Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
The secret to deliver at full throttle is not about your tools By Nathaniel Tetteh on Unsplash. This is how you achieve Continuous Integration.
By Nathaniel Tetteh on Unsplash. This is how you achieve Continuous Integration.
By Nathaniel Tetteh on Unsplash. This is how you achieve Continuous Integration.
I’m in the Software Development business since many years now. Living in Berlin also helps me staying in touch with a huge startup community.
I like to talk to people from different companies to see how their processes look like and what’s their culture regarding teams, coding practices and quality standards.
When it comes to discuss about Continuous Integration, there is a pattern I notice more often than not. It’s not uncommon that developers talk about it as if it is only about Jenkins, or Travis, or whatever tool they use.
Apparently, in many environments Continuous Integration simply means having a tool that checks your latest commit and turns red or green like an Xmas tree depending on the tests result.
I don’t agree.
There are fundamental practices and processes that comes before any tool you could use and that constitute the very basis of Continuous Integration.
Without those, CI is simply not possible.
In this post I list some of them. I think they are a good starting point for achieving true Continuous Integration.
If you are in a team that struggles to deliver, or you can’t manage to coordinate your coding efforts with the ones of your team peers, then this post is for you.
No feature branches
When teams are confronted with the task of developing a new feature, a common mistake they make is to open a feature branch in their repository and start throwing many commits inside it.
The idea is to isolate themselves from the project-wide development process constraints until the feature is finished and can be merged back into master.
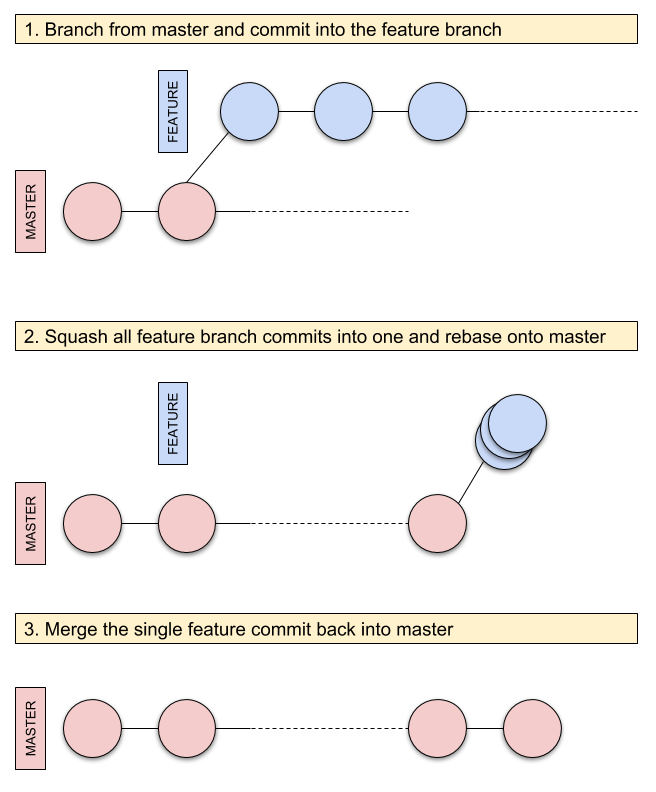 Representation of the Feature Branch git workflow
Representation of the Feature Branch git workflow
The thought behind this practice is more or less “if we directly work on master, and master is connected to the release cycle, we’ll release a half-backed feature or something that doesn’t work yet. Even worse, we could break something because we haven’t fully tested our code”.
While this practice may sound conservative and safety-oriented, it’s totally the opposite.
More often than not, you end up with a broken release right after you merge back your feature branch. Your only options at this point are a) revert the commit or b) hot-fix the release.
If you are unlucky, both of them can be expensive and error-prone.
If your release process is not sufficiently automated, reverting such a big commit may cost you a manual rollback of your database structure, for example. And what will you do if you destructively altered your data?
Hot-fixing is not less risky either. To minimize the user experience disruption, you need to release a patch as soon as possible. And we all know that time pressure doesn’t get along at all with well-thought-of development. The risk is to add bugs on top of bugs and worsen the situation beyond an acceptable limit.
Why feature branches don’t work
The reason why feature branches don’t work is simple: you don’t get continuous feedback while developing.
