Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
“Occlusion” means hiding virtual objects behind real things.
One of the biggest and most elusive pieces of the augmented reality puzzle is occlusion. In other words, the ability to hide virtual objects behind real things.
This post is about why occlusion in AR is so hard and why deep learning might be the key to solving it in the future.
When you look at a purely real or a purely virtual world, you tend to accept the “rules” of that world or suspend disbelief, as long as it satisfies some basic notions of reality like gravity, lighting, shadows etc. You’ll notice when these rules are broken because it’s jarring and feels like something “doesn’t look right”. That’s why it’s so instinctual to cringe at bad special effects in movies.
In VR, it’s actually quite easy to achieve suspension of disbelief because you have complete control over all elements in the scene. Unfortunately, as an AR developer, you don’t have this luxury because most of your app’s screen real estate (i.e. the real world) is totally out of your control.
As an AR developer, most of your app’s screen real estate (i.e. the real world) is totally out of your control.
In the mobile world, Apple’s ARKit has achieved incredibly fast motion tracking as well as realistic lighting and shadows, but it’s still lacking when it comes to occlusion.
Here’s an example:
Does the screenshot below look strange to you? It’s because the dragon looks like it’s further away from the chair but still appears in front of the chair.
Without occlusion, this dragon looks weird overlapping the chair.
This isn’t just a problem with mobile AR. It’s also a problem on every headset available today.
How does occlusion in AR work?
The goal of occlusion is to preserve the rules of line-of-sight when creating AR scenes. That means any virtual object that is behind a real object, should be “occluded” or hidden behind that real object.
So how is this done in AR ? Basically, we selectively prevent parts of the virtual scene from rendering on the screen based some knowledge of the 3D structure of the real world.
Doing this involves 3 main functions:
- Sensing the 3D structure of the real world.
- Reconstructing a digital 3D model of the world.
- Rendering that model as a transparent mask that hides virtual objects.
But what is so hard about it?
Assuming you have a good reconstruction of all the objects in your real environment, occlusion involves simply rendering that model as a transparent mask in your scene. That’s the easy part. It’s getting to that point where things start to get unwieldy.
Consider a common street scene. There are people, vehicles, trees and all kinds of objects at various distances from you. Further away, there are larger structures like bridges and buildings, each with their own unique features.
 The real world is a complicated and dynamic 3D scene
The real world is a complicated and dynamic 3D scene
The hardest thing about creating a realistic occlusion mask is actually reconstructing a good enough model of the real world to apply that mask.
That’s because no AR device available today has the ability to perceive its environment precisely or quickly enough for realistic occlusion.
How does 3D sensing work?
Sensing 3D structure really boils down to one important ability — depth sensing. Depth sensors come in many flavors, the common ones being Structured Light, Time of Flight and Stereo Cameras.
In terms of hardware, Structured light and Time of Flight involve an Infrared projector and sensor pair, while Stereo requires two cameras at a fixed distance from each other, pointing in the same direction.
At a high level, here’s how they work:
Structured Light Sensor
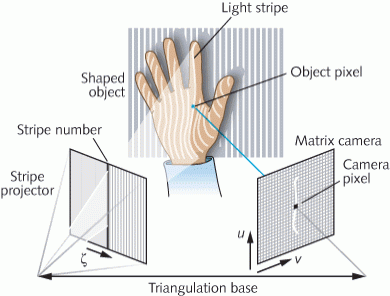
Structured Light sensing works by projecting an IR light pattern onto a 3D surface and using the distortions to reconstruct surface contours.
Time-of-Flight Sensor
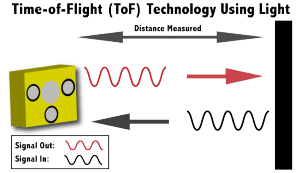
This sensor works by emitting rapid pulses of IR light that are reflected by objects in its field of view. The delay in the reflected light is used by an image sensor to calculate the depth at each pixel.
Stereo Cameras
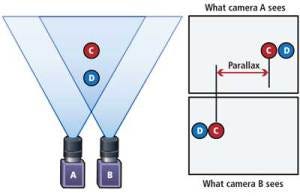
Stereo cameras simulate human binocular vision by measuring the displacement of pixels between the two cameras placed a fixed distance apart and use that to triangulate distances to points in the scene.
Of course, all these sensors have their limitations. IR based sensors like have a harder time functioning outdoors because bright sunlight (lots of IR) can wash out or add noise to the measurements. Stereo cameras have no problems working outdoors and consume less power, but they work best in well-lit areas with a lot of features and stark contrast.
All you need to do to confuse a stereo camera is point it at a flat white wall.
Since all these sensors work on pixel-based measurements, any noise or error in the measurements creates holes in the depth image. Also, at the size and capacity of phones and headset devices today, the maximum range achieved so far has been about 3–4 meters.
The image below is an example of a depth map created with a stereo camera. The colors represent distance from the camera. See how the measurements are good at a close range while further objects are too noisy or ignored?

