Latest news about Bitcoin and all cryptocurrencies. Your daily crypto news habit.
The peer-to-peer layer enables secure, reliable, and scalable communication between subnet nodes on the Internet Computer.
By Yotam Harchol, Research Scientist (Networking) | DFINITY

The Internet Computer blockchain empowers developers to build consumer-facing dapps entirely on-chain using canister smart contracts, making it possible to reimagine web services, DeFi platforms, social media, NFTs, games, and much more. The Internet Computer is therefore designed to be secure, reliable, and scalable.
Scalability is a very important factor, which mainly relies on the efficiency of message distribution in the network. The bigger the network, more messages must be distributed. For this reason, the Internet Computer network is divided into subnets. Each subnet can be seen as smaller Internet Computer blockchains that run canisters on a selection of nodes. The peer-to-peer layer is the one that enables secure, reliable, and scalable communication between nodes of the same subnet.
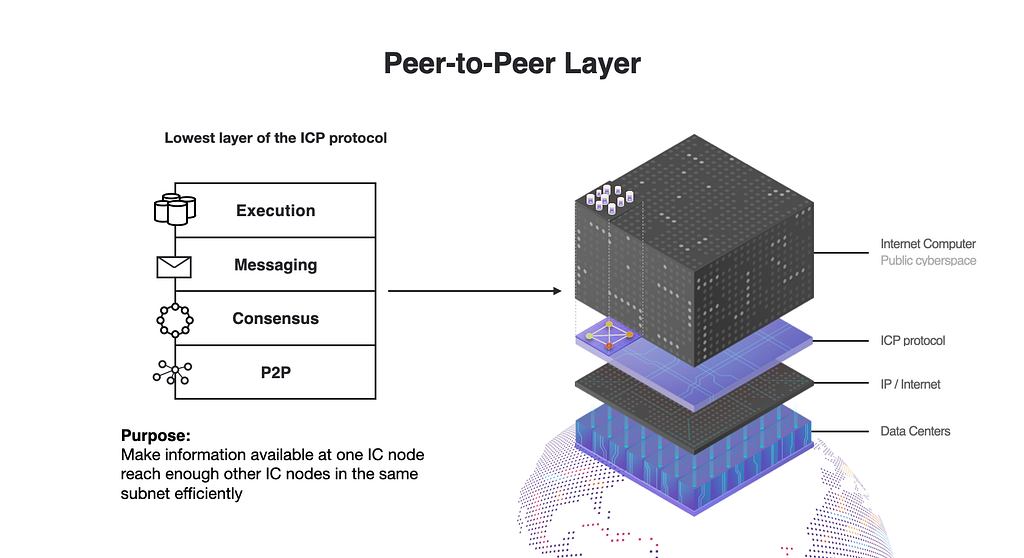
The Internet Computer protocol has four major layers:
- Execution manages a safe environment for deterministic execution of software messages
- Message routing routes user and system-generated messages between subnets, manages the input and output queues for applications, and schedules messages for execution.
- Consensus selects and sequences messages received from users and from different subnets to create input blocks that can be notarized and finalized before being delivered to the message routing layer.
- Peer-to-peer (“P2P”) collects and advertises messages from users, as well as from other nodes in the same subnet blockchain. Messages received by the peer-to-peer layer are disseminated to the other nodes in the subnet to ensure the security, reliability, and resiliency of the platform.
The three main challenges of the peer-to-peer layer of the Internet Computer are security, performance, and scalability. The Internet Computer is designed to be secured even against malicious nodes, and so its peer-to-peer layer and protocol are designed to keep operating even in the presence of such malicious nodes (up to 1/3 of the subnet). This is different from other conventional peer-to-peer designs, and it adds complexity and performance tradeoffs that I will discuss below. The peer-to-peer layer achieves the security goals with minimal performance overhead, while still enabling subnets to scale.
In addition, the Internet Computer’s peer-to-peer layer provides a unique prioritization mechanism for messages. This enables faster delivery of important messages and saves bandwidth by not sending unwanted messages.
