Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
We’ve recently seen an emergence of strong artificial intelligence (AI) for difficult board games such as Go and Poker. There is yet to be a superhuman Magic: The Gathering (MTG) player, but I believe this only to be a matter of time. Once we have such a player, there will be some particularly interesting consequences.
Strong gameplaying skills will be able to guide deck-building. We should be able to sic a strong MTG player on a card pool, allow it to play thousands or millions of games against itself and “crack the meta” (build the best decks from the available cards) on its own.
Monitoring these AI players would greatly benefit the game designers and balancers. Just imagine a world where each set is more or less perfectly balanced and no bans are necessary… But, unfortunately, this technology would be beneficial for card price speculators as well.

In this article, I briefly describe the basics of game AI and consider a recent method for decision-making in MTG. I describe some experiments to test this method and discuss exciting future work. The experiments are implemented in a simple Python module, OpenMTG, which I hope will be able to serve as a basis for AI MTG players.
Magic: The Gathering in the tiniest nutshell
MTG is a game which pits at least two players against each other. The goal of the game is to win through various means, most commonly by reducing their opponents’ life total to 0. The players start the game with nothing but a stack of cards that they bring to the game, then take turns drawing and using those cards which can be of various types. For now, I will concentrate on three card types: Lands, Sorceries, and Creatures.
 Magic cards: A land, sorcery, and creature.
Magic cards: A land, sorcery, and creature.
Lands produce the currency for the players. Once a turn, you may put a land into the playing area (the battlefield) which can be used to generate mana, which can be spent on performing other actions. Those include playing Creatures or Sorceries.
Sorceries perform a single action and are then discarded. For example, reduce your opponents’ life total or destroy an opponent’s land.
Creatures are cards that enter the battlefield and are allowed to attack your opponent or block enemy attackers. An integral part of the game is the combat between creatures. Some of the hardest decisions in the game are associated with how to attack your opponent with your creatures and how you assign your creatures to block your opponent’s creatures.
Here’s a more thorough explanation of the rules if you’re still curious: https://magic.wizards.com/en/gameplay/how-to-play
A little game theory
MTG is a zero-sum game, which means that one player loses and another player wins. An algorithm for taking optimal decisions in such game is the minimax algorithm.
Using the minimax algorithm, at every state in the game, you consider every move you can take and pick the most valuable move. If a move results in you winning the game, it has the highest possible value. If it results in your loss, it has the lowest possible value.
If a move doesn’t result in the game ending, you recursively consider the next game state and the values associated with the legal moves there. Note that you generally assume that your opponents will take the action that is the best for them.
It might take a while until all possible game trajectories are explored, so it’s common to set a limit on how deep we want this search to go and construct a function that measures the promise of a game state, called a heuristic or value function. The function takes the highest value when you win, and the lowest when you lose. For other game states, it’s somewhere in between, depending on how likely you consider yourself to win or lose.
Consider a simple scenario where it is your turn and you have two eligible attackers. Your opponent has just 1 life point left and their resources are depleted (they’re tapped out), except for a single eligible blocker. Your opponent’s creature could block one attacker, but if an attacker is unblocked then it deals lethal damage to your opponent.
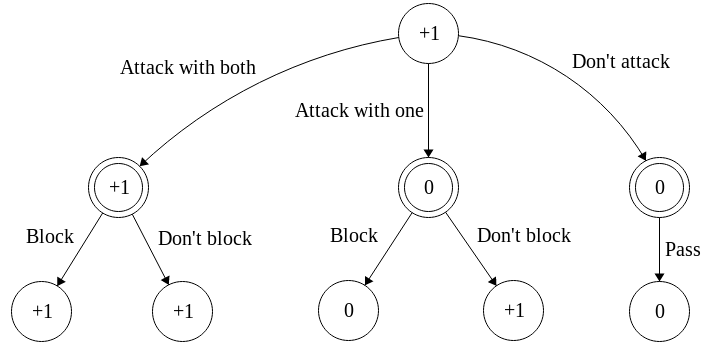 A minimax decision tree of depth 2: For this scenario, the value of winning is +1, losing -1 and states where the game isn’t over yet have a value of 0.
A minimax decision tree of depth 2: For this scenario, the value of winning is +1, losing -1 and states where the game isn’t over yet have a value of 0.
The minimax algorithm recommends attacking with both creatures, as this guarantees you victory. You could win by attacking with one creature, but you assume that your opponent does what’s best for them, so the value of attacking with one creature is the same as not attacking at all.
The problem with minimax
Even though the scenario above is at the end of a game, eight states are considered. Additionally, we already know everything that we need to know to take a fully informed decision. If we want to take a minimax decision earlier in the game, then we would have to consider all the potential hidden information. That is different cards that the opponent could be holding, all the different ways that our deck (library) could be arranged, and all the different ways that our opponent’s library could be arranged. Even knowing our opponent’s decklist, we could be in one of over a billion different game states.
This makes finding complete minimax solutions to the game physically impossible. There are methods to cut down the number of game states to be considered in minimax, for example, alpha-beta pruning. However, these methods have been shown to struggle for games where there are too many game states to consider.
Multi-armed bandits to the rescue
Since it’s a computational nightmare to evaluate every possible outcome of the game for every move you want to do, it’s better to do a probabilistic estimation. In probability theory, a multi-armed bandit problem is one where a player has several choices, each one giving a stochastic reward. The metaphor refers to slot machines, which are sometimes called one-armed bandits.
