Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
In the last post I’ve talked about how to identify service boundaries. As promised, here I consider an example.
Payment service provider decomposition
Introduction
My first example is a Payment Service Provider. Let’s name it “Super PSP”. It is integrated with every psp from this list as well as with a hundred of banks and mobile operators, thus being a Payment Aggregator. Our clients are an online-stores which don’t want to integrate with all those payment systems and banks and mobile operators etc, so they go to Super PSP, integrate with it and that’s it. They can make calls to our API and get the whole bunch of payment systems at their disposal. Besides, Super PSP has a web-interface where its clients can view and operate payments, change some settings, get reports, get all kinds of statistics, etc. Besides they can have a web-interface where their customers can choose a payment system and pay their order.
So let’s get straight to the point and consider its business-functions, or business-capabilities. With such a declarative approach it doesn’t really matter what concrete technique you use, so I won’t strictly cling here to any of them.
Higher-level services
Overall viewIt all starts with the Marketing activities. This is a primary way how Super PSP gets its customers. If a company is interested and wants to process payments with us, their next stay is Sales service. Sales service basically is about what functionality customer wants to use and how much is that. Then customer is off to go to process payments — say hi to Process payments service, or Payment processing service, if you like it better. Somewhere close to it Customer support, or Services, resides. It is ready to help you out if you have any questions. By the end of the month we reconcile our payments with the ones registered on the payment system’s side. Then we actually bill our customer. So our higher-level services view can be like that:
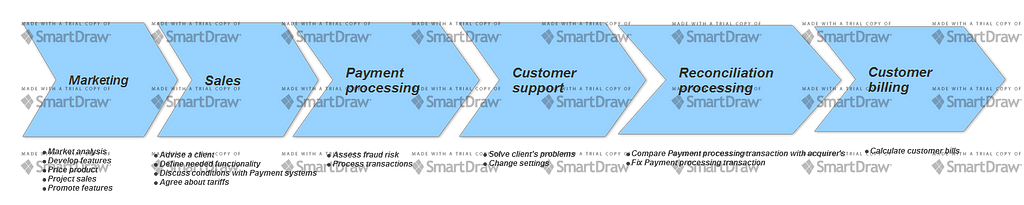 PSP Value chain
PSP Value chain
It is likely to be changed further though as we get deeper into each of them.
MarketingLike any other company, Super PSP needs people engaged in business development. So the corresponding staff workers do market analysis. Their primary concern is what customers need. So they identify product features. Then they promote upcoming or existing products. They might determine pricing strategies, and if they do, they do some sales projections as well.So what about the naming? What name suits best for above activities? It might be Product development or Business development. Or we can use pretty common name like Marketing.So we have the following hierarchy for Marketing service:
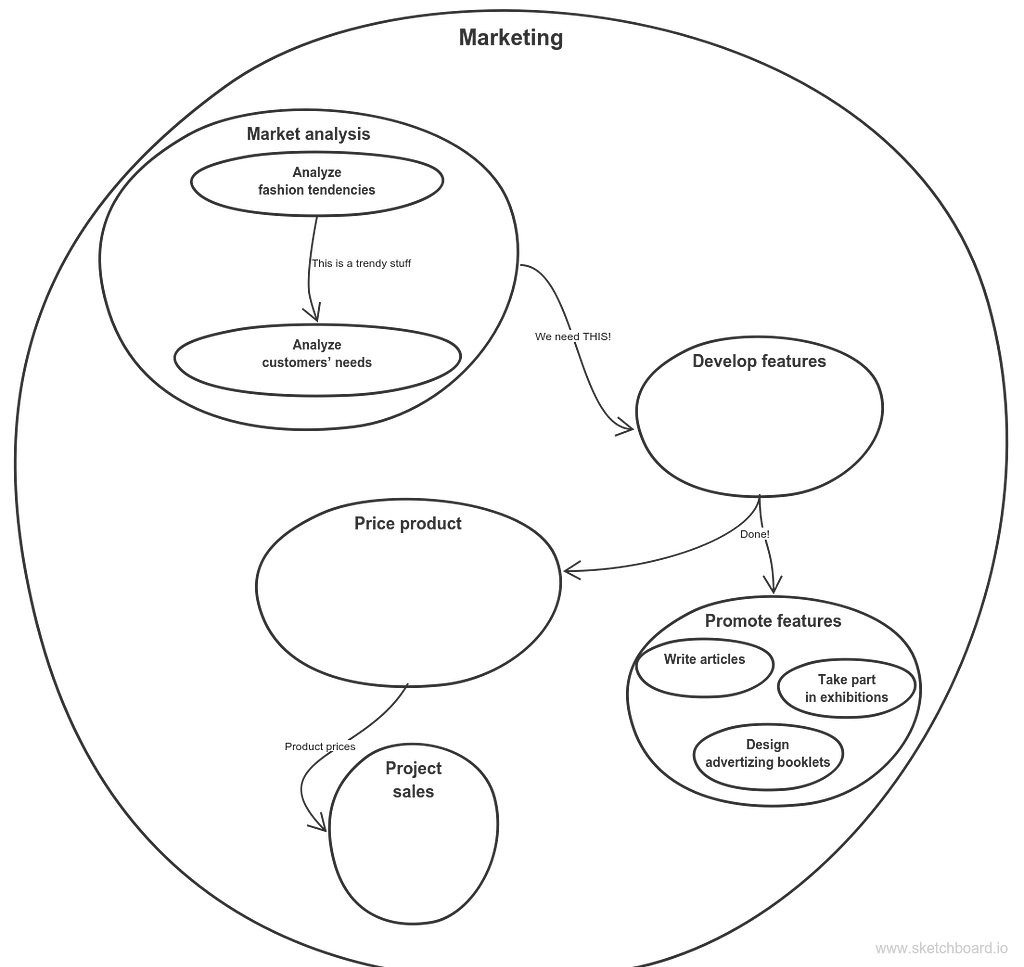 Marketing service
Marketing service
SalesThen Super PSP sells their product, which is SAAS. By the process of selling I understand the building of long-term and mutually beneficial cooperation, which implies usually frequent communications and help. It includes client consulting — even at first, when the client are not yet clients in a legal sense. At that stage they are told how the business operates, why Super PSP does their job better than others, where exactly they are better and where they are weaker, and whether Super PSP really solves the client’s issues. After that he needs more detailed consulting: what payments systems client wants to use, what Super PSP’s features he wants to get besides just payment processing, etc. Next, Super PSP needs to discuss conditions with external payment systems that the client will work under. And they vary greatly depending on kind of business the client runs. Then Super PSP and its client need to reach an agreement about tariffs. Will it have fixed rates or interest rates? How often will the client have to pay?So, summing it up, business-service engaged in selling goes like this:
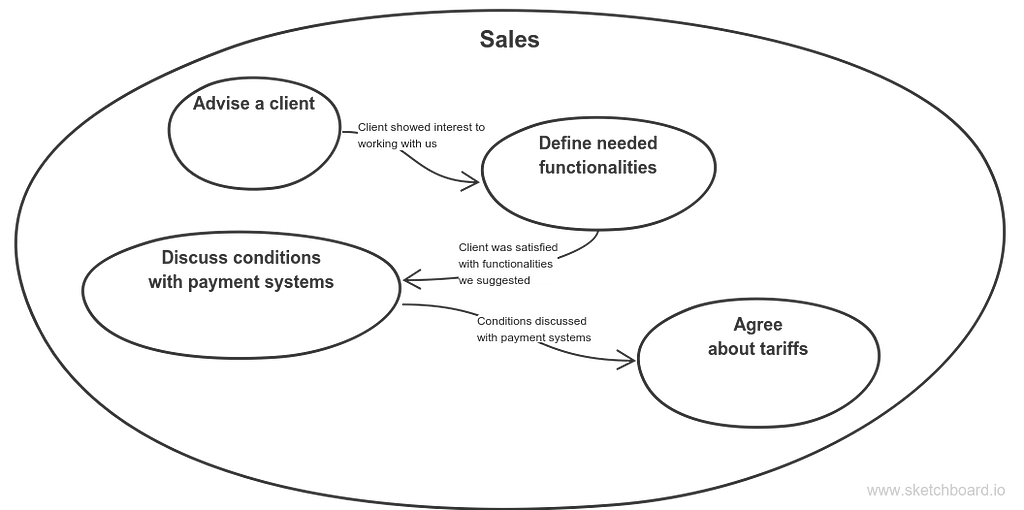 Sales service
Sales service
So we’ll call this business-service a Sales service.
