Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.

It’s no surprise how quickly Kubernetes has become a star in the land of DevOps. Kubernetes takes care of the complexity of managing numerous containers along with the changes and configuration required with groups of containers called pods, and groups of nodes called clusters. In doing so, it lets you focus on what matters most to you — the code and data at the heart of your critical applications. Because of these advantages, Kubernetes has become the headlining container orchestration tool today.
Kubernetes makes it easy to manage containers at scale, but it can come with a steep learning curve as well. This is the reason for the numerous offerings for managing Kubernetes services such as Platform9, Kismatic, OpenShift, and CoreOS Tectonic (now part of Redhat) to name a few.
No matter which route you take to managing your Kubernetes cluster, one fundamental requirement is effective log analysis when things go upside down. Traditional application infrastructure utilized log data to troubleshoot performance issues, system failures, bugs, and attacks on a server by server basis. Modern infrastructure like Kubernetes exponentially increases the number of virtual systems(containers) where logs need to be aggregated and tagged for effective analysis.
Disclaimer
This article summarizes the insights and thoughts while building our Kubernetes support for LogDNA. It was important to create a great experience for our customers but also needed it selfishly as we moved the majority of our own services onto Kubernetes. We specialize in building a beautiful logging platform that magically handles log collection, parsing, indexing, tagging, searching, analysis, alerting, and storage across all of your systems.
The Importance of Log Data in Kubernetes
Log data is essential to Kubernetes management. Kubernetes is a very dynamic platform with multitudes of changes happening all the time. As containers are started and stopped, IP addresses and loads change — Kubernetes makes changes to ensure services are scaled correctly and performance is not impacted. Inevitably when things break, or performance slows down, you need the detail that only log data can provide. In the Kubernetes world, containers are constantly being deployed/terminated and it’s entirely possible that the containers generating logs for what you’re looking for may already be terminated by the time you investigate. The only way to trace back is to ensure the logs are available so you can trace back your steps to paint a picture of what happened. Outside of performance and troubleshooting, industries that require compliance will also need log data to ensure you’re meeting the needs of HIPAA or PCI DSS like requirements. In the egregious scenarios of a data breach, you’ll need to go back in time to identify the origin of the attack and its progression across your system. For all these use cases, log data is indispensable.
There are many ways you can access and analyze Kubernetes log data ranging from simple to advanced. Let’s start with the simplest option and move up the chain.
Logging within a Pod
Containers are the lowest level element in Kubernetes, but Pod-level logging is the most basic form of viewing Kubernetes logs. Kubectl commands are used to fetch log data for each pod individually. These logs are stored in the pod and when the pod dies, the logs die with them. They are useful and effective when you have just a few pods. You can instantly check the health of pods without needing a robust logging setup for a big cluster.
Logging within a Node
Logs collected for each node are stored in a JSON file. This file can get really large, and to deal with that situation, you can use the logrotate function to split the log data in multiple files once a day, or when the data reaches a particular size quota. Node-level logs are more persistent than pod-level ones. Even if a pod is restarted, it’s previous logs are retained in a node. But if a pod is evicted from a node, its log data is deleted.
While pod-level and node-level logging are important concepts in Kubernetes, they aren’t meant to be real logging solutions. Rather, they act as a building block for the real solution, cluster-level logging.
Logging the entire Cluster
Kubernetes doesn’t provide a default logging mechanism for the entire cluster, but leaves this up to the user and third-party tools to figure out. One approach is to build on the node-level logging. This way, you can assign an agent to log every node and combine their output.
The default option is Stackdriver which uses a Fluentd agent and writes log output to a local file. However, you can also set it to send the same data to Google Cloud. From here you can use Google Cloud’s CLI to query the log data. This, however, is not the most powerful way to analyze your log data and can be a pain if you’re not already using GCP. Which leads us into discussing potential solutions that are out there today.
DIY Kubernetes Logging with Elasticsearch
One of the more popular ways to implement cluster-level logging is to use a Fluentd agent to collect logs from the nodes, and pass them onto an external Elasticsearch cluster. The log data is stored and processed using Elasticsearch, and can be visualized using a tool like Kibana. The ELK stack (Elasticsearch, Logstash, Kibana) or here we’re referring to an EFK (Elasticsearch, Fluentd, Kibana) is the most popular open source solution for logging today, and its components often form the base for many other modern search solutions. The ELK stack offers powerful logging, and more extensibility than the Stackdriver / Google Cloud option. While building your ELK stack isn’t difficult initially, configuring Logstash or Fluentd for every input source can be a handful and furthermore scaling your own ELK stack for the amount of log data you’ll soon be getting may end up requiring more time and effort than you think.
