Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
On my first on-site interview for a full stack software engineering position, I was asked to write a function that would detect if there was a cycle in a directed graph.
Reader: I did not successfully write that function.
To be perfectly honest, I had a hazy-at-best idea of what a graph even was. For most of my life, I thought a graph was this:
 Source: http://bit.ly/2HFsh9w
Source: http://bit.ly/2HFsh9w
Turns out, a graph is actually this:
 Source: http://bit.ly/1OCkA1r
Source: http://bit.ly/1OCkA1r
I know, I think the first one looks more fun too. But the graph is actually an extremely cool data structure. They’re ubiquitous in computer science, used in recommendation engines and Google Maps and, of course, GraphQL. The thing is, there’s not many articles detailing implementation of/tricks with graphs in Javascript. So I decided to write one.
So what is a graph, really?
The most basic thing to know about graphs is that they’re composed of vertices and edges. Vertices are the things of the graph: an integer, an object, a website, etc. Edges connect a pair of vertices.
Graphs can be:
- Weighted or unweighted — this refers to whether or not the edges of a graph are labeled with values. If they are, it’s weighted.
- Directed or undirected — this refers to whether the edge behaves like a bridge (undirected) or a bowling lane (directed).
- Cyclic or Acyclic — this refers to whether or not a cycle exists in a graph.
There are two main ways to represent a graph: with an Adjacency List, which is a collection of arrays (or objects, if you’d like) associated with each node:
{a: [b,c,d],b: [c,f],d: [e],e: [a,f],f: [a, c, d, e]}or with an Adjacency Matrix, which is a two-dimensional array where edges between vertices are represented with a 1:
[ [0, 1, 0, 0, 0, 0, 1, 0, 1, 0], [1, 0, 0, 0, 1, 0, 1, 0, 0, 1], [0, 0, 0, 0, 1, 0, 1, 0, 0, 0], [0, 0, 0, 0, 1, 1, 0, 0, 1, 0], [0, 1, 1, 1, 0, 1, 0, 0, 0, 1], [0, 0, 0, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 0], [0, 1, 0, 0, 1, 0, 0, 1, 0, 0] ]
There are pros and cons to each representation . Generally speaking, graphs with lots of edges fare better as matrices and graphs with fewer edges fare better as lists. Adjacency lists tend to be more common, and its what we’ll use today.
Making a Graph
So let’s get making! Woo. The first thing we’re going to want to do is…make a graph.
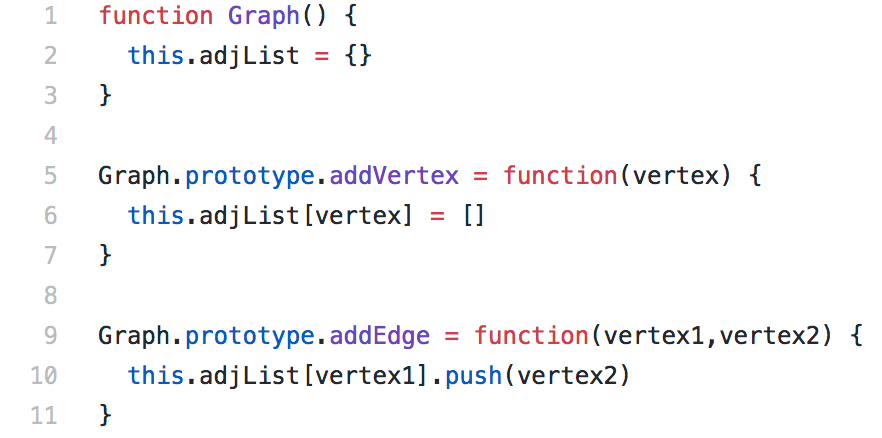