Technical support, or Customer support, or ServicesTechnical support can be involved in several activities. Firstly, it is answering technical questions during the process of client integration into our system. For example, what headers we expect in http-response when sending transaction notification to our client. Or why the client request haven’t passed the validation. Or why the payment currency differs from the one sent to Super PSP’s gateway in a request by a client. Secondly, it is settings changing when the client is already integrated and processes payments via Super PSP. For example, client has a new endpoint for transaction notifications and he asks Super PSP to change the URL that is set in the system. Or a client asks to send him transaction reports monthly instead of weekly. Or change a payment application lifetime. And thirdly, it is answering the questions and solving problems that client has in the course of work. For example, why some specific transaction was declined. Or why there was no notification about some transaction.
Before trying to define whether it’s a higher-level holistic service or it is contained in some service or different parts of it belong to other services you should talk to your business-experts and stakeholders. How do they see the process of client integration in five years? How tightly is Sales coupled to Technical support? Do these services have different logical governments?
So from the one hand this capability is an implementation detail of higher-level Sales service, especially if you understand Sales as long term cooperation. So it might be included in Sales service. This is the case in SAP, for example. Moreover, from the more practical point of view, today the settings are changed by special technical specialists, tomorrow it will be done by Key account managers as web interface will get way simpler and the staff more technically savvy, and the day after tomorrow it will be done by the clients themselves by using Super PSP’s Settings API.
From the other hand it might be the standalone higher-level service called Service, like in Porter’s value chain. So it makes sense to take this approach if Key account managers do the technical integration and alongside answer customer’s technical questions, usually quite similar and the ones that don’t require deep understanding in none of the technical fields. So the Technical support is left with the responsibilities of aforementioned Service activity: “keep the product/service working effectively for the buyer after it is sold and delivered”. This separation of concerns makes even more sense if there are a lot of clients and Super PSP has a lot of functionality, so the chances are that documentation is not correct in some places and sometimes it’s not evident whether the observed behavior is correct or wrong, so Technical support service can cooperate with developers to solve client’ issues.
So I take the second approach: I imply the Sales service staff to fill in the data needed to process payments and calculate client’s fees. With that in mind my Technical support service looks like that:
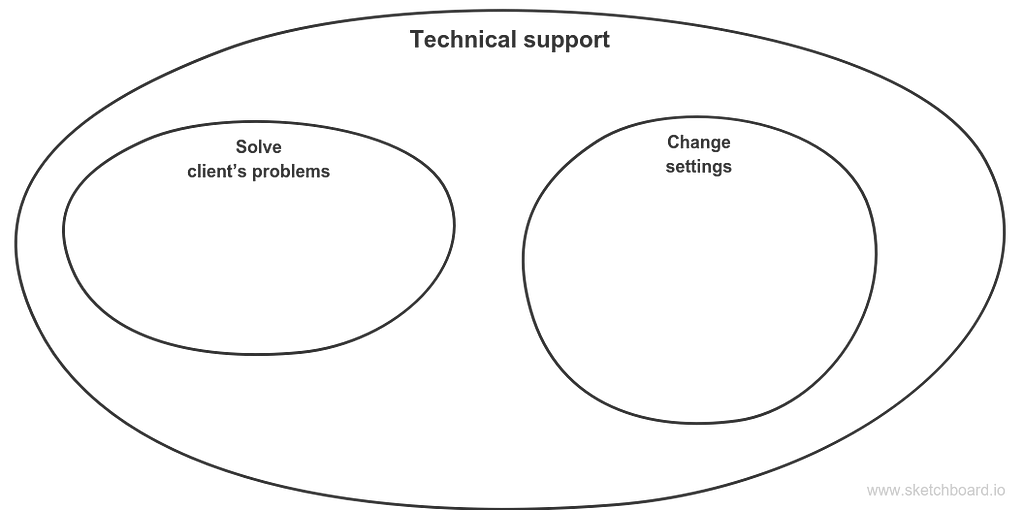 Technical support service
Technical support service
Process payments serviceThis service should do two things: make sure that the payment was initiated by the owner of the bank card that should be debited (if we’re talking about card payment) and actually payment processing: send request(s) to bank and perform all the necessary logic afterwards.As I already mentioned, my objects and services have pretty much in common. They contain some data, but they (usually) don’t expose it. They expose behavior. And they communicate with each other via messages: events or commands.There are two lower-level services here. The first one is responsible for performing payment and the second one is for fraud risk assessment. It is requested with command message in asynchronous request-reply manner, i.e. the assessment result is expected asynchronously. Its responsibility is totally context-agnostic — it’s just fraud risk assessment, so command message is valid here. Well, actually messaging infrastructure is not necessary here. We can safely implement this communication with http, but do it in aforementioned asynchronous manner.
