Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
Estimating a complex IT Project is at best are a form of Art. But often, calling it a Dark Art is the better way of describing it: you need magical powers to get it right and one of the two parties (supplier and client) might take advantage of the other side.
In moments of confusion, it can be useful to compare what we as humans do with artificial models. For example, Neural Networks were invented with the idea to understand the human brain. I will follow a similar approach to examine our complex world through simpler theoretical glasses: the 2nd part of this 1st blog we will compare project estimates to how Neural Networks predict the future
The 2nd part will draw some conclusions from Bitcoins method of achieving trust in a network of interactors for our work in projects and suggest, how to cooperate without banking on magic crystal bowl.
Now, let us summarize, how we estimate projects and try to deal with uncertainty. .
An Inconvenient Truth
Art is an intuitive process, mastered by few individuals who are not necessarily able to explain how they come to their conclusions. In other words, art is great but it is absolutely not what you want to base your IT project and with it a billion euro Service Industry on. But actually we do just that: Even estimating a 2 weeks sprint is hard to do, estimating a complex multiple month or year project in fact is beyond our current skill set. If we get the estimates ‘right’, often they are correct for the wrong reasons (one part was over- another part underestimated) or they are correct in the way a broken clock is correct twice a day.
The crux is: Project estimates are (?) inevitable. Some Client department has to request some budget and some System Integrator has to get paid something. We just need to plan and how would you do that without calculating the effort. In fact, there are companies and individuals who just get project estimates better than others. So, there must be some way to get it right.
How we estimate Projects
Take a typical IT Consultant or Sales Person. A Client asks her / him to deliver a Solution, there are license costs, there is a one time cost to setup and customize the software and there will be ongoing operational costs. One client department needs the functionality and has an internal procurement department that needs a number to decide, if the purchase can go through. You don’t want to jeopardize your deal and actually you think you gonna do something useful for your client. So, you have to come up with a number. The license costs are a piece of cake, crystal clear, you ignore the operational costs for now. But you have trouble deciding how much it will cost to get the software up and running for the requirements the Client has. Because no one, certainly you do not, for sure what the Client wants and how the requirements will evolve. For any medium complex project it is a triviality that a Client cannot know precisely upfront what (s)he will need, yet you are asked to come up with a ‘rough estimate’.
So, you need a number that allows the project to get delivered, yourself to make your margin and very important: you don’t want to get in trouble: No ‘bleeding’ project, no financial loss, no stop of the project before ‘go live’. If you are like me, you would like to take low risk on your delivery and learn much more about what your client needs and want.
You need to tackle that, when you estimate your project. But frankly, you do not have so many options:
- Bottom Up: you try to identify the bits and pieces of Technology you will need to implement. For example an interface, database tables, User Interfaces, Workflows and batch jobs. You assign a number to them, maybe you classified them into simple, medium and high complexity. You add these up and here you have it: your estimate.
- Top Down: We gauge the project as to the amount of users, processes and interfaces with other systems, compare them with similar projects (client size, industry, Technology) and then come up with a rough number, not knowing for certain how these processes will be implemented technically.
The crux with bottom up approaches is you need to know a lot and be already very advanced in your requirements and design. This works well overall for small projects with a fixed scope, e.g. for a fixed 2 weeks sprint. But even there, this approach has its issues. Technology can be complex, tiny changes in requirements from a user perspective can make significant differences in Implementation costs, e.g. when you need to retrieve additional data from external systems.
Top Down approaches are your only way forward in complex long terms projects, you just don’t have enough details to estimate Bottom up. In essence, you need to predict the future in the presence of very little data. Even worse: Delivering at Software at Clients as compared to a product organization is demanding because you have no control over the Clients process. Even if you can accept (s)he cannot know all needed know, you do not even know if the right client team will be in place to tackle these uncertainties.
How we deal with Uncertainty when Estimating
If you need to deliver that magic number and you do not master black magic, you are in a bind and you need to get out of it with one of the following tactics:
1.You willingly over estimate the effort, that is you define a large buffer. For example you argue that a certain area like making the User Interface will be tedious, even though you know you have a great UI developer and perfectly well worked out wireframes. Often, this is even done in consent with your client contacts. You know the client hierarchies and procurement allow requesting effort once and you both know, there are many unknowns so you need to be on the safe side. This is the area you can easily justify, but in reality it is a buffer for all the ‘unknowns, which you do not even know’
I exclude the case of a ‘malicious salesman’, in my experience that is at best an edge case as all salesmen want to do more business with follow up projects. Even though there might be a moment of willingly exaggerating the effort, this is done with the intention to safeguard the overall success. Often, this is even done in ‘tacit approval’ with the client.
Here is another way to maneuver out of this dilemma. Typically you will use this strategy, if the trust base with your client is not strong enough for estimating with buffers.