In this blog post, I’ll touch on the following aspects of the peer-to-peer layer of the Internet Computer:
- Requirements
- Basic principles
- Interaction with application components
- Data structures
- Gossip protocol
- Bandwidth and memory considerations
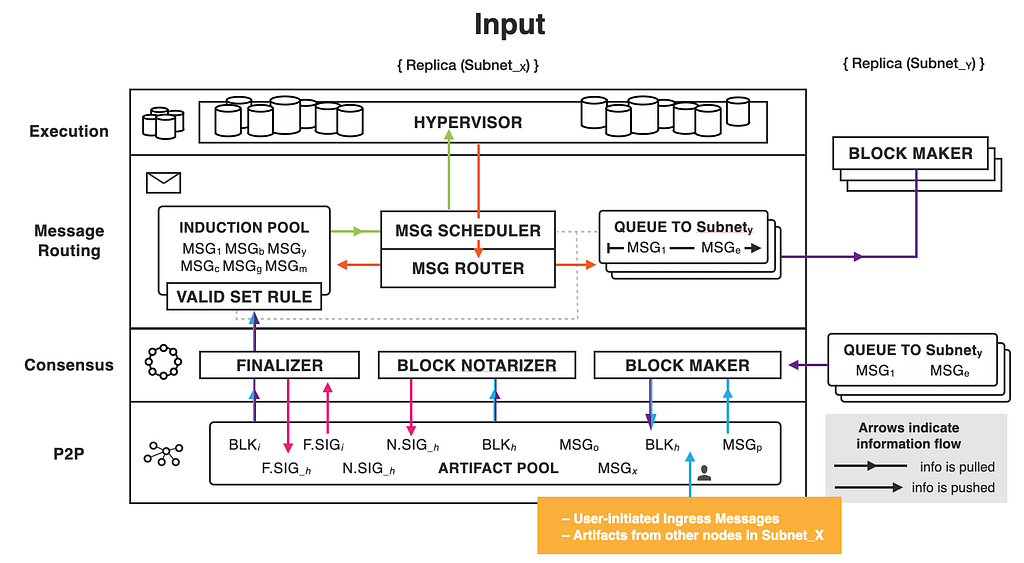
The peer-to-peer layer is responsible for sending out artifacts created by the layers above (e.g., Consensus) and for receiving, validating, processing, and distributing artifacts arriving from other nodes in the same subnet, as well as from users. The peer-to-peer layer guarantees that if a correct node sends an artifact to its peers, then that artifact will eventually be received by all correct nodes in the subnet which need it. This can be viewed as a special case of reliable broadcast, tailored for our consensus algorithm with prioritization. Under some network assumptions, it provides bounded-time delivery.
We would like our peer-to-peer layer to provide that guarantee under the following requirements:
- Bounded-time/eventual delivery despite Byzantine faults
- Reserved resources for different application components/peers
- Bounded resources
- Prioritization for different artifacts
- High efficiency
- DOS/SPAM resilience
- Encryption, authenticity, and integrity
Peer-to-peer uses a gossip mechanism to distribute messages in the subnet. The principle of a gossip protocol is to send messages that you’ve received or messages you created to your peers in the subnet, in a process that is analogous to the spreading of rumors. The peers in peer-to-peer are determined by an overlay network topology. Everything is guaranteed to be delivered in the O(diameter) hops, if the overlay is undirected and connected, all nodes follow the protocol, and no messages are dropped.
The peer-to-peer layer is designed to be fault-tolerant even in the presence of Byzantine nodes. We consider a node to be “Byzantine” if it behaves maliciously (e.g., does not follow the protocol, tries to harm other nodes or users), or if it exhibits some faulty behavior (e.g., does not respond, does not distribute artifacts, suffers from severe network delays). The design of the peer-to-peer layer therefore takes into account the possibility of having such nodes in a subnet, and guarantees a correct and efficient operation even if up to one third of the nodes in a subnet are Byzantine.