So in the most trivial case there is only one bank that our system is integrated with and the pay operation doesn’t involve 3d-secure. This is how it might look like:
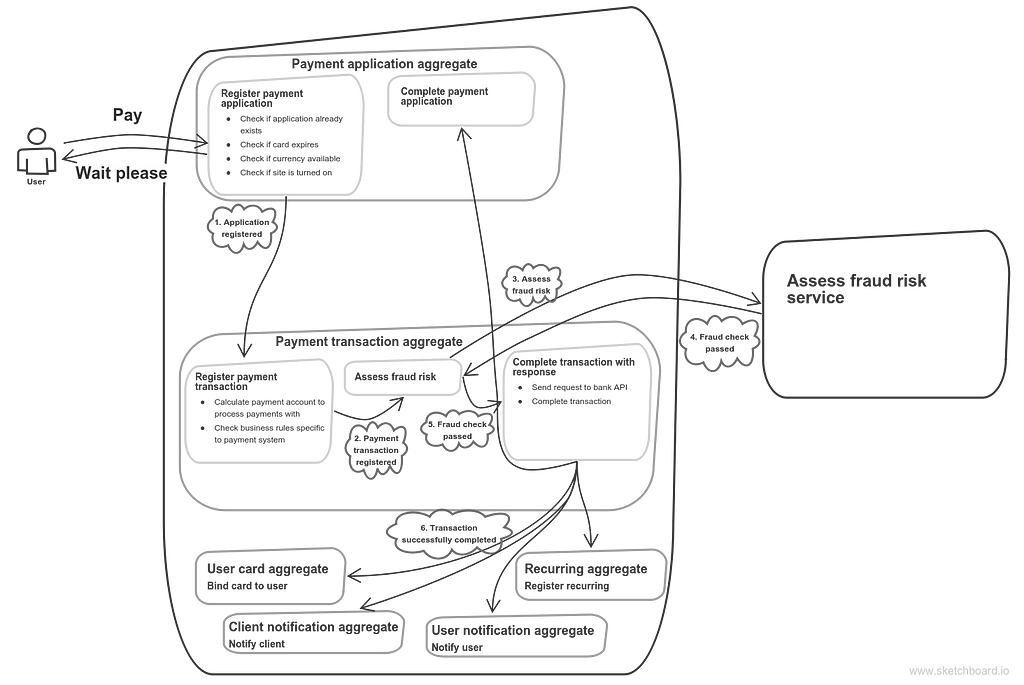 Non-3ds payment
Non-3ds payment
User sends pay command. Of course we don’t process it right away, we register payment application instead and reply politely with “Wait please”. This is a square with “Register payment application” label. It and the like indicate a message endpoint with the application logic noted at the label above (I stick to these terms), that involves and typically mutates the corresponding aggregate (in case you prefer Udi Dahan’s SOA then it’s saga) — payment application aggregate in this case. When all application invariants are checked and application actually registered, we publish a corresponding event. Then the next aggregate steps in — Payment transaction aggregate. When all business-rules are checked and bank account to process payments with is defined then it’s time to fraud risk assessment. If it’s ok then send request to the bank API and complete transaction with its response. Upon this there is some more to be done: for example, we probably want to register a recurring payment or bind card to user, and we definitely want to notify user and our client about the transaction.