2.You define a fixed scope, for example you will argue we will give only standard functionality which our platform already offers. There will be no customizations what so ever. This is essentially what happens in the Business 2 Consumer Market: You just get the app you download, exactly that and there are no changes for your specific situation.
This is ‘flipside’ of the 1st strategy. Either you inflate the effort or you entirely fix the effort. The difficulty is: a typical enterprise IT Project is not the same as ordering your new kitchen table. Enterprise processes are complex, technology and the process of large groups to come to a consent what needs to be done are (like in a parliament) inherently complex. No requirement leaves the process as it entered it. If the client comes across new requirements, you will need renegotiations.
Hence, to give Clients the ultimate flexibility you do not promise them Functionality but Expertise.
3. You suggest a Time & Material Project. The Client buys hours from your team, you do not commit to a working software. This is very common if you will work closely with the client itself, who would for example deliver requirements and testing.
On face value, if you are the supplier this is the preferred approach. Because you take little risk. If the delivery gets into stormy weather the ship may sink as long as your team performed — and who can measure or contest that. But most of these risk approaches also carry a risk for yourself. Good deals contain the seed for the next deal, if you sell some hours and your client fails or gets the skills (s)he needs somewhere else, you lose mid- and long term.
But hold on, didn’t we make some great progresses in predicting future events? Yes, we did. In Tech, right in front of our eyes: Neural Networks are able to make some amazing predictions in very disparate areas like loan credit analysis for skin cancer detection. It is wise to learn from a success story.
How Machine Learning predicts the Future
Within Data Analytics, Machine Learning is a method used to devise complex models and algorithms that lend themselves to prediction. Neural Networks are a branch of machine learning, that loosely mimics brain cells and their connections, deep neural networks use hidden layers to model complex relations between input and a predicted output. While many basic ideas exist for decades, they went through a revival with using large datasets and stronger CPU powers to generate convincing results.
Despite their mathematical notation and functions, the strategies of Neural Networks are often common sense. There is a plethora of different Models and Mechanisms but they typically all follow the following strategies. Hence, we could use them to guide our actions as a sophisticated heuristic to guide our actions.
Note, with this short comparison we do not claim to develop an entire framework for estimating. We do claim however that taking a close look at a formalised and successful theory to predict the future could lend many benefits to our ways of estimating project efforts.
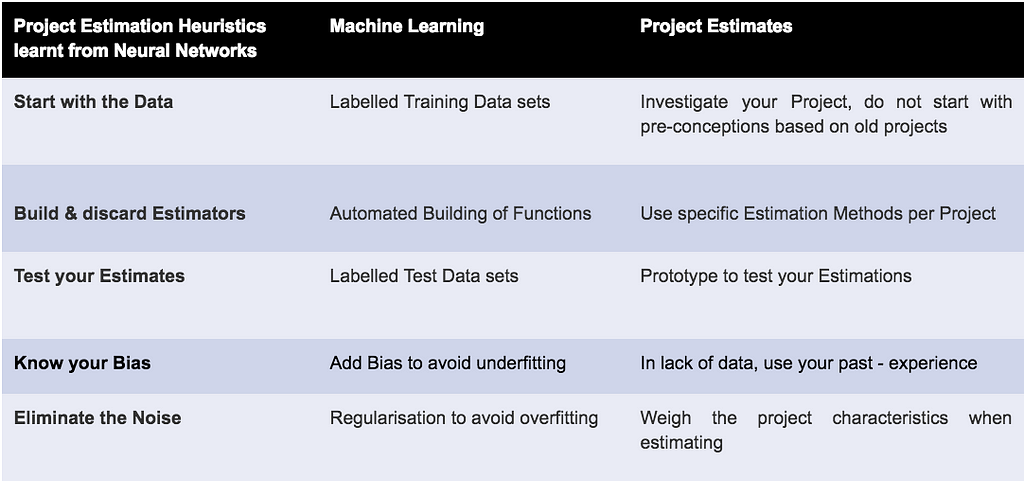
Start with the Data — your experience is secondary
If you look at how a Neural Network is build, there is a striking difference with how we try to estimate Projects.
A Neural Network starts with the Data, for example we would have a large sets describing past projects and ‘label’ all of them with the effort that we really needed to deliver. We then let sophisticated models build a ‘theory’, a mathematical function that is able to predict the documented efforts. The bet we make is: for a new project, where we do not know the effort yet, hopefully this function will predict accurately what we will need.
In ‘Project world’ often the implicit ideal is to seek for one ‘master estimator’. Such an estimator, e.g. a huge excel sheet with many columns, would have so many factors (technology, industry, user base, integrations) and ran through so many project iterations, that it is able to capture the essence on how to predict the effort at a point of time in the future.
Machine Learning could tell us that we are not focussing enough on gathering specific data for the project we are trying to estimate. Making assumptions and deductions based on previous experiences with different projects at different clients do not seem to be a promising strategy and yet, we often follow this strategy.