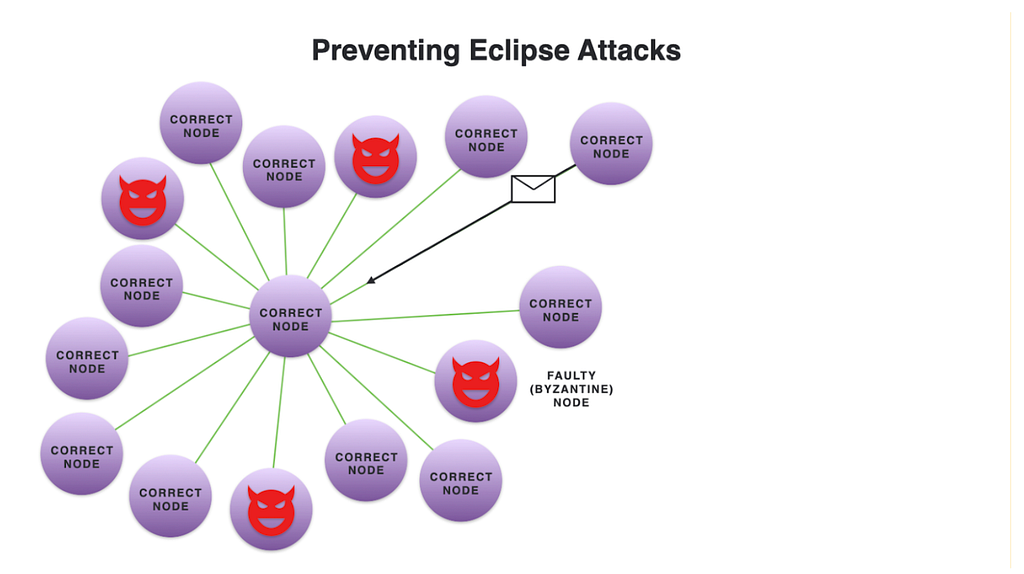
There are several problems we would like to avoid when considering Byzantine nodes. The first is what is known as the eclipse attack, where all peers of a certain node happen to be malicious or faulty. The malicious nodes can collude and select which artifacts the correct node sees and disconnect that node from the rest of the network. Because we validate the authenticity of messages, malicious nodes cannot trick honest nodes with spoofed messages, but the connectivity problem remains. To avoid that, we must use overlays that guarantee connectivity with enough peers, so that all honest nodes form a connection with very high probability. For small enough subnets, a node can connect to all other nodes in the subnet, forming a complete graph and thus providing perfect protection against eclipse attacks. For larger subnets such as the Network Nervous System (NNS), we will use sparser overlays.
Because we would like to guarantee that artifacts are received by all nodes who rely on them within a certain time, the gossip protocol needs to make sure that these artifacts are delivered, despite the possible problems of faulty links and nodes. Gossip protocols are often based on dissemination patterns resulting in redundancy and waste of bandwidth. It is therefore important to design such protocols in a way that reduces these overheads.