Collecting logs using a Sidecar Container
Another popular method of collecting logs is by deploying collector as a sidecar container within each pod to pull logs on a pod level. Every sidecar container contains an agent for collecting and transporting logs to a destination. Most sidecar container implementations are lightweight but requires additional resource for every pod within your node/cluster. For large scale applications, that means you’re required to configure every podspec which can be cumbersome and not a great practice at scale.
Collecting logs using a DaemonSet
The most effective log collection method we found was to simply deploy a collector as a DaemonSet. This deploys a resource on a node level versus the pod level, and maintains the the same capabilities of a sidecar implementation without requiring the need for an additional process/container deployed for each pod. Deploying as a DaemonSet also inherently allows you to automate the deployment across your entire cluster with a very minimal set of kubectl commands. Set it and forget it!
Rich contextual Log metadata
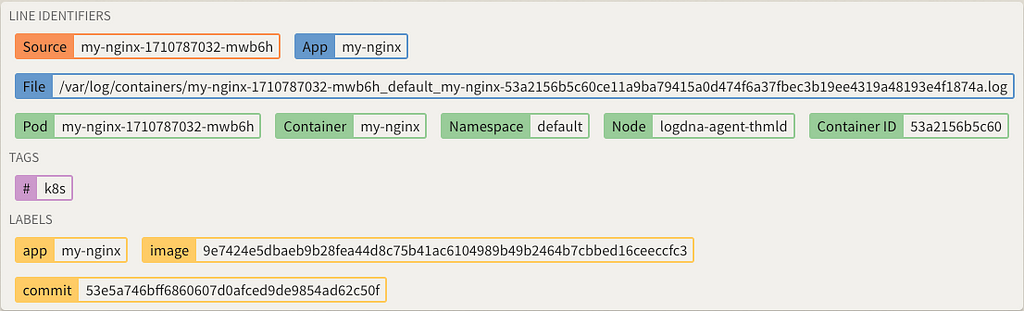 Screenshot of Kubernetes logs metadata captured in Ldropdown (Nginx running Kubernetes).
Screenshot of Kubernetes logs metadata captured in Ldropdown (Nginx running Kubernetes).
While collecting the logs to a searchable and centralized data store may the most important functional concept, logs are useless if you can’t find what you’re looking for. The most beautiful aspect of logging in Kubernetes is the framework and organization that a single orchestration system brings. Kubernetes stores logs in a way that provides rich contextual information for a logging solution to automatically tag each log with rich metadata. Information such as which node, pod, containers and even labels can be attached to the logs to make log analysis and aggregation much easier when you need. A proper logging solution should take advantage and allow interesting use cases directly labeling commit hashes to specific containers and filtering and searching logs against that label.
TLDR; & Summary
Kubernetes is the leading container orchestration platform available today. Yet, running a production cluster of Kubernetes takes a lot of familiarity with the system and robust tooling. Kubernetes presents a new scale of complexity when it comes to application logs and when it comes to log analysis, Kubernetes offers basic log collection for pods, nodes, and clusters, but for a production cluster you want unified logging at the cluster level. Building and designing a solution which can take advantage of the strengths of Kubernetes can ultimately be more elegant and scalable than keeping track of applications and servers in more traditional deployments.
Building your own ELK or EFK stack is a common way to access and manage Kubernetes logs, but it can be quite complex with the number of tools to setup and maintain. Ideally, you want your logging tool to get out of the way and let you focus on your log data and your Kubernetes cluster.
A deeply customized logging solution for Kubernetes should automatically recognize all metadata for your Kubernetes cluster including pods, nodes, containers, and namespaces. It lets you analyze your Kubernetes cluster in real-time, and provides powerful natural language search, filters, parsing, shortcuts, and alerts.
Learn more about LogDNA for Kubernetes here.
Nodes and pods and containers oh my…(The fundamentals of K8’s logging) was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.