Build & discard many estimators
In Neural Networks, we do not have the ambition to (over-) generalise towards one theory. As long as as we have enough data to feed the algorithm, we might be better off to take data from a very specific distribution like for example only projects from a specific Industry. Building the ‘theory’, the function to predict the outcome, is an automated process. Machine Learning focus on this automated building of predictors and to achieve that is seeks for patterns in existing data.
You happily throw away your function being confronted with a new dataset to build a new prediction function
For our way of estimating project effort this would mean we are much better off with building a new estimator (this is our prediction function, our ‘theory’) for every industry, technology and even every project, as soon as we can get hold of sufficient data. Looking for this one estimator to predict any effort is a strategy that our successful role models do not follow
Tested Estimates — no exceptions
This idea is strikingly simple, it actually it is hard to excuse, that we do not use this straightforward idea when estimating Project Estimates. After a Neural Network build a function to map inputs (your description of a project) towards the output (the effort we needed for the past project), we test the function against a smaller part of the dataset we had put aside for just that purpose: Can we verify our function generalises well and can predict effort for data it has not previously seen?
In projects this means it is nothing other than foolish to estimate a complex several month project, without making for example a prototype or minimal viable project to test if the effort predicted is actually sufficient to deliver the needed solution.
It is common sense to test assumptions, the only reason why we do not choose this approach in any single project is of course the power relations between vendor & supplier. Both sides might not be willing to admit the difficulties to predict the effort and both sides might hope when the effort turns out to be inaccurately estimated they might be the benefittors.
Machine Learning teaches us that not testing our estimates is an unprofessional approach and should be rooted out entirely.
Know your Bias & Eliminate the Noise
Neural Networks operate with the concepts of under- and overfitting data.
‘Underfitting’ your data means you are not building a function well enough to even predict the efforts of project we know to be correct. Sometimes, we can deal with that by adding ‘bias’, that is basically we add a value, that we cannot deduct from the data, simply because we believe to know from other sources how to predict the effort.
This is common and can be understood as a psychological state: You assume deploying software is easy — but it is not. You have no data to back your claims, but you smuggle in such bias. You shouldn’t do that — we know that. Machine Learning can remind us of that and give us some terminology to point that out.
Overfitting represents the flipside of the coin. You have built an estimator that predicts the efforts for your existing project data in detail. You might have a lot of information (‘features) about your project but not look at so many projects to look at. In a sense you ‘overdo’ your explanation. Your predictor will not generalise well to unknown data, because you might have listened to ‘noise’, that is some information about your project (was the project room on the north- or south side of the building) that is irrelevant but blurs your analysis.
There are ways to systematically deal with overfitting. For example you could reduce the Information you have about your projects and manually eliminate features that do not seem relevant. Another strategy is referred to as ‘Regularisation’: you keep all information (so you do not run the risk of losing information), but you will give them different weights.
We will not go into these techniques, but we do want to stress that Project Estimations could learn a lot from these proven techniques.
Here is a short summary of the analogies we pointed out
A more subtle point is the following: Machine Learning actually uses a lot of energy to detect features that really make a difference and might be invisible to the human spectator. We as humans come up with features like the ‘developer is experienced’ or ‘the UI is complex’, because we know this can impact our project estimate. AI does that by itself based on your data. This could allow us to make the factors we want to use less pre-determined by our stereotypes. Producing software is a social process, it would not be a surprise soft factors like culture of company or the communication tools we use have a huge impact on our delivery and might even be more important than the very technology we use. But even this is a bias I bring up, a Machine could come up with features that we didn’t expect.
It does not seem unlikely, if we had proper data sets, that we could come up with Algorithms to predict project estimates much more accurate than we do so far. Replacing humans with Algorithms has the immense advantage of allowing us to process much larger data-sets than humans can possible. Even the most experienced consultant, who estimated and delivered many projects, is an amateur against an Algorithm running against very large datasets.
Summary — Admit to Address
The word ‘estimate’ and qualifications like ‘rough estimate’ redefine the meaning of an estimate. An estimate is always ‘vague’ or ‘rough’. Estimates are just that: estimates. For medium to complex products placing estimates into the heart of our corporation model introduces a risk.
If we admit the ‘estimation problem’, we can deal much better with uncertainty. Project estimates break for the same reasons any prediction fails: we do not have sufficient data to predict the future, we did not build our models accurately and so on. Machine Learning Networks can tell us, where we can improve.
But once we admit the inherent difficulty to predict requirements, implementation techniques and the efforts, we could just as well come to a more radical approach. If estimates are inevitably very often incorrect, we might better not build too much on them. A smarter approach makes Estimates, even requirements a means to an end: your goal, like for example speeding up a business process or making your end users more efficient servicing clients in a call center.
Bitcoin is a network that is able to align different interests in a network such that unknown parties trust each other. We can learn something from that technological setup for our project work, we will discuss this in the 2nd part of the blog.

The Dark Art of IT Project Effort Estimation: Estimates are broken was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.