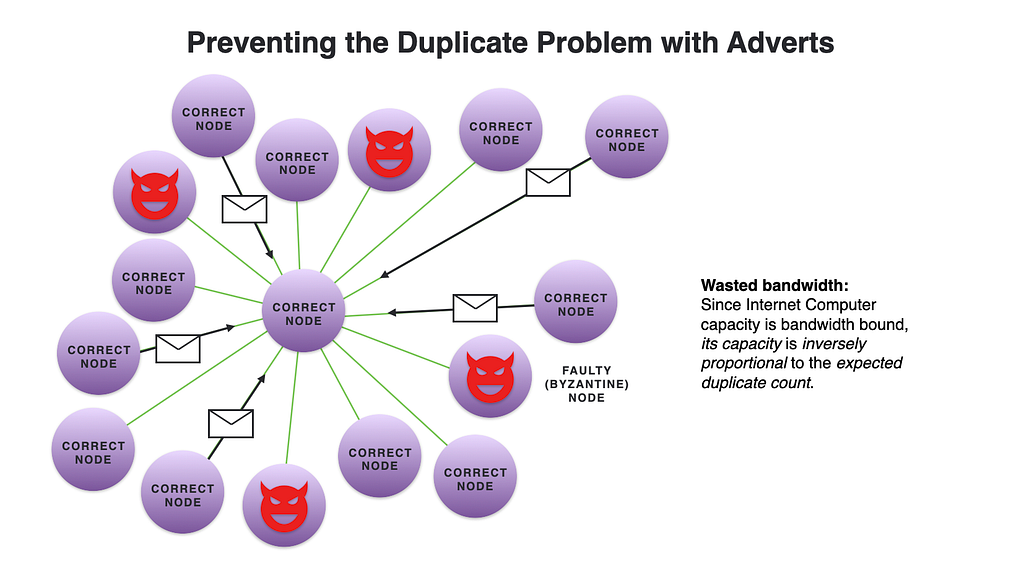
Artifacts can be large, and if these are sent multiple times from multiple peers, it causes a severe bandwidth waste. This is analogous to having to hear the same rumor over and over again from multiple friends. In this analogy, instead of just telling you the rumor again, your friend could start by asking you if you have heard the latest news. In our context, this corresponds to adverts that are sent first. Adverts are small messages that contain only meta-data of artifacts and some means to validate them, but not their content. Each node then requests an artifact it needs from at least one peer. In our design, we start by asking one peer, but if we encounter a problem, we may ask another peer for the same artifact, and this might repeat until we find an honest peer that is not faulty.
An advert includes fields that are used by the gossip protocol and its application components for integrity verification (e.g., an integrity hash) and for decision-making (e.g., attributes that help the components to prioritize artifacts).
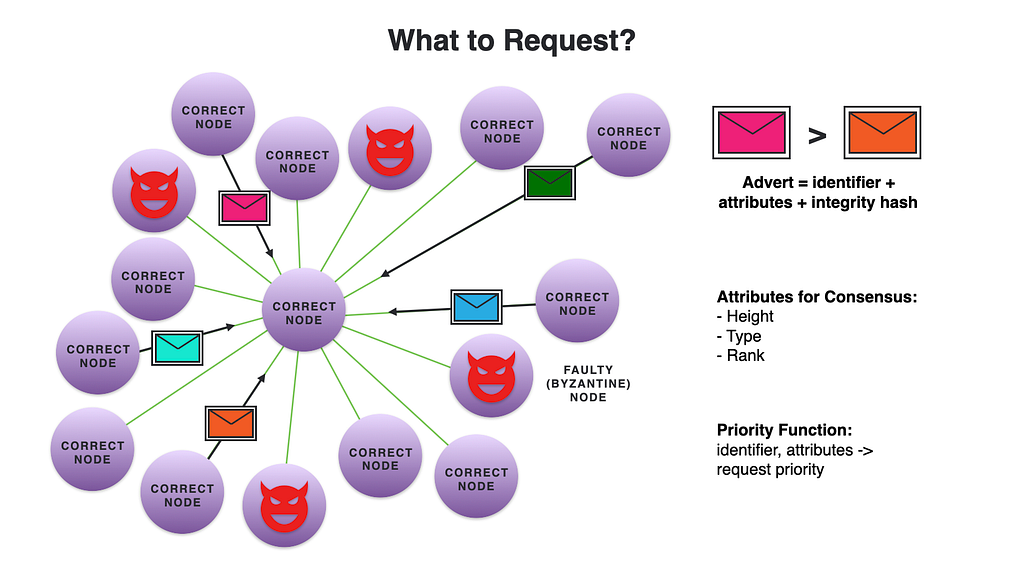
A node may receive multiple adverts and therefore may have to choose what artifacts to request first. Each advert contains some attributes that are provided by the client component that created it. For example, consensus artifacts contain a height attribute which tells the block height of the corresponding artifact. Consensus also provides gossip with a priority function, which takes an advert (with its attributes) and returns a priority value (the lowest being “drop”, which means this artifact is not needed, and the highest being “fetch now”, which means a top priority artifact). For example, if consensus is at Height 10 now, it may prefer artifacts for that height than those for Height 11 or 12, depending on their type as well and possibly other state parameters (As a general rule, it prefers the same height over different heights). Peer-to-peer uses these priority values to determine which artifact should be requested first.