3D perception doesn’t end at depth sensing. The next step is to take the 2D depth image and turn it into a 3D point cloud model where each pixel in the depth image gets a 3D position relative to the camera.
Next, all the camera relative point clouds are fused with an estimate of camera motion to create a 3D point cloud map of the world around the sensor.
The video below illustrates the complete point cloud mapping process.
Now that you understand the complete pipeline of 3D perception, let’s look at how this translates to implementing occlusion.
Using Depth Sensor Data for Occlusion
There’s a few ways 3D depth information can be used to occlude virtual objects.
Method 1
Directly use the 2D depth map coming in from the sensor.
In this method, we align the camera image and the depth map and hide parts of the scene that should be behind any pixels of the depth map. This method doesn’t really need a full 3D reconstruction since it just uses the depth image.
This makes it faster but has a few problems:
- The sensor can only detect objects up to 4 meters away. Anything further won’t be occluded.
- The depth map has holes and isn’t perfect
- The resolution of the depth map is much lower than the camera which means scaling and aligning the two images will create pixelated, jagged edges for occlusion.
The video below is an example of depth map based occlusion. Notice the irregularities in the Occlusion mask as the red cube is moved around.
Method 2
Re-construct and use the 3D point cloud model.
Since the point cloud is a geometrically accurate map of the real world, we can use it to create an occlusion mask. Note that a point cloud itself isn’t sufficient for occlusion, but point clouds can be processed to create meshes that essentially fit a surface onto the point map (like a blanket covering your 3D point cloud).
Meshes are much less computationally intensive than point clouds and are the go-to mechanism for calculations like detecting collisions in 3D games.
This mesh can now be used to create the transparent mask we need to occlude virtual elements in our scene.
Well that sounds like we have a good enough solution for Occlusion! So what’s the problem?
The problem with AR devices today
The 3 AR devices that I think have the most impressive tracking and mapping capabilities today are Google Tango, Microsoft Hololens, and Apple iPhone X. Here’s how their sensors stack up against each other.

Google Tango (Discontinued by Google)Depth Sensor — IR time-of-flightRange — 4m
Microsoft HololensDepth Sensor — IR time-of-flightRange — 4m
Apple iPhone XForward facing depth sensor — IR Structured lightBack facing depth sensor — Stereo CamerasRange — 4m
The main problem with all the above systems is that in terms of depth sensing, they have:
- Poor range (<4m): The size and power limitations of mobile devices restrict the range of IR and Stereo depth sensors.
- Low resolution: Smaller objects in the scene are not discernible in the point cloud and it’s really hard to achieve crisp and reliable occlusion surfaces.
- Slow mesh reconstruction: Current methods of generating meshes from point clouds are too slow for real-time occlusion on these devices.
Generating a mesh from a point cloud, currently, isn’t fast enough for real-time occlusion on any tablet or headset device.
So how does a developer today hack together a reasonable solution to get around these issues?
How can you hack occlusion today ?
Perfect occlusion is an elusive target, but we can get close to it in some situations, especially when we can relax the real-time constraint.
If the application allows pre-mapping the environment, it’s possible to use a pre-built mesh as an occlusion mask for the larger prominent objects in the scene, provided they don’t move.
This means that you’re not limited to the 4m range of the depth sensor, at least for occlusion behind static objects.
Moving objects are still a problem and the only solution right now it to use the depth map masking method for close range moving objects like your hands.

Now it’s clear from the example mesh above that a big problem with pre-built meshes is that although they’re lighter than point clouds, they can cause more than a ten-fold increase in the complexity of your 3D content.
The way to simply a 3D mesh is to approximate its structure with simpler objects like walls and blocks that envelope complex structures.
At Placenote, we’ve built guided tours of large museums in AR and the way we hacked occlusion was to manually draw planes to cover specific walls in the space that might get in the way of our virtual content.
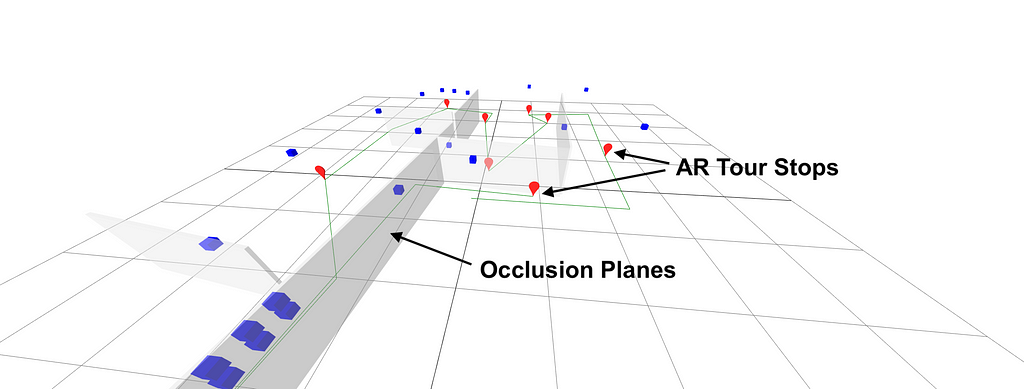 A Unity scene that shows how we hacked Occlusion at Placenote. Visit placenote (https://placenote.com)Here’s an example of occlusion with a high-quality, pre-built environment mesh on Google Tango.