When you and your team don’t give to your stakeholder the possibility to continuously validate your work in progress, you lose contact with reality.
There’s no way for you to validate your development progress other than letting your user continuously check in.
There’s a big fallacy many developers fall for in this case. It’s the belief that if they test their code enough, either by writing tests or manually clicking around, they can be confident that what they just developed will just work™.
This is a mistake, and must be avoided at all costs.
As far as you, as a developer, can try to think like your user(s), you’re simply not. Usage patterns will be overlooked and not implemented. Behaviors won’t be foreseen, opening the door to sneaky bugs. Business cases or deep processes won’t be uncovered.
In other words, your software won’t implement what the reality is, at best. Or it will be plain broken and won’t simply work, at worst. In both cases, it will look wrong in the eyes of the user.
While the Feature Branch model may sound conservative and safety-oriented, it’s totally the opposite.
Use feature toggles
The first, easy step to achieve a good level of CI is to use feature toggles.
A feature toggle is a configuration flag in your application that can turn on and off a particular feature.
This technique is insanely easy to implement. In your codebase, it looks more or less like this.
The advantages of using a feature toggle are the following:
- you can turn a feature off in production without having to release again. This is useful when a critical bug is reported and you want to prevent users from accessing the broken feature;
- you can enable the feature in a canary environment and let it off in production. This allows early stage users to test the feature and the development team to collect useful feedback before an official release;
- you can enable the feature in a closed environment and allow, for example, a Product Manager to check the state of the art even if the feature is not complete yet.
There’s one more advantage that is unlocked when you start using feature toggles.
Since your feature can be turned off in production until it’s completed and stable, you can now start merging commits directly into your master branch.
Small commits, directly to master
There are a couple of valid reasons to merge your commits directly into master following this model.
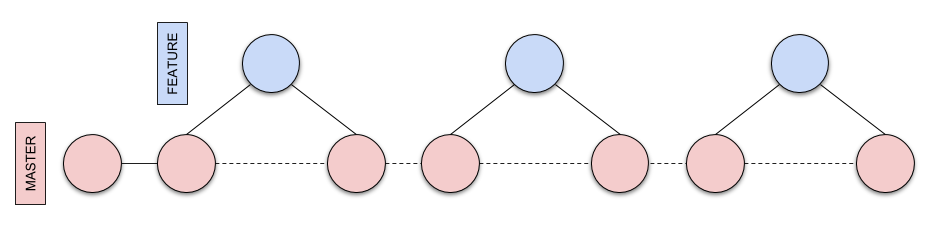 The “Jumping Fish” merging model.Who did this?
The “Jumping Fish” merging model.Who did this?
The first reason is that you get a cleaner history of your code. You exactly know who did what. This helps a lot when other developers need clarifications on a specific portion of the code.
With feature branches, all commits are squashed into a single one before merging, so the information is lost and only one developer will take all the (git) blame.
Easy merges, fewer conflicts, safer reverts
The bigger a feature branch, the higher the possibility that you’ll have merge conflicts.
Merge conflicts can be very painful since solving them is a purely manual and extremely error-prone process.
On top of that, when facing a merge conflict, you probably have to rework a bit your application logic. This is typically done on the fly while rebasing. I let you imagine what could be the qualitative outcome of coding while your brain is in the middle of another task.
I saw many times developers saying “Don’t know what happened. I solved some conflicts and git messed up during the rebase”. Maybe git has some bugs, but I highly doubt it can mess up during a rebase.
Smaller commits allow you to be on the safe side and avoid complicated rebases. Conflicts are minimal and trivial because the surface extension of the change is too.
Smaller commits are also easier to revert because of a psychological factor. When working with big feature branches, your sunk cost bias fights against your rational judgment. You are reluctant or even afraid to revert such an amount of code.
“Better to try and fix it. The fix will be minimal compared to the amount of code. There’s no need to revert everything after all the work we did” — Do these words sound familiar to you?
Eventually, small commits should be small enough for one team member to merge something into master at least once per day.
Optimize for parallel development
This is where Software Design really meets Continuous Integration.
Even working on isolated feature branches, team members can block each other if they don’t split the development of a feature carefully enough.