Peer-to-peer stores received artifacts in the artifact pool. It informs consensus and the other client components about changes in the pool, and then the application component determines its next action with regard to the content of the pool. The artifact pool contains all available artifacts for each application component.
We categorize artifacts as “validated” or “unvalidated.” The latter class is for those artifacts that have not yet been validated. Validation means checking the artifacts by the client component, for example, by verifying signatures. The artifact pool of a client can be persisted to non-volatile storage if needed. We do this for consensus artifacts.
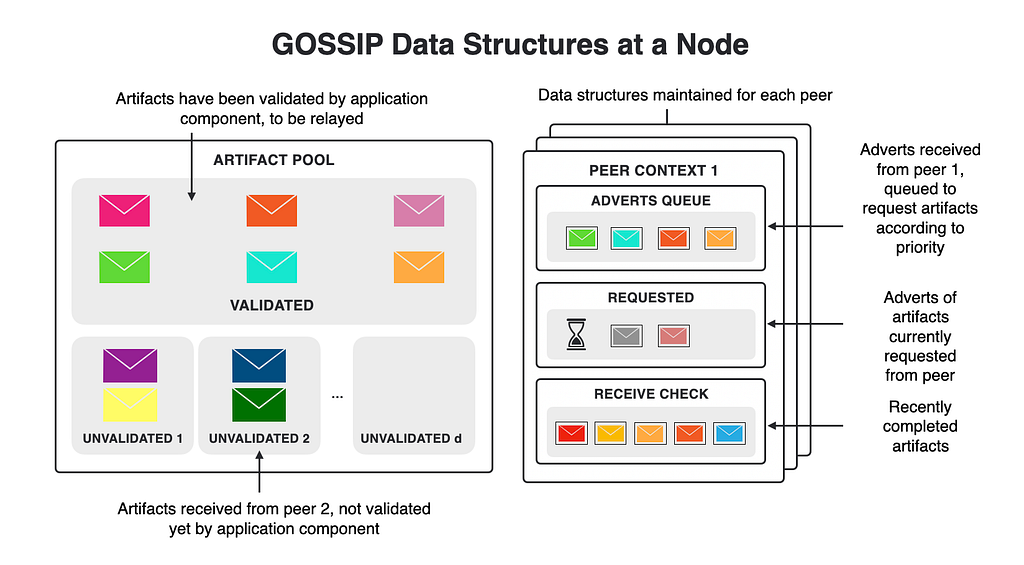
Above we can see what data structures a node holds for the gossip protocol. On the left is the artifact pool, which is separated into validated and unvalidated sections. Unvalidated sections hold those artifacts that were not yet validated. The size of each unvalidated section is bounded to prevent bad peers from filling up the artifact pool and thus cause resource leaks and denial-of-service attacks, but is large enough to ensure correct operation of the protocol during normal circumstances.
Additionally, for each peer, we maintain its context, which helps us track which adverts we received, which adverts we requested from whom, etc:
- The advert queue is a priority queue of all adverts received from this peer. They are ordered by their priority.
- The requested set contains all adverts for which the corresponding artifacts had already been requested from this peer.
- The receive check cache is used to prevent requests for artifacts that were recently received.
These are the main events that the gossip protocol handles:
- New artifact in the pool (added locally by a client component)
- Processing of a new advert received from a peer
- Processing of a new artifact received from a peer
- Recovery and reconnection issues
New artifact in the pool (added locally by a client component):
When a node receives a new artifact from a client component, it creates an advert for it, and sends this adverts to all its peers.