 One-Armed Bandits: The gang’s getting back together for one last heist. Photograph by Yamaguchi先生 / CC BY-SA 3.0
One-Armed Bandits: The gang’s getting back together for one last heist. Photograph by Yamaguchi先生 / CC BY-SA 3.0
{kind=link}
Each bandit has its own internal parameter of how much reward on average it gives. With perfect information about all the parameters, the player can choose to interact solely with the bandit that has the highest expected reward output. However, the only information the player gets is the stochastic rewards from their interactions. By the law of large numbers, the player will be better equipped to make an accurate estimation of how much they expect to gain from a bandit with each interaction.
Monte-Carlo Search
We will consider each potential move that we can make as a bandit in a multi-armed bandit problem. The internal reward parameter is the likelihood of us winning if we choose a move. For each legal move, we imagine how the rest of the game would go after making it. This can be done for any arbitrary number of times, giving us good estimates of the strength of each move. This is what makes a method Monte-Carlo: doing something stochastic a lot of times to get a useful aggregate result.
A good starting point to alleviate the problems above is the method described in the paper Monte Carlo Search Applied to Card Selection in Magic: The Gathering. They apply it only during the main phases, but it can be trivially used at any point in the game
The algorithm goes as follows, at each point where a decision can be made:
- Enumerate all legal moves
- For each legal move, simulate a full game after performing this move and note whether you won or lost. Such a simulation is called a rollout.
- Repeat for a large number of steps: Choose a random legal move with a favor for winning moves. Perform the chosen move and do a rollout.
- Return the move that was chosen the most often above as the best move.
- Perform the best move — in the real game.
Notes on the algorithm
Before each rollout, the unknown information (i.e. order of cards in libraries, cards in opponents hand) is randomized. This requires a good guess of the cards in your opponent’s deck.
How the games are simulated in 2. is important. For now, we will let both players perform a random action every time. I don’t believe that this is optimal but this will give us a quick prototype.
In 3., we have control over how much more likely it is to choose a good move instead of trying an apparently bad one again. This is known as exploration-exploitation trade-off: the choice between trying more alternatives to get a better feeling for which one’s the best, or “farming” the alternative that’s only seemingly the best. For me, this is essentially the same as the dilemma of deciding to have pizza for dinner again or to finally try something new.
Some Experiments
So, how well does Monte-Carlo Search perform? I implemented the basic gold and silver decks from the Eighth Edition Core Game along with the necessary game mechanics.
 Ready-to-play decks: It makes it much easier not to have to worry too much about instant-speed actions and the stack — for now!
Ready-to-play decks: It makes it much easier not to have to worry too much about instant-speed actions and the stack — for now!
Let’s allow the players, gold and silver, to play a hundred games against each other with different decision-making rules. Before each game, we flip a coin for who goes first. If we let them perform random actions, both players seem even, although gold might be slightly favored to win.
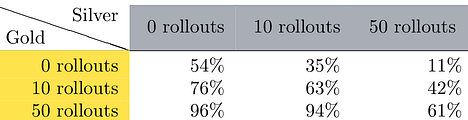 The win rates from the perspective of the gold player: In each column, we fix one search method for the Silver player and vary the number of rollouts for the Gold player— and similarly for the Gold player, per row. If there are 0 rollouts, we let the player choose any legal move at random.
The win rates from the perspective of the gold player: In each column, we fix one search method for the Silver player and vary the number of rollouts for the Gold player— and similarly for the Gold player, per row. If there are 0 rollouts, we let the player choose any legal move at random.
Notice in the table how the percentages become lower as we go from left to right and they become higher from top to bottom.
Adding the Monte-Carlo decision makes the silver player more favorable, increasingly so by adding more rollouts per move. The gold player becomes favored, however, if it is allowed to perform an equal amount of rollouts. The silver player has very little chance when it performs random actions, against the gold player with 50 or even 10 rollouts.
The results aren’t conclusive, but the experiments indicate that the gold deck is better. In any case, Monte-Carlo Search is better than acting randomly, and doing more rollouts is better.
What’s next?
This was a fun exercise in classical AI methods, but a lot more can be done! It would be ideal to have a full and open implementation of MTG — at least consisting of instant speed interaction between players, and more complicated triggers and effects. My code is available on github and I would love collaboration for bringing strong AI to MTG: https://github.com/hlynurd/open-mtg
Practically, improving the game tree search under imperfect information is necessary. In the experiments above, we allowed the players to know each other’s decklists but this is generally not the case.
Exploring different ways of combining prior knowledge to the search would make the player much stronger, without feeding them unfair information. If your opponent plays a Mountain, then you’re more likely to prepare for hostile red cards rather than cards of other colors. Depending on the format, or meta, you might want to immediately consider or dismiss certain cards before the game even begins.
The powerful Go AI, AlphaGo, used a combination of both hand-crafted or common-sense knowledge about the game state, as well as the raw game state, as inputs to a neural network. This allowed for automatic learning of a sort of heuristic function to steer their search for good moves in the game. A similar function, measuring “what’s good, when” for MTG will be important as well.
By combining all this, I imagine that a reinforcement learning approach will help us build an agent that’s excellent at deck-building, both in constructed and limited formats.
With a fully-fledged AI MTG player, it would be interesting to watch some high-profile man vs. machine matches, somewhere down the road.
Acknowledgments: My thanks to Haukur Rósinkranz for his constructive feedback on this article.
Monte-Carlo Search for Magic: The Gathering was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.