More complicated case when we have 3d-secure check might look like the following:
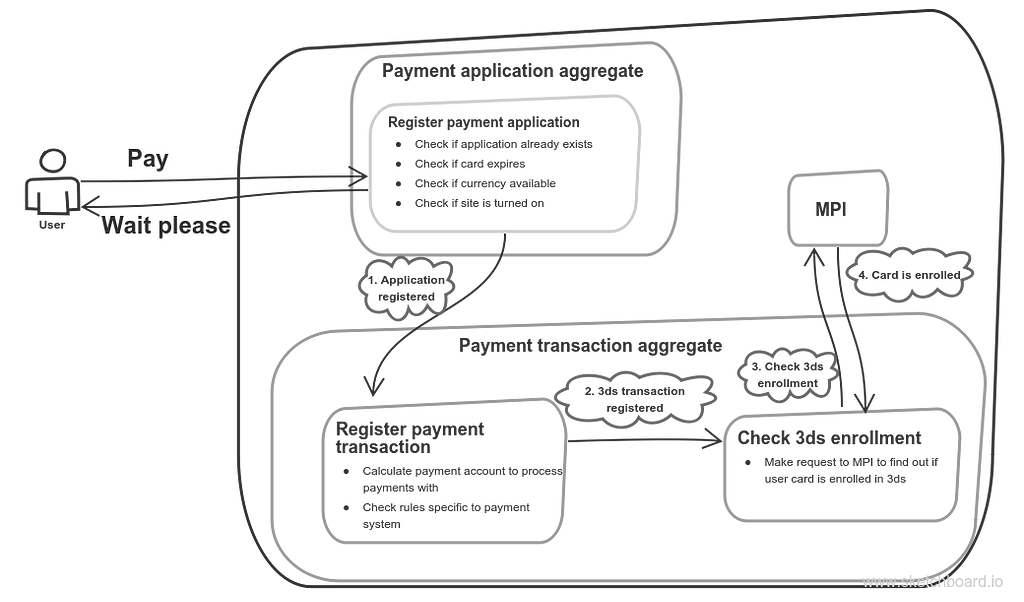 Payment with 3ds enrollment check
Payment with 3ds enrollment check
After it’s found out that user card is enrolled in 3d-secure program we redirect him to special access control server web-page where he fills in the code he received in sms. After he’s done this page redirects the user back to payment page where “Confirm 3ds” request is sent (simple flow explanation can be found here). So confirmation request can look like that:
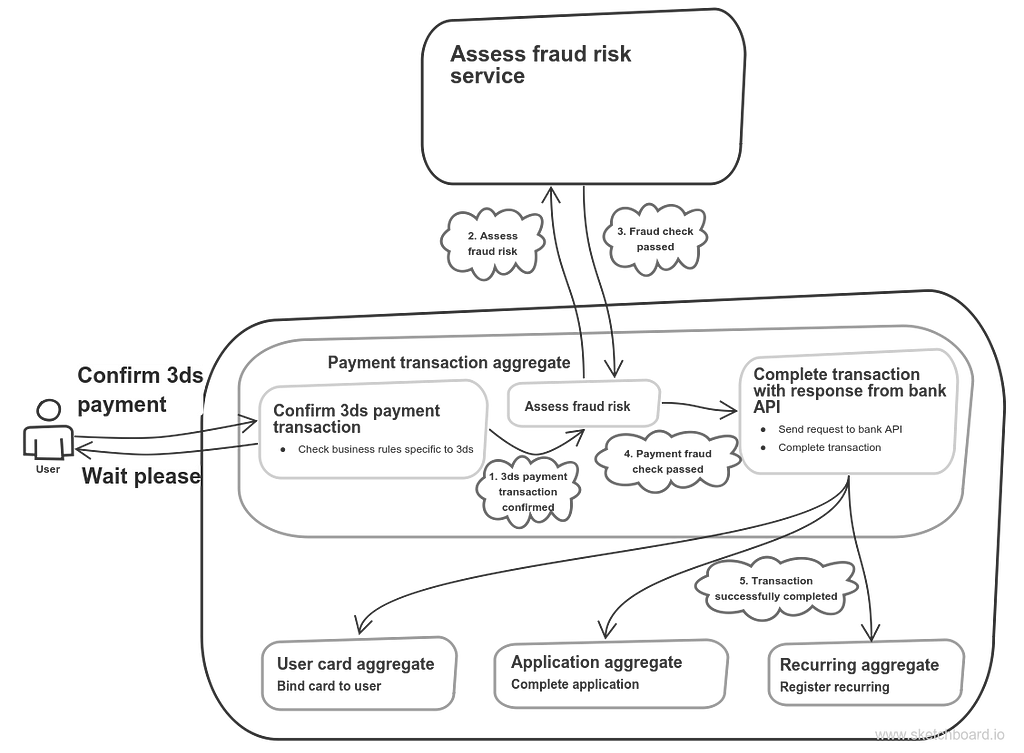 3ds payment
3ds payment
But Super PSP has a lot of banks integrated. Moreover, if a payment with some bank failed, the next bank will be switched on, transparently to the user. But I want it to be done in such a way that different bank integrations won’t know anything about each other and care only about one thing: process their own transactions. If something gets broken in one integration code, the others still work. So here is how it can be achieved:
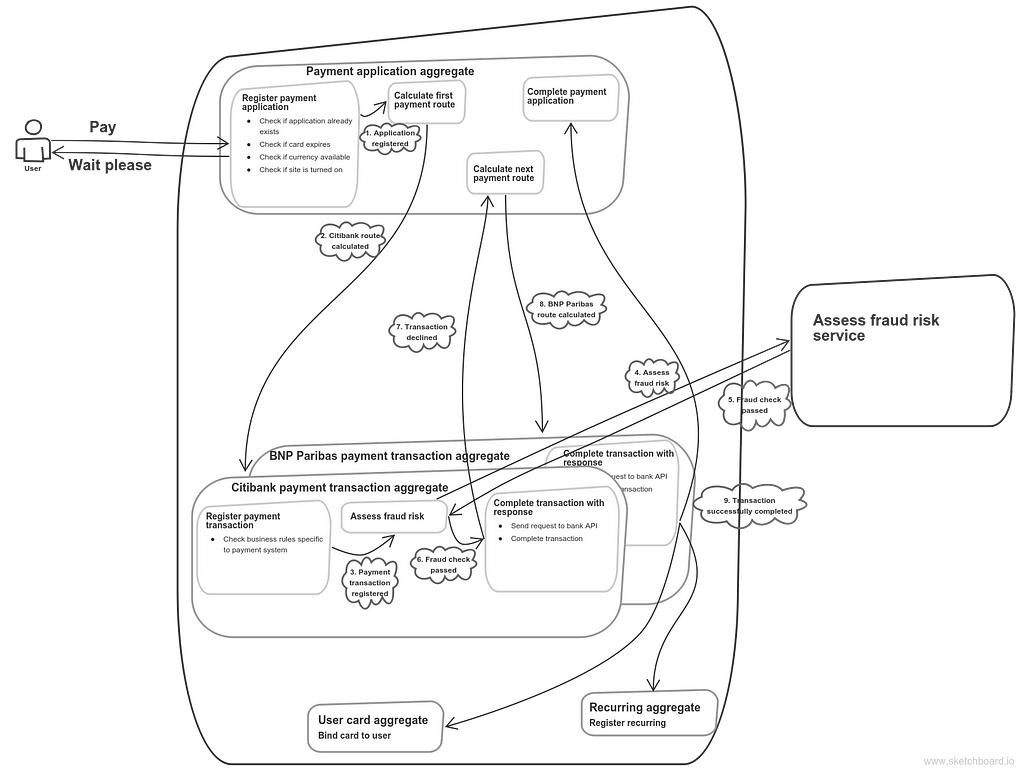 Several bank accounts take part in payment processing
Several bank accounts take part in payment processing
The next step is to split the payment by some trait. Say, none of the banks can process a single payment with amount exceeding $10000, but a user want to process a $20000 payment. But we don’t want him to handle this issue on his own, we don’t want him to pay twice with amount $10000. We can handle this ourselves. We can register several payment applications split by amount, which would have child-parent relation with the primary payment application. This can be implemented like this:
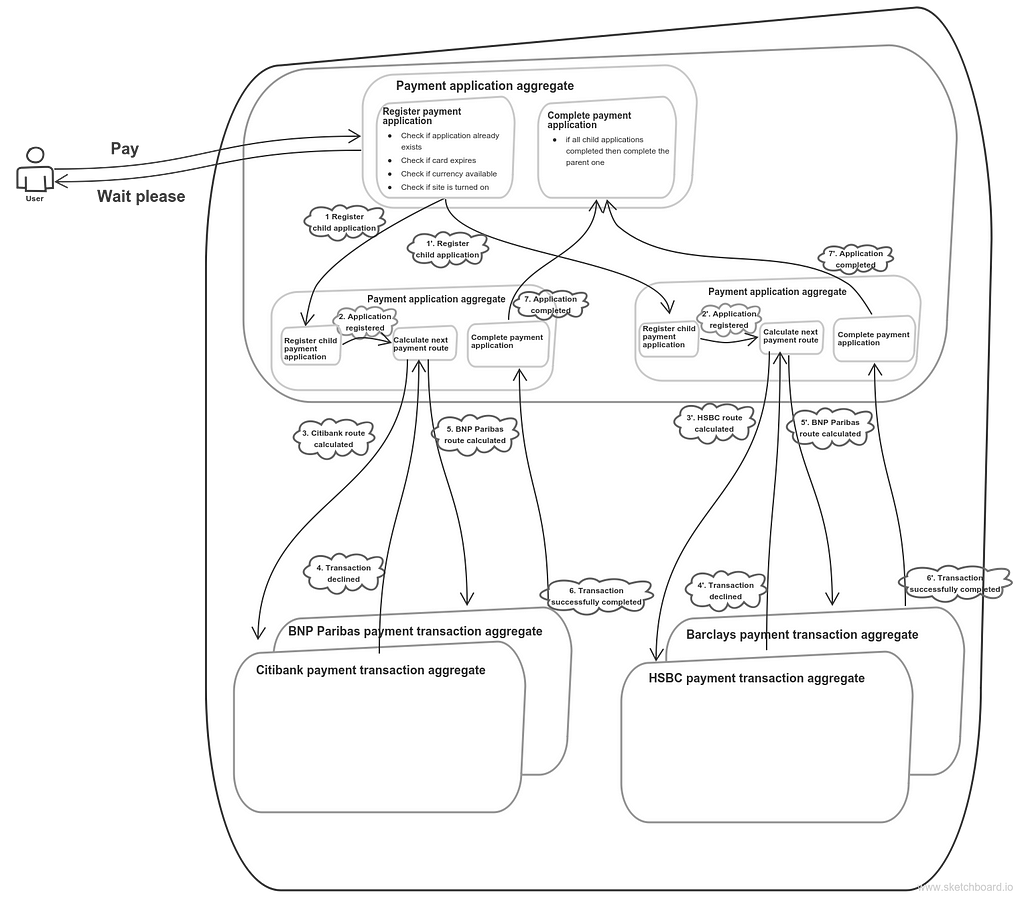 One application is split into two, resulting in two payment threads
