Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
How do you write bad code that’s hard to test?
There are few anti-patterns for untestable code that you should avoid writing. These are:
- Code with a lot of conditional behavior which depends on another un-readable code.
- Code that gives you different results based on the order in which it is executed with respect to other code.
- Different codes responsible for setting the same (global) variable
- Code that depends on a long chain of separate evaluations and assignments.
I once had the displeasure (or pleasure because it taught me how bad bad code can be) of trying to prove the correctness of code that incorporated all those anti-patterns. It was written in C++ for a particular embedded systems application that I’m not going to get into. But I recreated the gist of what the code does in JavaScript as shown below:
Bad, Unwieldy Code
Let’s first understand what this code is trying to do.
The valIncrementer function takes an argument called val and return val+1, but with a few caveats:
- If val is a number between 0 and 10, then the function returns val+1.
- If val is outside the range of 0 and 10, then the function will return 0 if val is less than 0 or 10 if val is greater than 10.
- If the disabled flag is set, then the the function just returns the val without changing it.
Not only is the above code difficult to read, it is also difficult to test. To prove the correctness of the code, you have to run a set of tests to see what the valIncrementer function gives you for different inputs. At a minimum, we need to test when val is a number between the valid range (i.e., 0 and 10), and the edge cases when it’s less than 0, when it’s equal to 0, when it’s equal to 10, and when it’s greater than 10.
res equals the following:
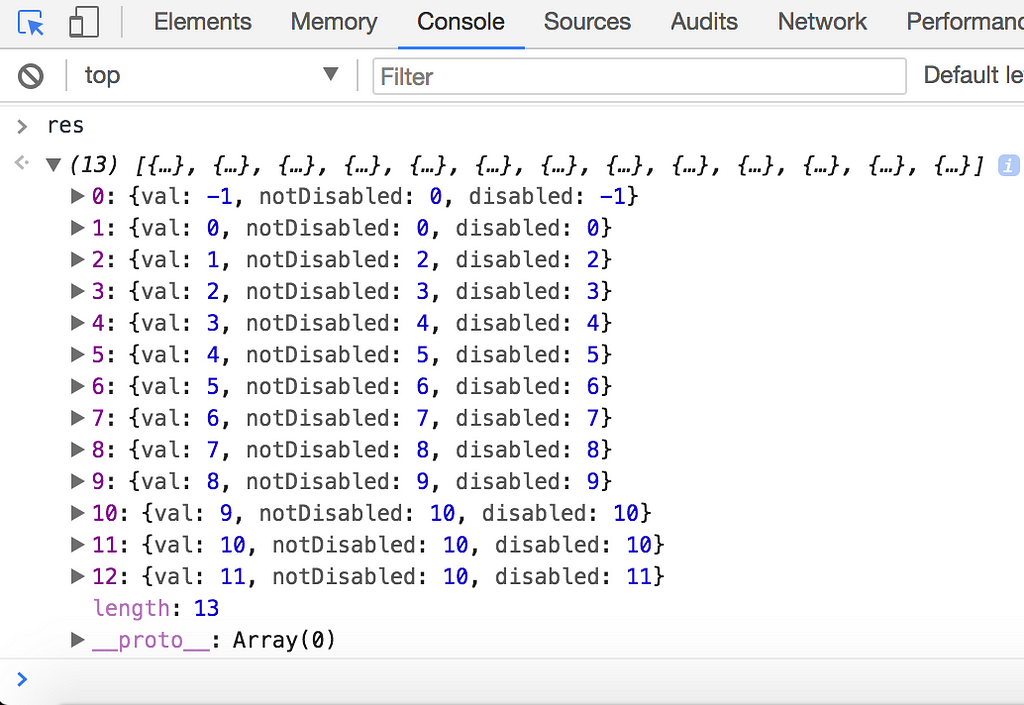
The bad, unwieldy code gives us the right answer, but it’s not possible to unit test the different portions of the code that handles one aspect of the overall logic. For instance, how would you test whether val gets incremented when you want it to be incremented? Well, nextVal is assigned to be val+1 in the beginning, but it’s not guaranteed to stay that way. You’d have to step through firstStageSetter1, firstStageSetter2, and secondStageSetter to make sure nextVal doesn’t get reassigned to something else.
Better, More Testable Code
This is how I would rewrite the bad, unwieldy code to improve maintainability and testability of the code.
