibilities of direct state transition from one to other. e.g. Our bot can go from state 4 to 0, 3, 5 also similarly it can go from state 2 to 3.
- state_action_reward_mat: Is a dictionary holding start and end states as the key and reward for the transition as value.
- q_matrix: This is the variable that we will learn over the learning process. You can think of this as the brain/memory of our bot.
- goal_state: Final exit state or termination state.
- gamma: This parameter varies from 0 to 1. It can be seen as the weight our bot should give to the future rewards. A value near 0 means less exploration and giving high weight to intermediate rewards and not thinking of long term. It is a hyper-parameter that can be tuned for better performance of our bot.
- episodes: You can think of this as number of life in a game. A life is defined as once achieving an end state. It is again a hyper-parameter that can be tuned for better performance of our bot
- states: Total count of the possible states.
You can see the pictorial view of the environment below:
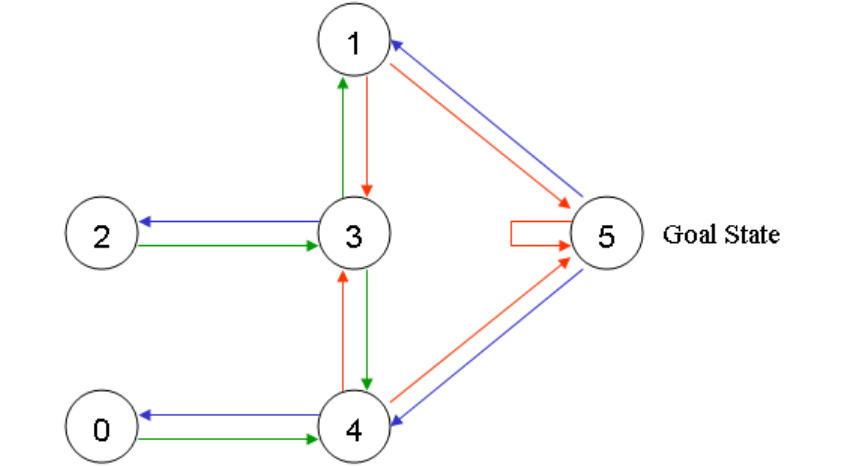 [Source]
[Source]
Here each node in the graph is a room in the building. The arrows show the connectivity from one to other. We define each room as a state and each arrow as the action.
# Instance of QLearningqlearn = QLearning()# initialize Q-Matrix to 0(Zero) score valuesqlearn.populate_qmat()# loop through multiple episodesfor e in xrange(qlearn.episodes): # start with initial random state initial_state = qlearn.random_state() start = initial_state # steps taken to reach the goal steps = 0 # path path = [] # till goal is reached in each episode while True: steps += 1 # find action from a particular state with max Q-value action = qlearn.find_action(initial_state) # set this to next state nextstate = action # find qmax for the next state qmax_next_state = qlearn.max_reward_next_state(nextstate) # update the q matrix reward = qlearn.state_action_reward_mat.get((initial_state, action)) # transition not possible from state to state if not reward: reward = -1 # update the Q-matrix qlearn.q_matrix[(initial_state, action)] = reward + qlearn.gamma * qmax_next_state # path update path.append(initial_state) # traverse to the next state initial_state = nextstate if initial_state == qlearn.final_state: print ('Reached the goal in the episode number {} in {}'.\ format(colored(e, 'red'), colored(steps,'green'))) path = [] breakThe above snippet is an iterative process over episodes that we do to make our bot learn optimal path over time. We start by initializing q_matrix to Zeros, considering that bot has no memory when it starts learning. We start with certain random state and take an informed decision of transition to go to another state by choosing a state which has maximum q-value. Now, considering this as a new state, we look for the maximum q value that we can get from transitioning to any other possible state. Next, we calculate the reward of going from current state to next and put that all in the Q-Learning formulae
 [Source]
[Source]
which updates the brain of our bot with some knowledge of the environment. At last, we set next state to current state showing the transition till goal state is reached for this episode. So, iterating over multiple episodes our bot figures out the optimal path from any room to exit. I have not described certain methods here. So, you can find full code here.
You can grab my learnings on Reinforcement Learning @ 1/2/3/4/5
Feel free to comment and share your thoughts. Do share and clap if you ❤ it.

Reinforcement Learning — Part 6 was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.