One application is split into two, resulting in two payment threads
We can go even further and split the payment application across different payment methods: bank cards, purses, vouchers, mobile payments, etc. But I leave it as an exercise to the reader :)
For now the whole service has a single database. But if I’d need to scale some particular bank integration, this can be achieved without much difficulties:
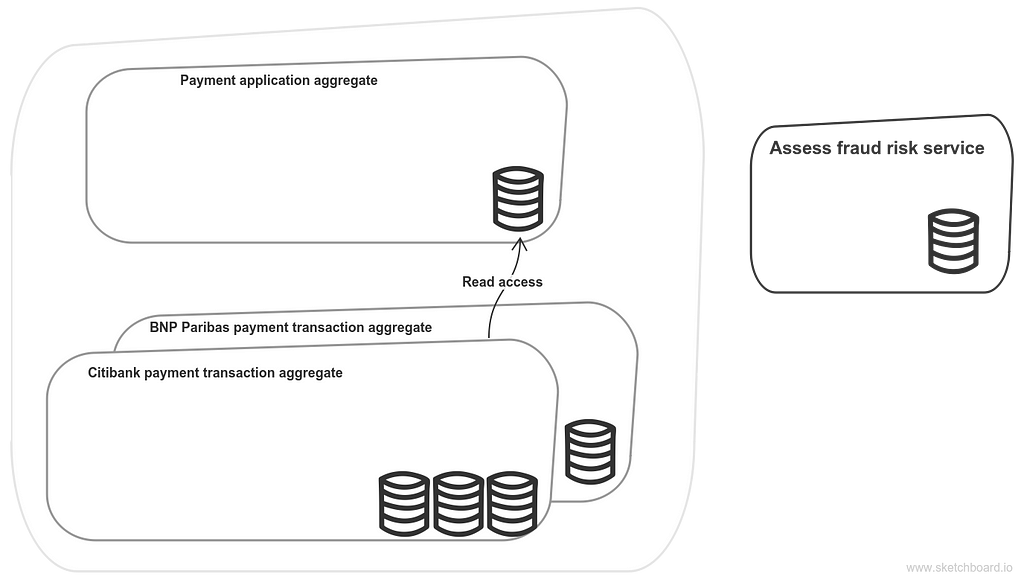 Scaling different payment integrations
Scaling different payment integrations
But there is a nuance here. How would Citibank integration code know about payment application data? See, it’s in another database. The first option is to pass that data in an event. The second — just connect to payment application’s database. Reader permissions would be enough for that. And I’m inclined to the second option. It’s totally fine while it is within a higher-level service.I consider the first option evil and there should be a very good reason to do that even within a service. There are two things I’d like to mention.The first one is that the data that I pass in an event would be a part of an aggregate that operates upon this data. In our case, payment application data would be a part of a payment transaction. So this data will have a life cycle. It will be mutated with some logic, some events would be published. And the notion of data ownership will be vague. The single source of truth will be vague and eventually lost.The second one is that coupling is getting tighter. It’s almost inevitable that duplicated logic will follow duplicated data. If so, shared libraries will appear. And this is the coupling that I’m talking about.And these are the reasons why CQRS should never be a higher level pattern.