Notice how much shorter my rewritten code is compared to the bad, unwieldy code. There are two guiding principles for my refactoring:
- Pure functions: When a function is pure, it does not use anything that’s not given as arguments to compute (no global state) nor does it modify anything it is given. The pure function always just give back a new copy (no mutation). A good way to think about pure functions is If I give this input to a function, will I always get the same output no matter what? If the answer is no, then its probably not a pure function.
- Decoupled Design: Before you start coding, think about how to break down what you have to do into a set of simple building blocks that each does one very simple thing. My better valIncrementer delegates various aspects of its responsibility to helper functions. It separated the what I should do code from the doing it code, which can be separately unit tested.
Each helper function is responsible for a simple task and can be very short. It only cares about its own arguments and is insulated from the effect of whatever is happening outside of it. valIncrementer’s only responsibility is to tie all these functions together with one if-statement.
Why did I make incrementedVal a separate function? I don’t have to for a simple function like that. However, suppose this is not as simple as just incrementing a number. Suppose this operation requires accessing the database and can have latency and other side effects. We want to segregate code that’s not deterministic from code that is deterministic.
Why do people write unwieldy, untestable code?
I can see two reasons for this:
- Technical Debt: Most people don’t plan to write bad code. It just happens as more functionality is added over time. It’s often not feasible to refactor your code after a change, especially when your code is an API and your code rewrite could break your users code.
- Bad Culture: Sometimes there are also management pressure and schedule/fiscal constraints to minimize change to other parts of code that “works” (the don’t fix what’s not broken argument, among many other common excuses). This article points out:
As it turned out, more flexibility led to devs writing code that others actually struggled to understand. It would be tough to decide if one should feel ashamed for not being smart enough to grasp the logic, or annoyed at the unnecessary complexity. On the flip side, on a few occasions one would feel “special” for understanding and applying concepts that would be hard for others. Having this smartness disparity between devs is really bad for team dynamics, and complexity leads invariably to this.
If you are already in that situation, then recognize that you are adding to the technical debt when you continue to neglect code refactoring and code rewrite and there’s a point in which the cost/time of making changes to it and making sure it still works outweighs the benefit of not refactoring. There are resources out there that helps you recognize symptoms that your code is untestable and suggestions for how to refactor. It’s likely many others are also struggling with the same problem you have so there’s opportunity to be creative and collaborate with other developers in the same ecosystem on an open source solution.
If you are just starting on a project, here are some guidelines:
- make sure to design your code well to account for future revisions. This means make code maintainability and testability a design goal and design your code with the expectation that your code will have to change a lot to add more capability in the future.
- Be careful with design patterns such as object oriented programming. While object oriented programming forces designers to go through an extensive planning phase, making baseline designs with less flaws, it has been under a lot of fire lately for its “highly structured physical environments in which after-the-fact changes are prohibitively costly, if not impossible”. The problems with objected programming are summed up nicely by Joe Armstrong in Coders at Work by Peter Siebel: “The problem with object-oriented languages is they’ve got all this implicit environment that they carry around with them. You wanted a banana but what you got was a gorilla holding the banana and the entire jungle.”
- Try to avoid complex dependency injections. Dependency injection is a technique for decoupling the client of a service from the service’s implementation by allowing a client to configure its use of the service at compile time. In practice, complex dependency injection means many things need to be specified in the constructor before the service can be fully configured for a client. The more complex the dependency injection, the more tightly coupled the behavior is to the environment, making a standalone test of the service’s implementation more difficult. If your dependency injection gets too complex, you can always split up a big, complicated service into smaller, simpler services with their own dependency injections.
 Derick Bailey’s BlogSelf Study Material
Derick Bailey’s BlogSelf Study Material
Here’re some follow up reading for those interested in learning more on this topic:
- Two Pillars of JavaScript Part 1: “How to Escape the 7th Circle of Hell”
- The Two Pillars of JavaScript Part 2: Functional Programming (How to Stop Micromanaging Everything)
- A Functional Alternative To Dependency Injection in C++
- Object Oriented Programming and Dependency Injection
- Object Oriented Programming is an expensive disaster which must end
- Goodbye Object Oriented Programming
- Unit Tests, How to Write Testable Code and Why it Matters
- A Response To Why Most Unit Testing is A Waste
- Mishko’s Guide: To Writing Testable Code (Also in PDF Version)
- Best Programming Languages For Each Situation
Thanks for reading!
How to refactor code to be more testable was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.