It’s ironic that we design our software to be decoupled and our modules to be independent from each other, while the engineering of our development process leaves much to be desired.
This is what a typical time distribution of development tasks for a single feature looks like.
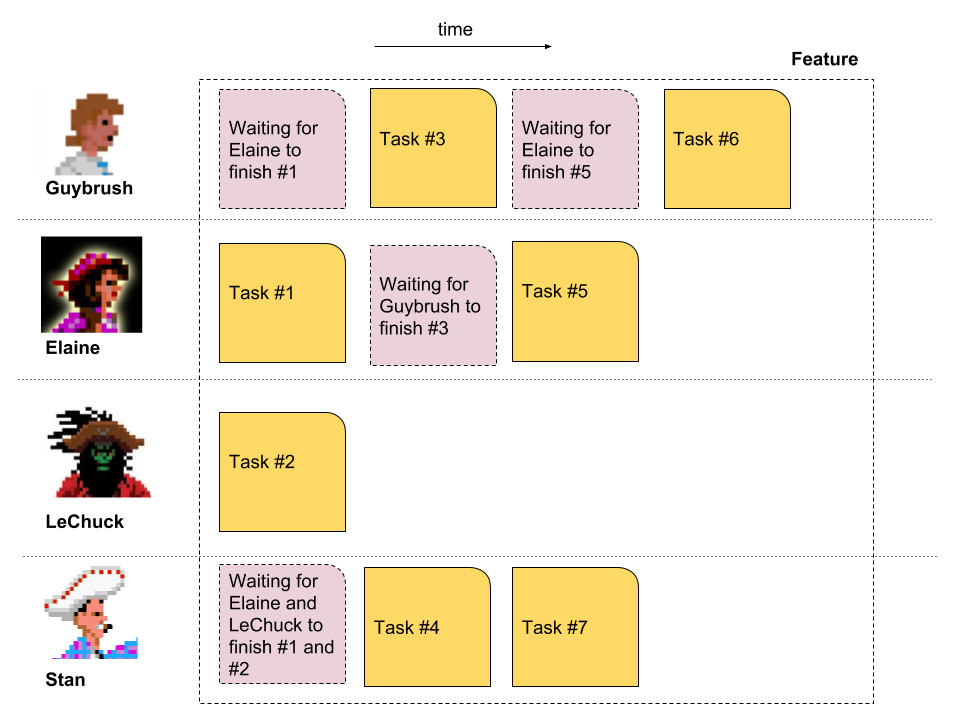
Guybrush always needs to wait for Elaine to finish her task otherwise he can’t start working on his. Stan is stuck until LeChuck and Elaine deliver their parts and LeChuck is eventually left with one task only.
Unfortunately there’s no silver bullet to tackle the development of a feature so that every team member can work on some task in parallel.
What definitely helps here is to look at the feature from a Software Design point of view and try to understand where are the cut lines. I’m basically talking about looking for interfaces before start developing common areas.
A useful heuristic, for example, is that if two developers need to work on two adjacent areas, let’s say a frontend component and its backend counterpart, they can agree upfront on the interface they are going to use for putting the two parts in communication.
Another team could instead apply the “who arrives first decides the interface rule”, where two or more developers start working independently and the first one who arrives at the definition of a point of contact will specify it.
Things can still be changed when others arrive there and see that the definition doesn’t perfectly fit their use case. But at least no one is blocked in the meantime and the need for improving the interface will most likely spark a healthy conversation among team members as well as interesting insights in the design of the feature.
Conclusion
Continuous Integration is not about your tool.
Continuous Integration is about how you engineer your development process.
It takes time and effort to make it work smoothly.
This involves understanding and applying different synchronization strategies among not only team members, but every person involved in the development of a feature.
Having your commit checked against a test automation pipeline is merely the cherry on the top.
Ready to become a better developer?
I’ve created a developer toolkit for you. Download it for free and start learning how to write code you will be proud of. If you constantly apply those techniques, you’ll become a top software developer.
Get the free developer toolkit here!
If you enjoyed this post, please click the 👏 button and share to help others find it! Feel free to leave a comment below.You can also subscribe to my Software Development newsletter here: http://eepurl.com/dfQQaz
How to Get Continuous Integration Right was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.