Just like services are the building blocks of my higher-level architecture, aggregates are the building blocks within the lower-level services that communicate via messages. Just like my service architecture is a higher-level manifestation of Business-IT alignment, proper OOP, where there are no dumb data structures, where objects expose behavior instead of plain data, where domain model is not anemic, such OOP is a lower-level manifestation of Business-IT alignment.
So my mental image of almost any software I’m involved into looks like that:
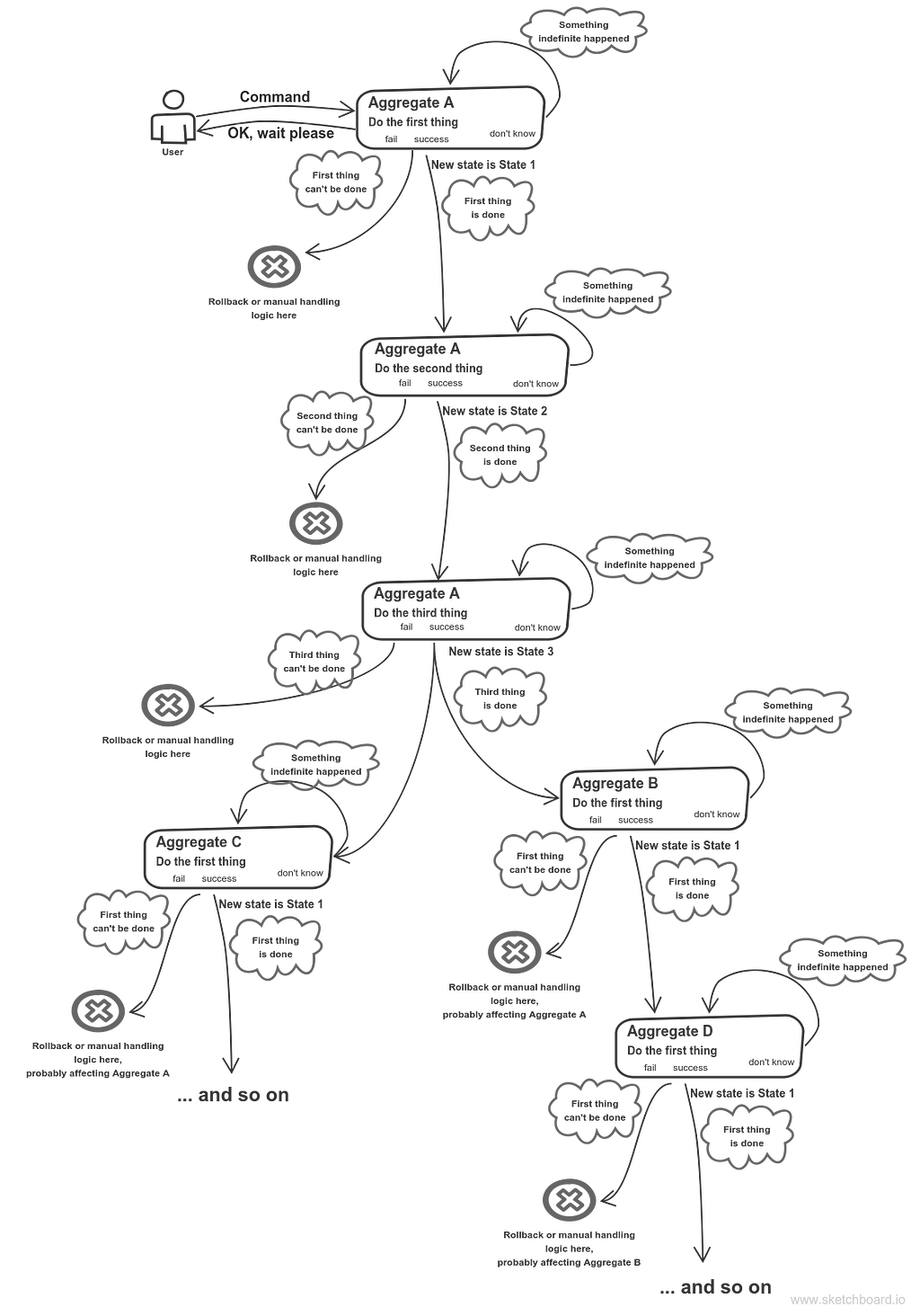 Aggregates’ (sagas’) communication
Aggregates’ (sagas’) communication
So, the borders of aggregates, implementing some use case set, can represent seams for further service decomposition.
Reconciliation serviceNow it’s time to reconcile payments. Super PSP needs to make sure that all transactions have correct status (successful transactions are really successful), correct amount and currency and correct payment date. This might not be the the case because of, for example, some bug in bank api software, that was fixed later. The logic is pretty straightforward and it might sound that individual Reconciliation service doesn’t have a right to exist until we face disputed transactions. Transaction workflow can last for several months and can be quite tricky.