The logic inside the Graph constructor is simple: just an adjacency list instantiated as an object literal. The two methods that follow aren’t much more complicated: a method for adding vertices that initializes each vertex as an empty array, and a method for adding edges that pushes a vertex into another vertex’s array. So something like this…

Makes a graph that looks like this:

Or put another way:
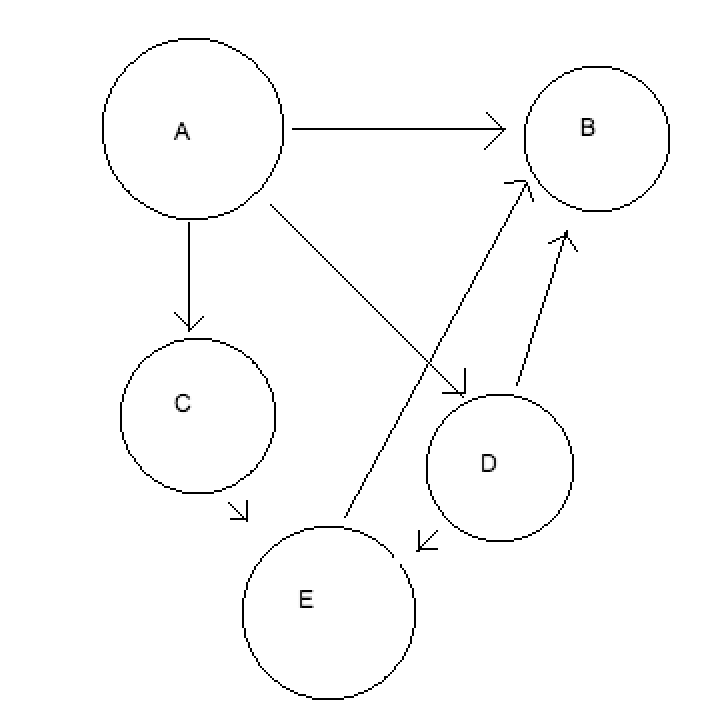 RIP Microsoft Paint
RIP Microsoft Paint
And now we have a graph! Yay. And not just any graph: an unweighted, directed, acyclic graph.
Traversing a Graph
Now that we have a graph, we’re going to need to figure out a way to visit the different vertices — our ultimate goal, after all, is to detect if the graph is cyclical, and that means traversing from vertex to vertex along the graph’s edges.
There are two ways to traverse a graph: a breadth-first traversal, where each child of a vertex is visited before any of that child’s children is visited, and depth-first traversal, where we follow a sequence of vertices connected by edges until we can’t any more before continuing to the original vertex’s next child. Our algorithm for detecting a cycle in a directed graph is going to use a modified version of a depth-first traversal, so let’s take a quick look at what that traversal method looks like.

We have two functions here: a dfs function, and a _dfsUtil function.
The dfs function only does three things:
- Creates an array called “nodes”; every element is a vertex in our graph
- Creates an object literal called “visited”
- Calls our utility function on each vertex in the graph.
The important thing to remember when we’re executing a depth-first traversal of a graph, as opposed to a binary tree (for example), is that we need to keep track of the nodes we already visited and not visit them a second time, even if another vertex has an edge to that node. For example, if we weren’t keeping track of vertex we visited, than traversing our graph from the starting point ‘A’ would lead us to visiting ‘B’ four times, instead of just once! 🙅🙅🙅
A -> BA -> D -> BA -> D -> E -> BA -> C -> E -> B
That’s why we pass our visited array as to our utility function as a parameter. The utility function is where we visit a vertex, mark it as visited, get its edges , check if a given edge has already been visited and, if it hasn’t, recursively call our utility function with that vertex as the new starting point and the updated ‘visited’ array.
But…cycle detection?
Right! Detecting cycles. How do we modify our depth-first search functionality to determine whether our graph is cyclic or acyclic?
