Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
As this Cambridge Analytica fracas unraveled, my first reaction was HOLY-EFFING-SH*T! People on social media were losing their mind over the enormity of the data loot. Even my tech-leaning acquaintances were at-least mildly impressed that that data belonging to as many as 30 to 50 million Facebook users was siphoned off legally in the guise of academic research and fed into sinister statistical pipelines drenched in malaise to wreck political mischief, put mildly.
Now, here comes the plot-twist. This was a whole different kind of a HOLY-EFFING-SH*T moment for me. As someone whose PhD thesis was literally in the field of Network Science, I knew for a fact that 50 million was puny small. Academics who worked on the big data facet of the field had routinely amassed and touted far bigger numbers in their publications during my doctoral studies.
Given the inherently romantic nature of the field, I still devote some of my Sundays towards keeping myself abreast of the exciting developments in the field. One such rather impressive paper I recall having read early this year (published in Dec 2017) came to my mind when I saw the Channel 4 news expose. This paper had bragged about figures that will make all those worried about the enormity of the Cambridge Analytica breach dive deep into depression.
Are you ready for the number? Are ya sure?
OK, here it goes:
368 MILLION USERS.
In a paper smartly titled ‘Do We Really Need to Catch Them All? A New User-Guided Social Media Crawling Method’, a Swedish-Polish team of merely 4 researchers from 2 humble schools ( Blekinge Institute of Technology and Wrocław University of Science and Technology) had amassed a dataset of 368 million unique users interacting in little over 1.3 billion social interactions!
 The abstract of the paper
The abstract of the paper
But how did a team of 4 pull this off? Combination of 2 ideas:
a) Smart ‘attack/seed points’: Facebook pages.
b) A nifty crawling engine.
The team had built this rather impressive crawler — SINCE- Social Interaction Network Crawling Engine that they used to collect publicly available Facebook data. Now, which 160 pages you ask? It’s all openly available neatly curated and hosted on Harvard’s dataverse.
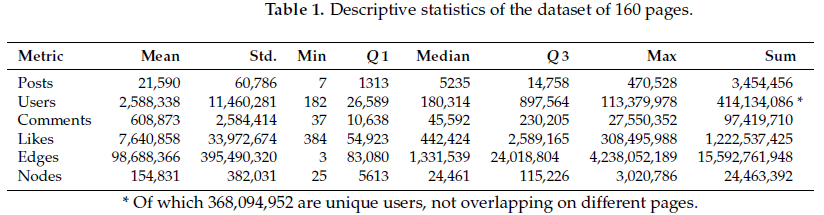
The numbers on their descriptive stats table is strictly orgasmic. Take a look.
Now, what if a reader/journalist wants to give this a shot? Sans sinister intentions, purely for intellectual curiosity?

Can’t code? No worries. GUI tools to the rescue! If you can spare $75, you can get access to tools like the one above that will allow you to indirectly target users based on one rather interesting backdoor: Facebook fan pages!
Example:
Now, bear in mind that this is not an expose or a witch-hunt against the authors of the fine paper above or their excellent piece of engineering research. For what it’s worth, the authors do vividly state that ‘We adhere to Facebook’s data privacy policy by anonymizing all data to an extent where it is only possible to backtrack the particular public page that is analyzed’, and I for one do take their word for that. This work is from mainstream reputed academics.
The main point here is that if you are considering state-of-the-art publications in areas such as Graph exploration or even recommendation engines, data belonging to a user-set spanning a few hundred million users is par for the course.
Proof?
This:

So, now what? Does Facebook go through the entire list of academics who were given academic access one by one and flies one their Data engineer and a lawyer to make sure that the data is strongly anonymized?
This where I squirm a little. Online social networks by their volition are tricky beasts to anonymize. This is not an unfounded fear. During my Ph.D, I knew of researchers who were actively working on de-anonymization strategies and had met with plenty of successes. Example:

Also, believe it or not, we have been here before! In my first year at CMU, I had read Mike Zimmer’s paper on Facebook’s infamous breach of 2008.

Because we millennials co-exist co-temporally on several social media platforms and carry forward our social allegiances elsewhere, all it takes is one or a few Harvard freshman from Wyoming breaches (See figure below) and we will face cataclysmic ripple effect breakdown of anonymity.

So, perhaps, the only solution is forced deletion from every single academic repository that there is out there?
Possibly so.
‘Academic’ honeypot datasets with 368 million users. Why is nobody talking about these!? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.