How does reconciliation service gets transactions? Surely, I don’t want it to be integrated with Processing service via database — shared database integration is evil. I don’t want Processing service to publish an event with transaction data that Reconciliation service is subscribed to — it is higher level CQRS. I want reconciliation service’s transaction data to be transient and immutable by nature, with the smallest lifespan possible. So every month Reconciliation service loads transaction data from Payment processing service and starts the process of reconciliation. As transaction quantity can be huge, probably we shouldn’t use network for that. Just a bunch of files generated by Processing service and placed into Reconciliation service can be a better way. Anyway, generally the transfer process looks like that:
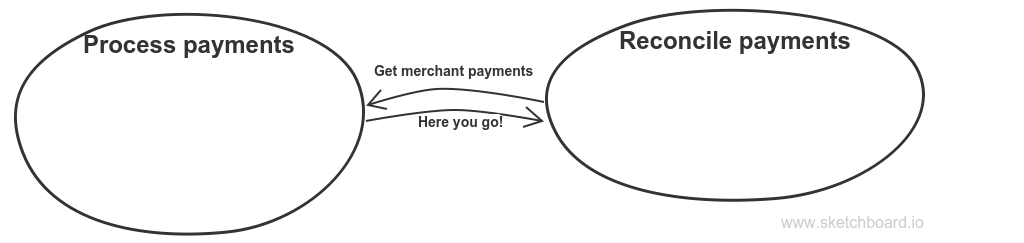 Transaction data transfer process
Transaction data transfer process
When transactions are loaded, reconciliation process begins for each transaction. Here’s how it can look like in a simple case, without any reclamation:
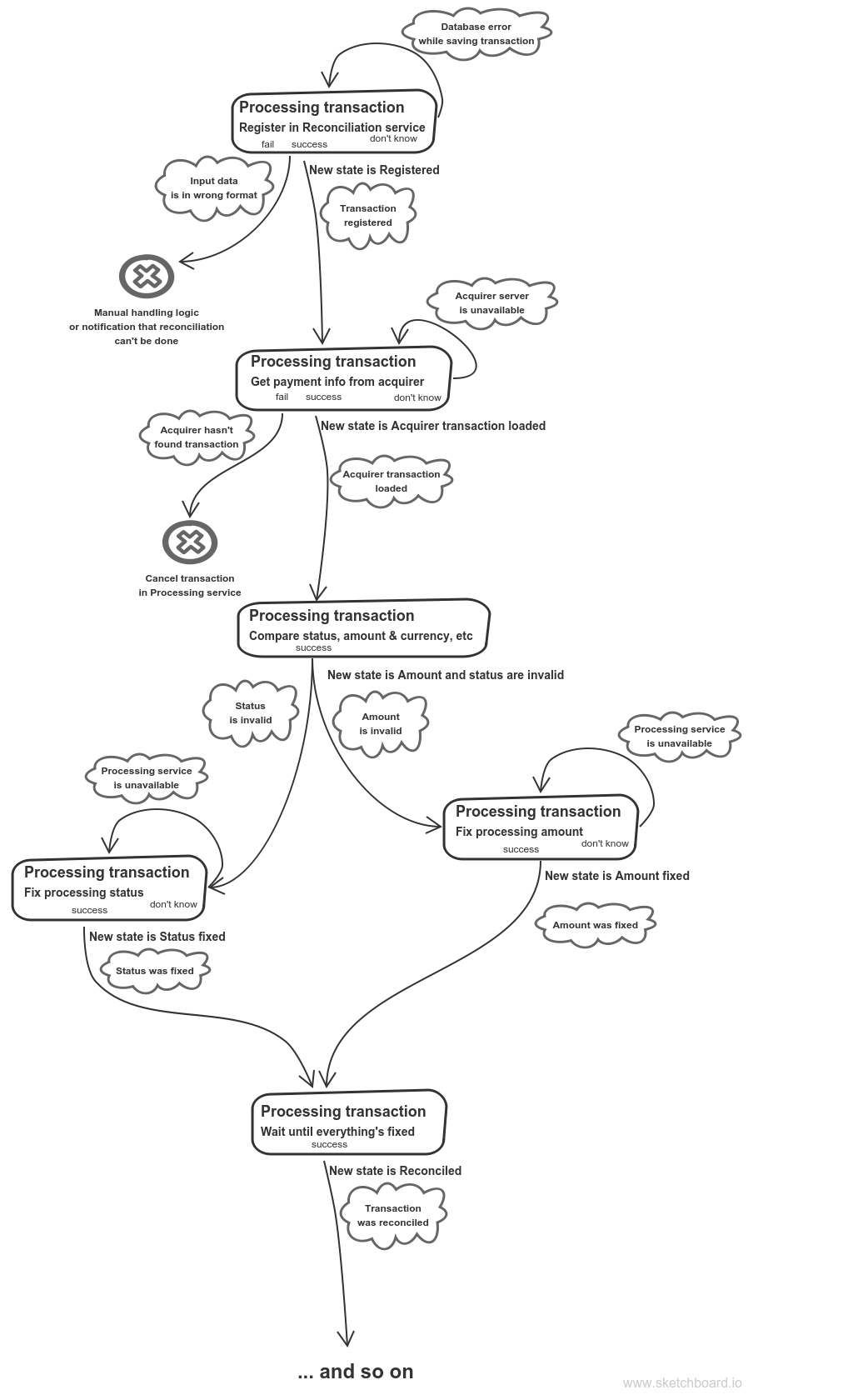 Processing transaction aggregate
Processing transaction aggregate
Let’s briefly take a look at what’s going on here. First, we create an object representing a Processing service transaction. Then we request an acquirer for some info about that transaction. Then we compare acquirer’s status, amount, etc with our own ones. In case they differ we fix Processing service transaction. When each transaction is reconciled we notify Customer billing service that we’re done.
What’s funny is that using this approach we can design fully immutable domain model. I’ll share the code in some later post.