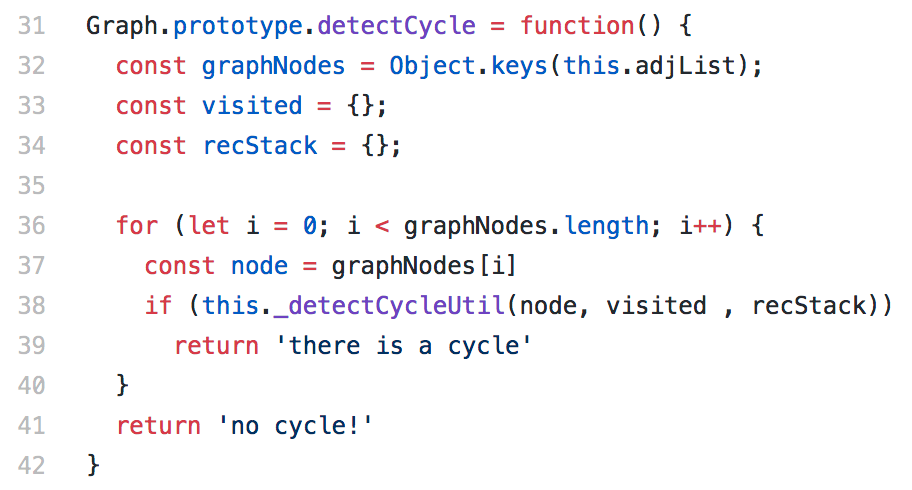
As before, we’re going to call the cycle-detecting utility function for every vertex in the graph. We can only be certain the graph is acyclic if that utility function never returns true. But we’re also going to create an object literal called ‘recStack’.
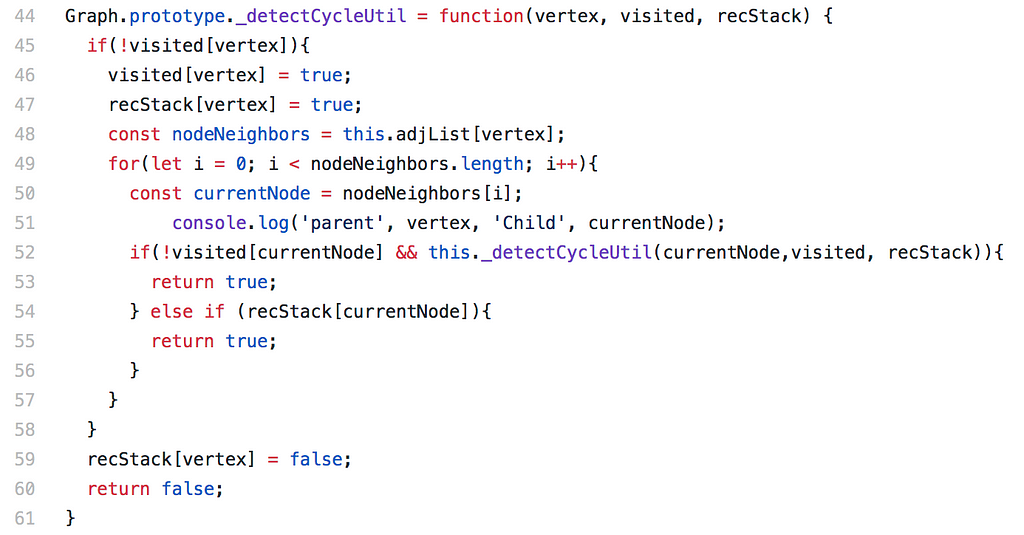
We’re doing several things here:
- On line 45, we’re checking to make sure that we haven’t already visited this node. If we have, there’s no need to check it again.
- On line 46 and 47, we’re making the vertex as true in the visited stack and our recStack. In this new utility function, recStack stands for ‘recursion stack’, and it’s what’s keeping track of the back edges, the vertices we visited to get us to our current vertex.
- Same as before, we’re going to get the neighbors of our current vertex and traversing them. This time, however, we’re not just checking to see if we’ve visited them or not — we’re checking to see if a particular edge is in our recStack, which would mean that we’ve already visited it. That’s our indicator that we’ve found a cycle.
- If the vertex isn’t in our recStack, than we pop it off the recursion stack (line 59) so we won’t get a false positive as we traverse another path through the graph.
And hey presto: that’s our function for detecting if there’s a cycle in a graph.
Graphs aren’t covered much in most intro-to-computer-science resources I’ve looked at, which is a real shame. They’re really cool, all over the discipline, and weirdly prevalent in interviews for entry-level software development positions (or have been in my experience, at least). So, to my fellow (aspiring) junior developers: learn you some graphs before you go into that next interview. You never know.
Here’s the repl: https://repl.it/@samisthesam/Cycle-detection-in-a-directed-graph
A thanks to Sulamita Morales for consultation and moral support
The Javascript Developer’s Guide to Graphs and Detecting Cycles in Them was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.