A Unity scene that shows how we hacked Occlusion at Placenote. Visit placenote (https://placenote.com)Here’s an example of occlusion with a high-quality, pre-built environment mesh on Google Tango.
Of course, this method assumes that either the developer or the user will take the time to map the environment before the AR session.
Since this might be a bit overwhelming for the average user, it likely works best in location-based AR experiences where the map can be pre-built by the developer.
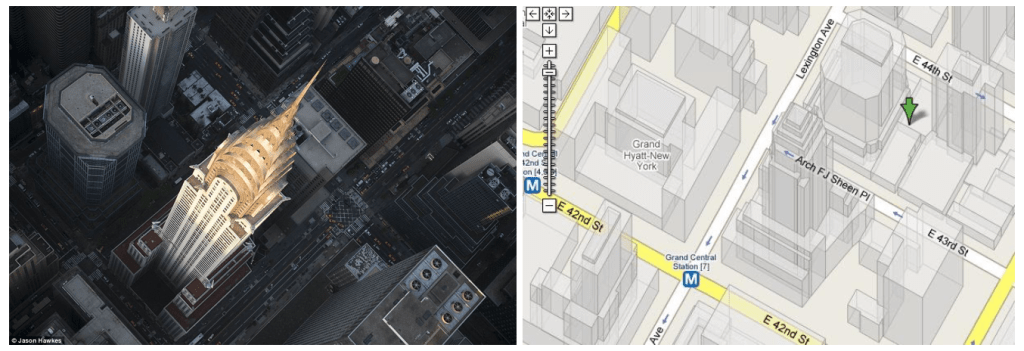
In an extreme scenario, you might want to occlude an AR experience at a much larger scale, like rendering a dinosaur walking among buildings in New York City. Perhaps, the way to do this is to use known 3D models of buildings from services like Google Maps or Mapbox to create occlusion surfaces at the city scale.
Our friends at Sturfee have built a unique way of creating city scale augmented reality experiences, using satellite imagery to reconstruct large buildings and static structures in 3D. Sheng Huang at Sturfee has written about their platform here.
Of course, this means you need to be able to accurately localize the device in 3D, which is quite challenging at that scale. GPS position is simply not good enough for occlusion since it’s slow (1Hz) and highly inaccurate (measurement error of 5–20 meters).
In fact, centimeter-level position tracking indoors and outdoors is a critical component of occlusion and through our work with Placenote, we’re working towards a cloud-based visual positioning system that can solve some of these problems.
What does the future look like?
While pre-built meshes are great for AR experiences tied to a single location, occluding moving objects still requires instant depth measurements at a range greater than just 4m.
What’s needed to create a realistic AR experience is a sensor that produces a high-resolution depth map with near infinite range.
Improvements in sensing hardware can certainly help squeeze greater resolution and range from IR or Stereo sensors, but these improvements will likely hit a ceiling and produce diminishing returns in the near future.
Interestingly, an alternative approach has emerged in 3D sensing research, that turns this hardware problem into a software problem by leveraging deep learning to improve the speed and quality of 3D reconstruction.
Neural networks might be the key to solving occlusion in the future.
This method uses neural networks that can pick out visual cues in the scene to estimate 3D structure, much like the way we as humans estimate distance. (i.e. guessing distance by using our general knowledge of the sizes of things in the real world. The networks are trained on a large dataset of images and are capable of segmenting out objects in a scene and then recognizing them to estimate depth.
That means, if we can design the neural networks and train them on a good enough dataset, we might be able to bypass a lot of limitations in resolution and range present in current depth sensing technologies, with no added hardware costs.

The image above is from a paper that explores methods to segment and label scenes using neural networks in combination with depth sensors to improve the quality of generated maps.
You can find the full text of the paper here.
In Summary
- Occlusion is, by far, one of the biggest pieces of the AR puzzle because it makes the biggest leap towards realism for AR experiences.
- Depth sensors today are too slow, have limited range and low resolution for real-time occlusion.
- You can get around these limitations by building AR apps in areas with pre-built environment meshes. Try Placenote SDK to build location-based AR experiences.
- The key to solving the range and speed limitations of depth sensors in the future might be deep learning and this approach is already showing promising results.
If you’re a new AR developer looking to build compelling AR experiences, don’t let occlusion stop you. Remember Pokemon Go? Poor occlusion in Pokemon Go resulted in some hilarious AR screenshots that spread all over the internet and helped with the meteoric rise of the game.
So have fun with it!
If you want to build amazing AR experiences on iOS or Unity, partner with us, or join our team, let’s connect! Just fill out the form below.
Who are we?
We’re building an SDK for persistent, shared augmented reality experiences. We call it Placenote SDK.
Special thanks to Sheng Huang, Dominikus Baur, David Smooke and Peter Feld for your help with reviewing this article!
Why is Occlusion in Augmented Reality So Hard? was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.