Customer billing serviceWhen Customer billing service receives an event that customer transactions are reconciled it starts calculating customer bills. Again, this service doesn’t store any transaction data. Actually it even doesn’t a have a chance to do so as there are no higher-level events with transaction data. So it gets transactions from Process payment service the same way as Reconciliation service does — all at once. And again, I don’t think I need to worry that this service requires a lot of data from some other service. Conceptually it doesn’t differ from the case when somebody manually calculates customer bills. How would that happen? Financial manager could ask database administrator to query some merchant’s transactions and put this data in .csv file. After that he could calculate customer bills manually.Another analogy is Composite UI approach. Imagine you are a Sales manager. You can set payment accounts, tariffs, change some settings and once a month you have to manually calculate their bills. So you have a web application that should allow you to view and modify data that belongs to different services. Payment account and transactions belong to Payment processing service, tariffs belong to Customer billing service and transaction’s reconciliation info belongs to Reconciliation service. In order to calculate customer bills, you might need not just viewing transactions capability but exporting all transactions as, say, a .csv file. That’s how this web application basically looks like:
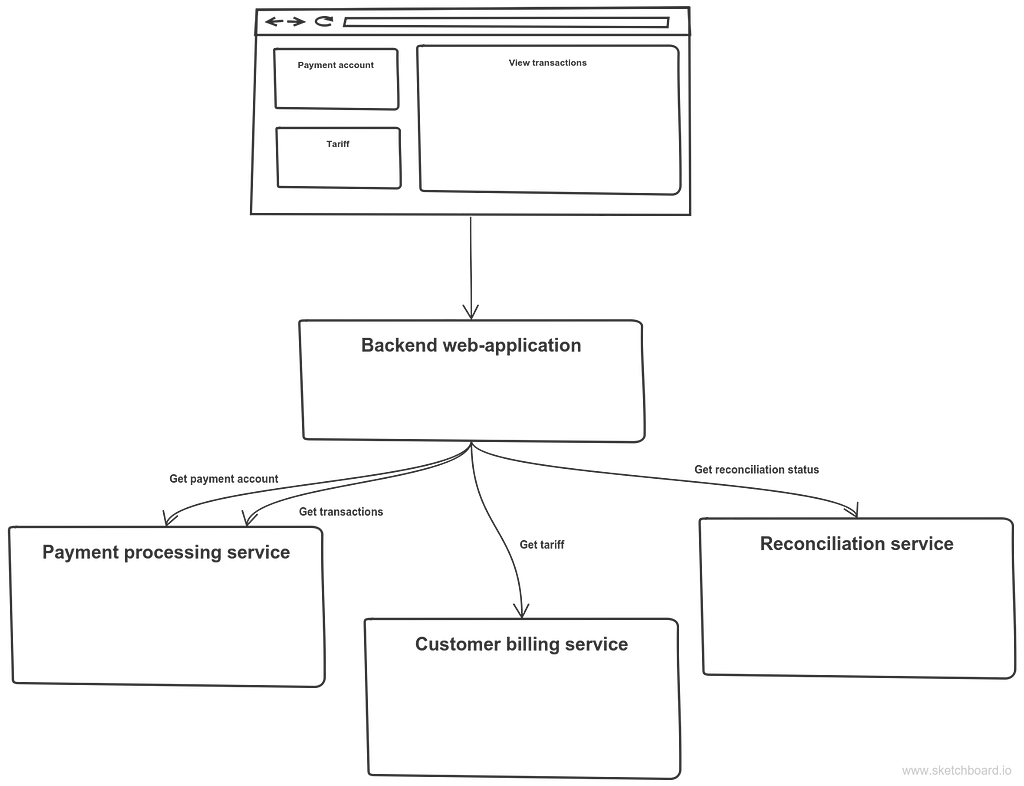 Composite UI for sales manager
Composite UI for sales manager
There is nothing wrong in viewing transactions. That’s how UI in microservice architecture works. And there is also nothing wrong in letting software do the tedious job for you.
Putting it all togetherSo the full cycle with higher-level messages could look like that:
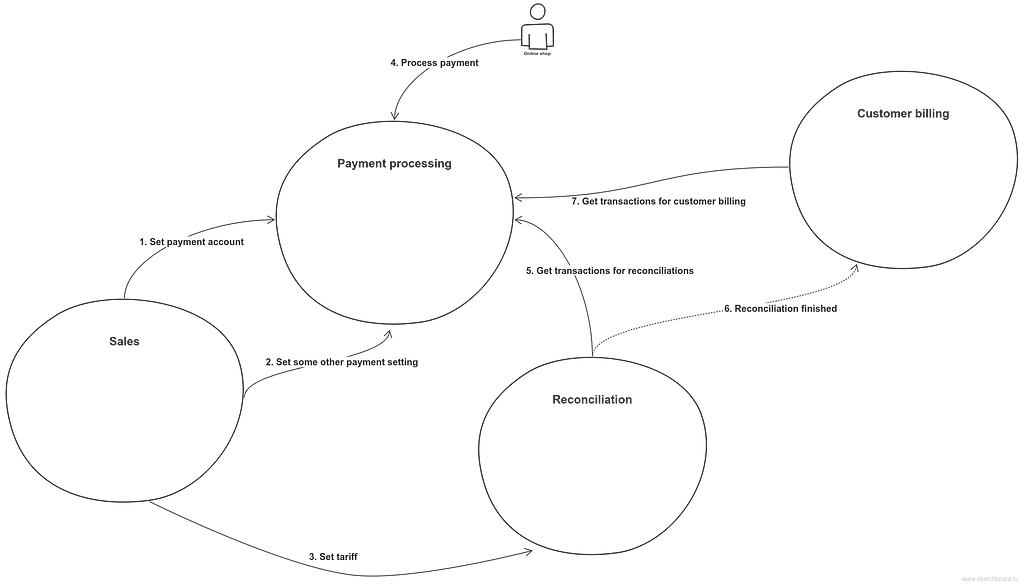 Higher-level services interaction
Higher-level services interaction
So I’m finally done with my service boundary identification example. I’ve touched not just boundary identification topic but scalability issues, domain designing (which can result in immutable model, but more about that in the next posts), composite UI and data ownership issues, specifically that you shouldn’t use CQRS as your higher-level pattern.
Hope you liked it.
Upd.: Check out the second example here.
Example of Service Boundaries Identification was originally published in Hacker Noon on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.