Processing of a new advert received from a peer:
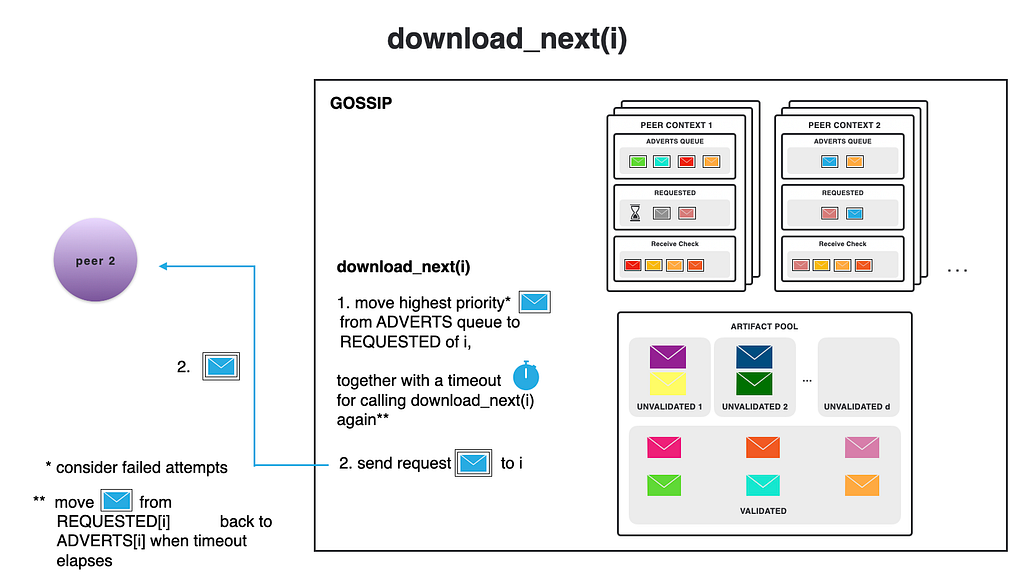
When a node receives an advert from a peer, it first checks whether the corresponding artifact was already downloaded or created by the node itself. If not, and the priority for this advert is higher than “drop”, it adds the advert to the adverts queue of the peer that sent it. If there is enough space for the peer in the unvalidated section of the artifact pool, we call a function called download_next(i) specifically for this peer i. This function fetches the top priority advert (based on the priorities assigned by the priority functions), and requests the corresponding artifact from that peer. Thus, it is not necessary that we request the artifact for which we just received an advert; we will just request the artifacts with the highest priority.
After requesting the artifact, the corresponding advert is moved from the adverts queue to the requested set of the peer from whom we are requesting the artifact.
We may have the same advert in the adverts queue of multiple peers, as multiple peers may have sent the same advert to us. The adverts will remain in the adverts queue of the other peers until we receive the actual artifact. A timeout is set on the artifact request, to protect against unresponsive or slow peers. This helps guarantee bounded time delivery. We will avoid requesting an artifact from a peer we already made a request to, as it may be misbehaving. In this case, we see whether other peers have advertised this same artifact, and if so, we’ll try to fetch it from them before we try the unresponsive peer.
Processing of a new artifact received from a peer:
When we receive an artifact from a peer, we first make sure that it was requested by checking that the corresponding advert is in the peer’s requested set. We then verify its integrity using the corresponding integrity hash. if any of these checks fail, it means this peer is misbehaving. Eventually, we remove the advert from all the advert queues and requested sets.We add the artifact to the unvalidated pool of the peer who sent it. We’ll leave it there for the client component to check and validate it. We also add a hash of the artifact to a small cache called received check, maintained per peer, to ignore further adverts for the same artifact. This is done to provide some grace period for the application component to update their priority function, so that they do not request the same advert again even if the artifact is removed from the unvalidated part of the pool. If we still have space for this peer in the unvalidated artifact pool, we request the next artifact from it, according to priority using the download_next(i) function.
Transport and Connection Management
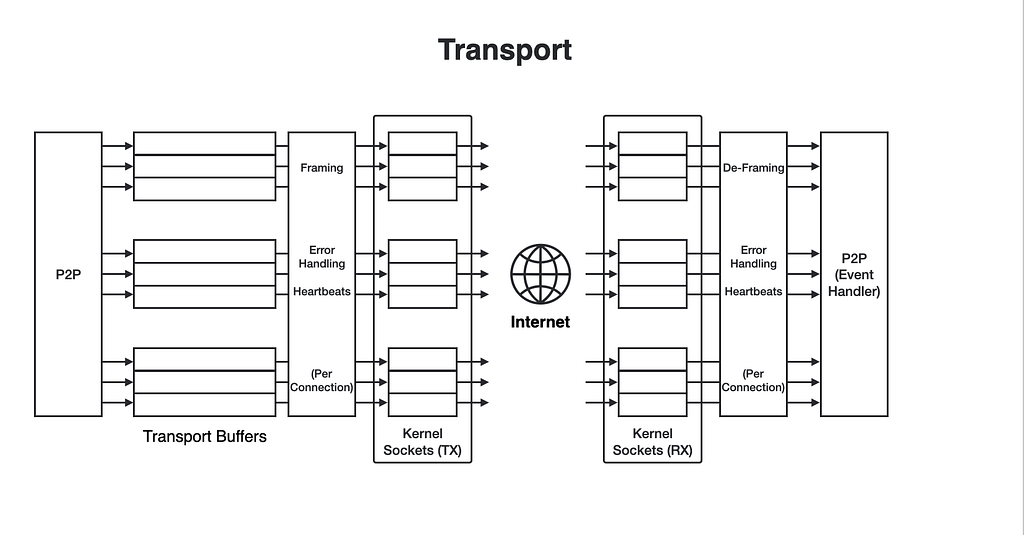
Below the gossip component, there is a transport component that maintains the actual network connections between peers. The transport component is responsible for trying to keep the connection stable. It has its own buffers for cases of transient connectivity problems and congestion. It has an internal mechanism to ensure that connections do not hang and to detect longer-than-usual delays. This is important for providing a bounded time delivery. Transport frames gossip messages with its own layer 7 header, that contains a few metadata fields used by the transport component to maintain the flows and to report errors. Currently, transport uses multiple TCP streams between peers.
Transport uses TLS 1.3 in a way that is adapted to such a decentralized peer-to-peer network, with no certificate authority hierarchy as the root of trust. Instead, the root of trust is the registry that provides self-signed certificates for nodes so they can authenticate their peers.
In case a TCP connection is interrupted, Transport periodically tries to reconnect (as long as the corresponding peer is still on the node’s assigned overlay). When a connection is reestablished, we drain the corresponding transport queues and can start admitting new messages.
Since all data structures are bounded in size, this applies to transport buffers as well. In case such a buffer becomes full, or if we’ve been waiting for a reconnection, transport eventually notifies the receiver gossip component of a potential message drop. The receiver can then send a retransmission request. A retransmission request is a message of the gossip protocol that has a filter to tell the receiver the latest artifacts the sender of the request has seen. It might be that other peers already successfully sent the same advert by the time this request is sent, so it might be that the node does not need to catch up with the corresponding peer on all the messages it missed from it.
Upon receiving retransmission requests, the sender node sends all of the relevant adverts according to the filter that is included with the request. Transport sends these adverts to the receiver. If the queue becomes full again during this process, another retransmission request for the remaining adverts will be sent.
To summarize, the peer-to-peer layer guarantees bounded time delivery of artifacts in a subnet. It uses an advert-request-artifact pattern and overlay topologies to reduce bandwidth overhead, and it offers a prioritization API to client components to ensure that the highest priority artifacts are delivered first. The protocol is designed to be fault-tolerant and takes into account denial-of-service attacks and other threats.
____
Start building at smartcontracts.org and join our developer community at forum.dfinity.org.
Secure Scalability: The Internet Computer’s Peer-to-Peer Layer was originally published in The Internet Computer Review on Medium, where people are continuing the conversation by highlighting and responding to this story.
Publication date
Disclaimer
The views and opinions expressed in this article are solely those of the authors and do not reflect the views of Bitcoin Insider. Every investment and trading move involves risk - this is especially true for cryptocurrencies given their volatility. We strongly advise our readers to conduct their own research when making a decision.